Veri çerçevesi sütunu r'de dizin olarak nasıl ayarlanır (örnekle)
R’deki veri çerçeveleri, pandalardaki veri çerçeveleri gibi bir “indeks” sütununa sahip değildir.
Ancak R’deki veri çerçeveleri, dizin sütunuyla aynı işlevi gören satır adlarına sahiptir.
Mevcut bir veri çerçevesi sütununu R’deki bir veri çerçevesi için satır adları olarak ayarlamak için aşağıdaki yöntemlerden herhangi birini kullanabilirsiniz:
Yöntem 1: R Tabanını Kullanarak Satır Adlarını Ayarlama
#set specific column as row names rownames(df) <- df$my_column #remove original column from data frame df$my_column <- NULL
Yöntem 2: Tidyverse paketini kullanarak satır adlarını ayarlama
library (tidyverse) #set specific column as row names df <- df %>% column_to_rownames(., var = ' my_column ')
Yöntem 3: Verileri İçeri Aktarırken Satır Adlarını Ayarlama
#import CSV file and specify column to use as row names df <- read. csv (' my_data.csv ', row.names =' my_column ')
Aşağıdaki örnekler her yöntemin pratikte nasıl kullanılacağını göstermektedir.
Örnek 1: Base R’yi kullanarak satır adlarını tanımlama
R’de aşağıdaki veri çerçevesine sahip olduğumuzu varsayalım:
#create data frame
df <- data. frame (ID=c(101, 102, 103, 104, 105),
points=c(99, 90, 86, 88, 95),
assists=c(33, 28, 31, 39, 34),
rebounds=c(30, 28, 24, 24, 28))
#view data frame
df
ID points assists rebounds
1 101 99 33 30
2 102 90 28 28
3 103 86 31 24
4 104 88 39 24
5 105 95 34 28
ID sütununu satır adı olarak ayarlamak için aşağıdaki kodu kullanabiliriz:
#set ID column as row names
rownames(df) <- df$ID
#remove original ID column from data frame
df$ID <- NULL
#view updated data frame
df
points assists rebounds
101 99 33 30
102 90 28 28
103 86 31 24
104 88 39 24
105 95 34 28
Kimlik sütunundaki değerler artık veri çerçevesinin satır adlarıdır.
Örnek 2: Tidyverse paketini kullanarak satır adlarını ayarlama
Aşağıdaki kod, satır adlarını veri çerçevesindeki kimlik sütununa eşitlemek için Spiceverse paketinin sütun_to_rownames() işlevinin nasıl kullanılacağını gösterir:
library (tidyverse)
#create data frame
df <- data. frame (ID=c(101, 102, 103, 104, 105),
points=c(99, 90, 86, 88, 95),
assists=c(33, 28, 31, 39, 34),
rebounds=c(30, 28, 24, 24, 28))
#set ID column as row names
df <- df %>% column_to_rownames(., var = ' ID ')
#view updated data frame
df
points assists rebounds
101 99 33 30
102 90 28 28
103 86 31 24
104 88 39 24
105 95 34 28
Bu sonucun önceki örnekle eşleştiğini unutmayın.
Örnek 3: Verileri içe aktarırken satır adlarını ayarlayın
Diyelim ki my_data.csv adında aşağıdaki CSV dosyamız var:
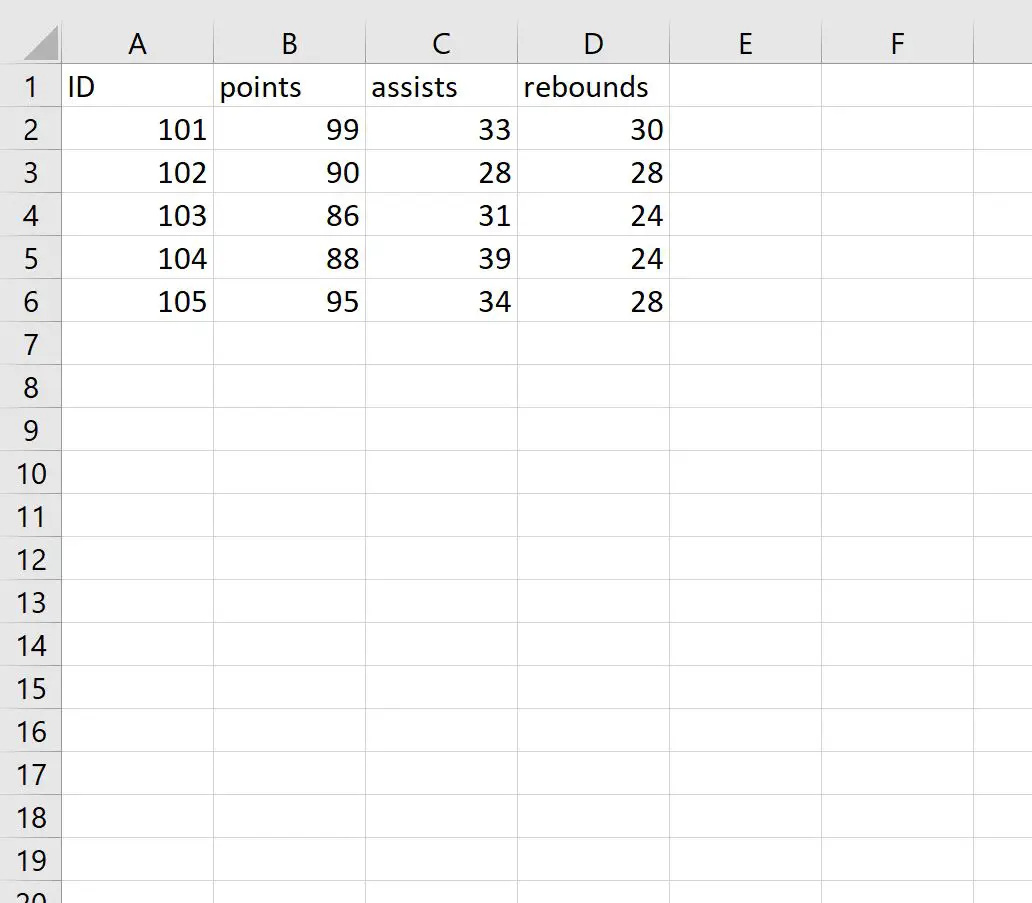
CSV dosyasını içe aktarmak ve içe aktarma sırasında satır adlarını kimlik sütununa eşit olacak şekilde ayarlamak için aşağıdaki kodu kullanabiliriz:
#import CSV file and specify ID column to use as row names df <- read. csv (' my_data.csv ', row.names =' ID ') #view data frame df points assists rebounds 101 99 33 30 102 90 28 28 103 86 31 24 104 88 39 24 105 95 34 28
Kimlik sütunundaki değerlerin veri çerçevesinde satır adı olarak kullanıldığına dikkat edin.
Ek kaynaklar
Aşağıdaki eğitimlerde R’de diğer ortak görevlerin nasıl gerçekleştirileceği açıklanmaktadır:
Koşula bağlı olarak R’deki veri çerçevesinden satırlar nasıl kaldırılır
R’de veri çerçevesindeki değerler nasıl değiştirilir?
R’deki veri çerçevesinden sütunlar nasıl kaldırılır
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil