Python'da tek değişkenli analiz nasıl gerçekleştirilir: örneklerle
Tek değişkenli analiz terimi, bir değişkenin analizini ifade eder. Bunu “uni” ön ekinin “bir” anlamına gelmesinden dolayı hatırlayabilirsiniz.
Bir değişken üzerinde tek değişkenli analiz gerçekleştirmenin üç yaygın yolu vardır:
1. Özet İstatistikler – Değerlerin merkezini ve dağılımını ölçer.
2. Frekans Tablosu – Farklı değerlerin ne sıklıkla ortaya çıktığını açıklar.
3. Grafikler – Değerlerin dağılımını görselleştirmek için kullanılır.
Bu eğitimde aşağıdaki pandalar DataFrame ile tek değişkenli analizin nasıl gerçekleştirileceğine ilişkin bir örnek sunulmaktadır:
import pandas as pd #createDataFrame df = pd. DataFrame ({' points ': [1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2], ' assists ': [5, 7, 7, 9, 12, 9, 9, 4, 6, 8, 8, 9, 3, 2, 6], ' rebounds ': [11, 8, 10, 6, 6, 5, 9, 12, 6, 6, 7, 8, 7, 9, 15]}) #view first five rows of DataFrame df. head () points assists rebounds 0 1.0 5 11 1 1.0 7 8 2 2.0 7 10 3 3.5 9 6 4 4.0 12 6
1. Özet istatistikleri hesaplayın
DataFrame’deki “puan” değişkenine ilişkin çeşitli özet istatistikleri hesaplamak için aşağıdaki sözdizimini kullanabiliriz:
#calculate mean of 'points' df[' points ']. mean () 5.706666666666667 #calculate median of 'points' df[' points ']. median () 5.0 #calculate standard deviation of 'points' df[' points ']. std () 3.858287308169384
2. Frekans tablosu oluşturun
‘Noktalar’ değişkeni için bir frekans tablosu oluşturmak amacıyla aşağıdaki sözdizimini kullanabiliriz:
#create frequency table for 'points' df[' points ']. value_counts () 4.0 3 1.0 2 5.0 2 2.0 1 3.5 1 6.5 1 7.0 1 7.4 1 8.0 1 13.0 1 14.2 1 Name: points, dtype: int64
Bu bize şunu söylüyor:
- 4 değeri 3 kez görünüyor
- 1 değeri iki kez görünüyor
- 5 değeri iki kez görünüyor
- 2 değeri 1 kez görünüyor
Ve benzeri.
İlgili: Python’da Frekans Tabloları Nasıl Oluşturulur
3. Grafikler Oluşturun
‘Noktalar’ değişkeni için bir kutu grafiği oluşturmak amacıyla aşağıdaki sözdizimini kullanabiliriz:
import matplotlib. pyplot as plt df. boxplot (column=[' points '], grid= False , color=' black ')
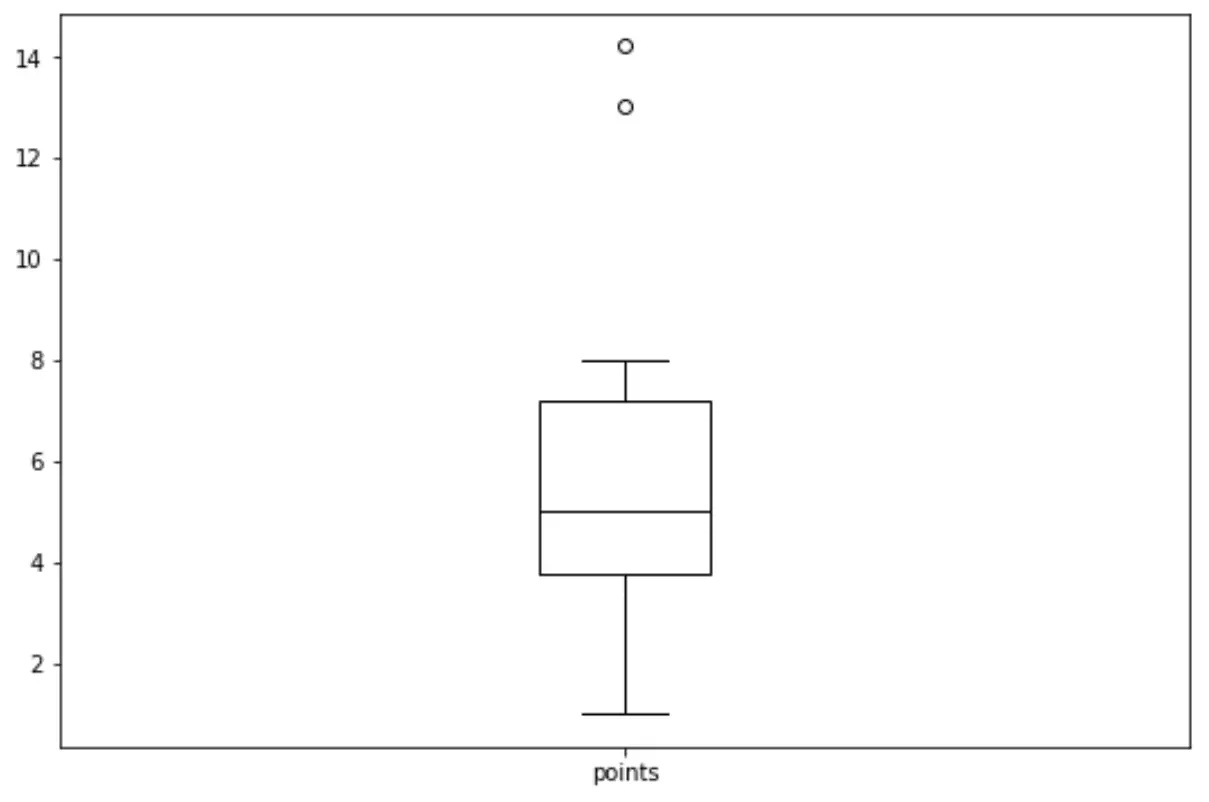
İlgili: Pandas DataFrame’den Kutu Grafiği Nasıl Oluşturulur
‘Noktalar’ değişkeni için bir histogram oluşturmak amacıyla aşağıdaki sözdizimini kullanabiliriz:
import matplotlib. pyplot as plt df. hist (column=' points ', grid= False , edgecolor=' black ')
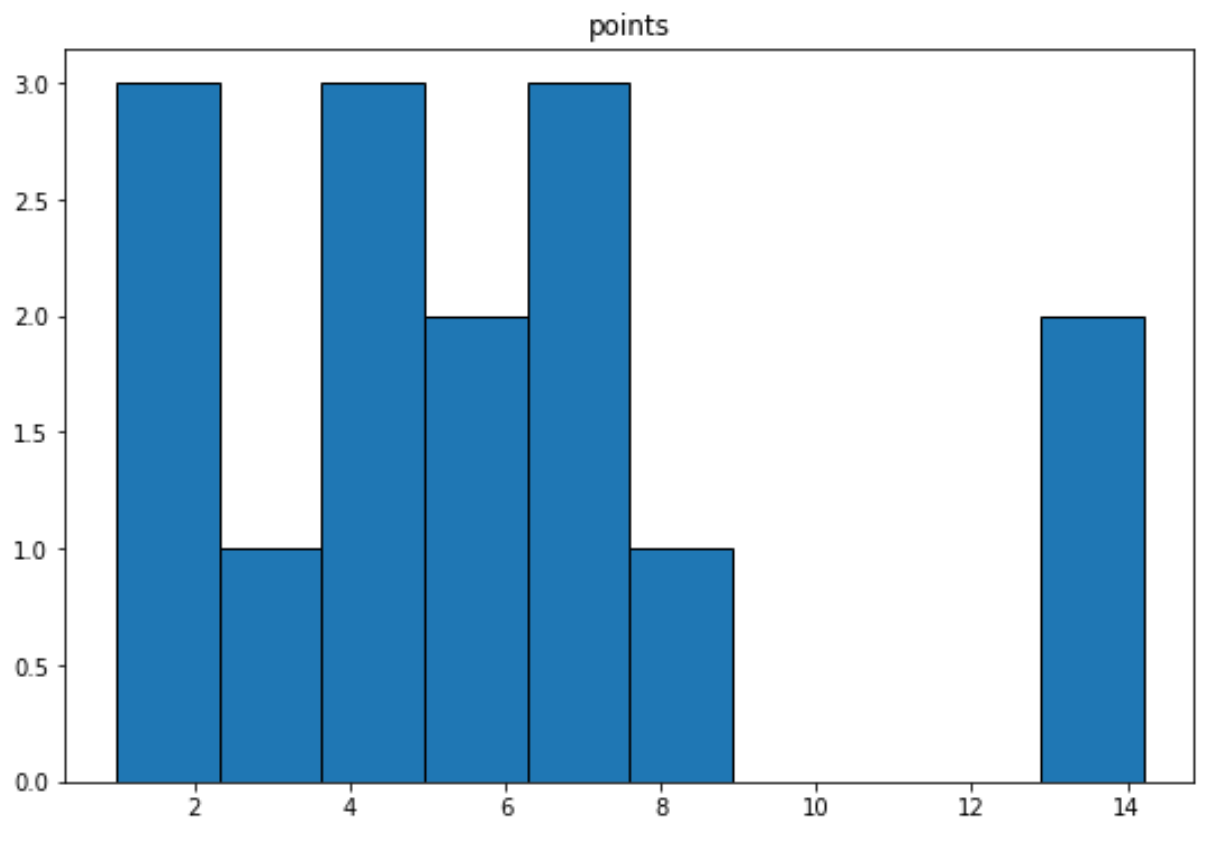
İlgili: Pandas DataFrame’den Histogram Nasıl Oluşturulur
“Noktalar” değişkeni için bir yoğunluk eğrisi oluşturmak amacıyla aşağıdaki sözdizimini kullanabiliriz:
import seaborn as sns sns. kdeplot (df[' points '])
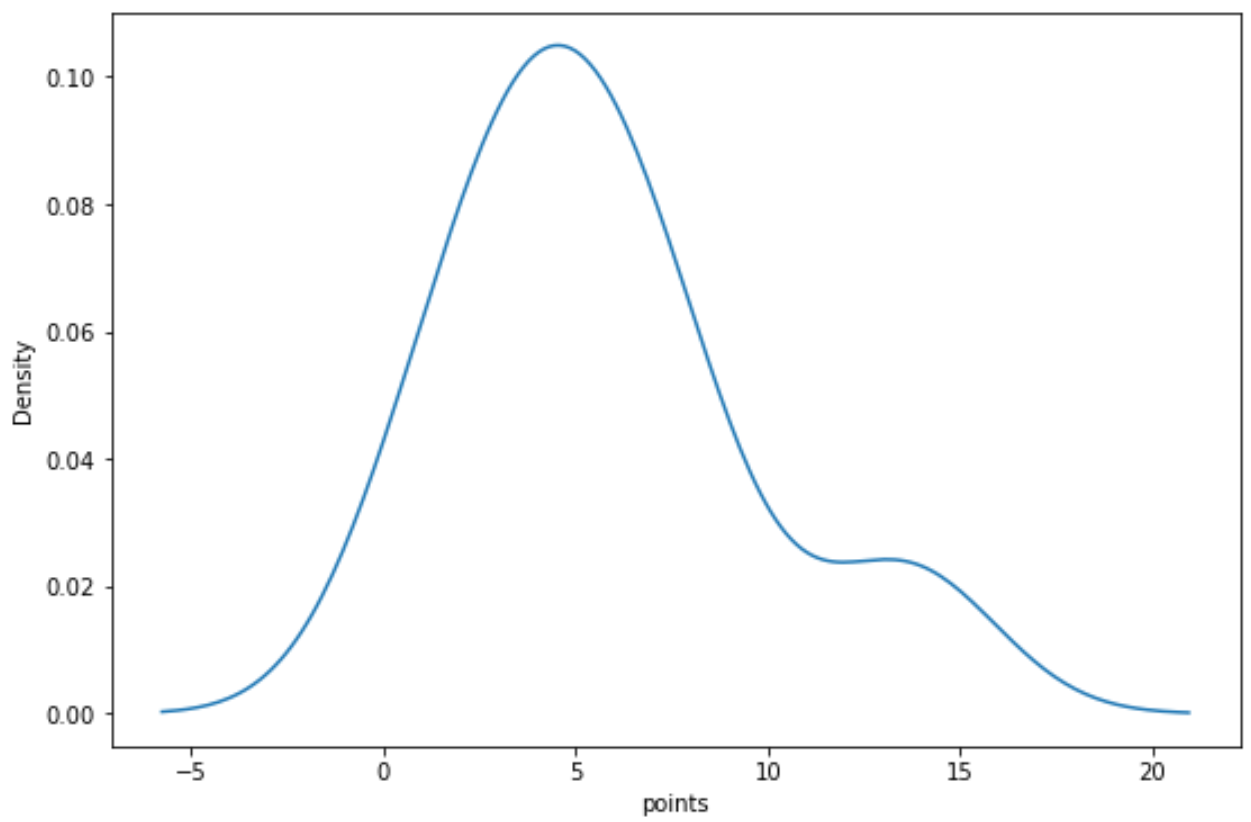
İlgili: Matplotlib’de Yoğunluk Grafiği Nasıl Oluşturulur
Bu grafiklerin her biri bize “puan” değişkeninin değerlerinin dağılımını görselleştirmenin benzersiz bir yolunu sunar.
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil