R'de rastgele ormanlar nasıl oluşturulur (adım adım)
Bir dizi yordayıcı değişken ile bir yanıt değişkeni arasındaki ilişki çok karmaşık olduğunda, aralarındaki ilişkiyi modellemek için genellikle doğrusal olmayan yöntemler kullanırız.
Bu yöntemlerden biri de karar ağacı oluşturmaktır. Bununla birlikte, tek bir karar ağacı kullanmanın dezavantajı, yüksek varyanslara maruz kalma eğiliminde olmasıdır.
Yani veri setini ikiye bölüp karar ağacını her iki yarıya da uygularsak sonuçlar çok farklı olabilir.
Tek bir karar ağacının varyansını azaltmak için kullanabileceğimiz yöntemlerden biri, aşağıdaki gibi çalışan bir rastgele orman modeli oluşturmaktır:
1. Orijinal veri kümesinden b önyüklemeli örnek alın.
2. Her önyükleme örneği için bir karar ağacı oluşturun.
- Ağacı oluştururken, her bölünme dikkate alındığında, p öngörücülerin tam kümesinden yalnızca rastgele bir m yordayıcı örneği bölünmeye aday olarak kabul edilir. Genellikle m’yi √p’ye eşit olarak seçeriz.
3. Nihai bir model elde etmek için her ağaçtan elde edilen tahminlerin ortalamasını alın.
Rastgele ormanların, tek karar ağaçlarından ve hatta torbalanmış modellerden çok daha doğru modeller üretme eğiliminde olduğu ortaya çıktı.
Bu öğretici, R’deki bir veri kümesi için rastgele orman modelinin nasıl oluşturulacağına ilişkin adım adım bir örnek sağlar.
Adım 1: Gerekli paketleri yükleyin
Öncelikle bu örnek için gerekli paketleri yükleyeceğiz. Bu basit örnek için yalnızca bir pakete ihtiyacımız var:
library (randomForest)
Adım 2: Rastgele Orman Modelini Ayarlayın
Bu örnek için, New York City’deki 153 ayrı gün boyunca hava kalitesi ölçümlerini içeren, Hava Kalitesi adı verilen yerleşik bir R veri kümesini kullanacağız.
#view structure of air quality dataset str(airquality) 'data.frame': 153 obs. of 6 variables: $ Ozone: int 41 36 12 18 NA 28 23 19 8 NA ... $Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ... $ Wind: num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ... $ Temp: int 67 72 74 62 56 66 65 59 61 69 ... $Month: int 5 5 5 5 5 5 5 5 5 5 ... $Day: int 1 2 3 4 5 6 7 8 9 10 ... #find number of rows with missing values sum(! complete . cases (airquality)) [1] 42
Bu veri kümesinde eksik değerlerin bulunduğu 42 satır var. Bu nedenle, rastgele bir orman modeli yerleştirmeden önce, her sütundaki eksik değerleri sütun medyanlarıyla dolduracağız:
#replace NAs with column medians for (i in 1: ncol (air quality)) { airquality[,i][ is . na (airquality[, i])] <- median (airquality[, i], na . rm = TRUE ) }
İlgili: R’de eksik değerlerin nasıl atanacağı
Aşağıdaki kod, randomForest paketindeki randomForest() işlevini kullanarak rastgele bir orman modelinin R’ye nasıl sığdırılacağını gösterir.
#make this example reproducible set.seed(1) #fit the random forest model model <- randomForest( formula = Ozone ~ ., data = airquality ) #display fitted model model Call: randomForest(formula = Ozone ~ ., data = airquality) Type of random forest: regression Number of trees: 500 No. of variables tried at each split: 1 Mean of squared residuals: 327.0914 % Var explained: 61 #find number of trees that produce lowest test MSE which.min(model$mse) [1] 82 #find RMSE of best model sqrt(model$mse[ which . min (model$mse)]) [1] 17.64392
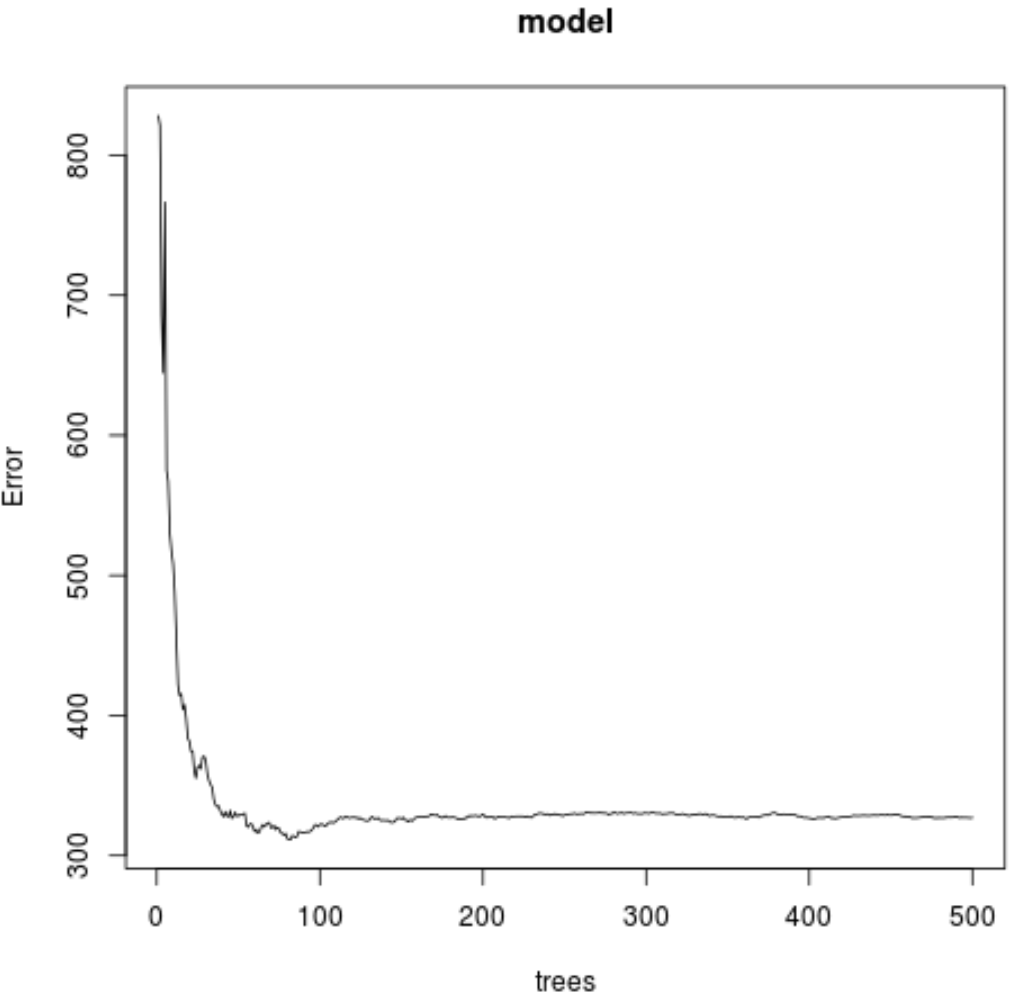
Sonuçtan, en düşük test ortalama kare hatasını (MSE) üreten modelin 82 ağaç kullandığını görebiliriz.
Bu modelin ortalama kare hatasının 17,64392 olduğunu da görebiliyoruz. Bunu ozon için tahmin edilen değer ile gözlenen gerçek değer arasındaki ortalama fark olarak düşünebiliriz.
Kullanılan ağaç sayısına göre MSE testinin bir grafiğini oluşturmak için aşağıdaki kodu da kullanabiliriz:
#plot the MSE test by number of trees
plot(model)
Ve son modeldeki her tahmin değişkeninin önemini gösteren bir çizim oluşturmak için varImpPlot() fonksiyonunu kullanabiliriz:
#produce variable importance plot
varImpPlot(model)
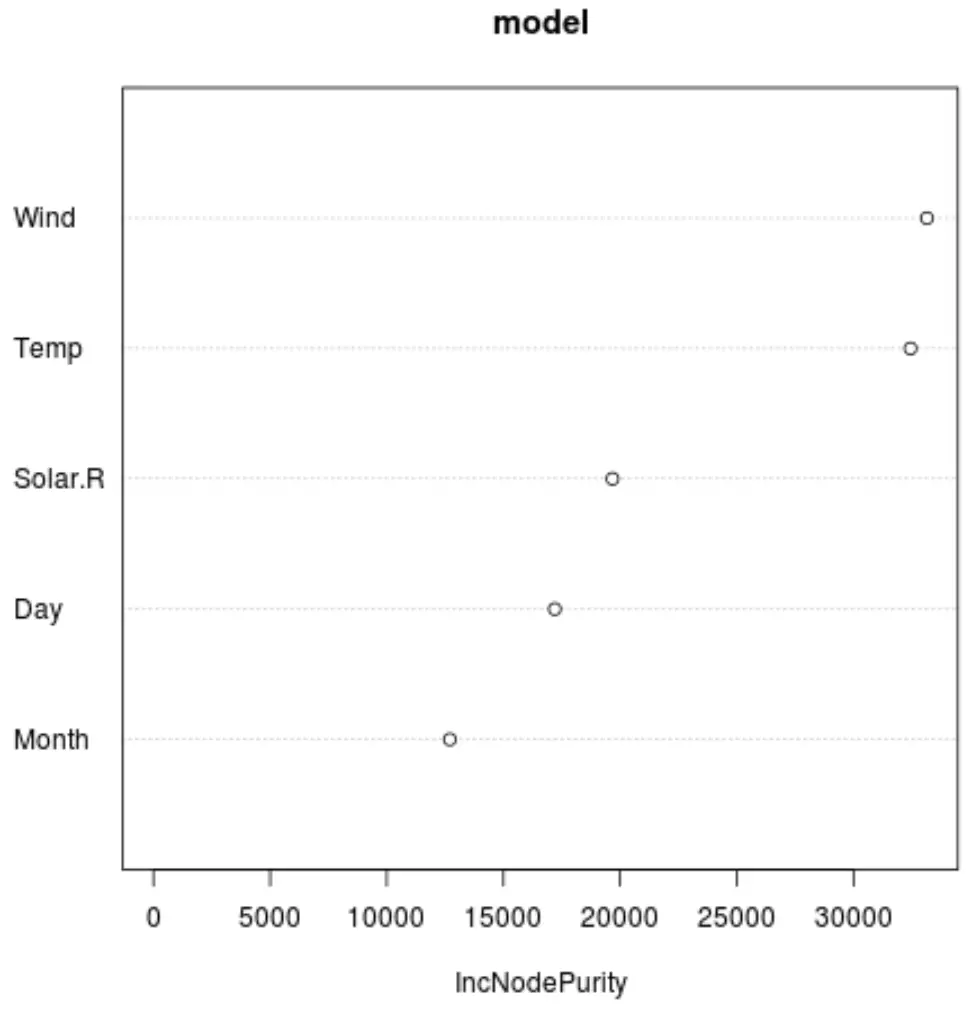
X ekseni, y ekseninde görüntülenen farklı tahmin edicilere bölünmenin bir fonksiyonu olarak regresyon ağaçlarının düğüm saflığında ortalama artışı görüntüler.
Grafikten Rüzgar’ın en önemli belirleyici değişken olduğunu ve onu yakından takip ettiğini görebiliyoruz.
3. Adım: Modeli ayarlayın
Varsayılan olarak, randomForest() işlevi, her bölünme için potansiyel adaylar olarak 500 ağaç ve (toplam tahminciler/3) rastgele seçilmiş tahminciler kullanır. TuneRF() fonksiyonunu kullanarak bu parametreleri ayarlayabiliriz.
Aşağıdaki kod, aşağıdaki özellikleri kullanarak en uygun modelin nasıl bulunacağını gösterir:
- ntreeTry: Oluşturulacak ağaç sayısı.
- mtryStart: her bölümde dikkate alınacak tahmin değişkenlerinin başlangıç sayısı.
- stepFactor: Tahmini torba dışı hatasının belirli bir miktarda iyileşmesi durana kadar artırılacak faktör.
- iyileştirme: adım faktörünü artırmaya devam etmek için torba çıkış hatasının iyileştirilmesi gereken miktar.
model_tuned <- tuneRF(
x=airquality[,-1], #define predictor variables
y=airquality$Ozone, #define response variable
ntreeTry= 500 ,
mtryStart= 4 ,
stepFactor= 1.5 ,
improve= 0.01 ,
trace= FALSE #don't show real-time progress
)
Bu işlev, x ekseninde ağaçlar oluşturulurken her bölmede kullanılan tahmincilerin sayısını ve y ekseninde tahmini torba dışı hatasını görüntüleyen aşağıdaki grafiği üretir:
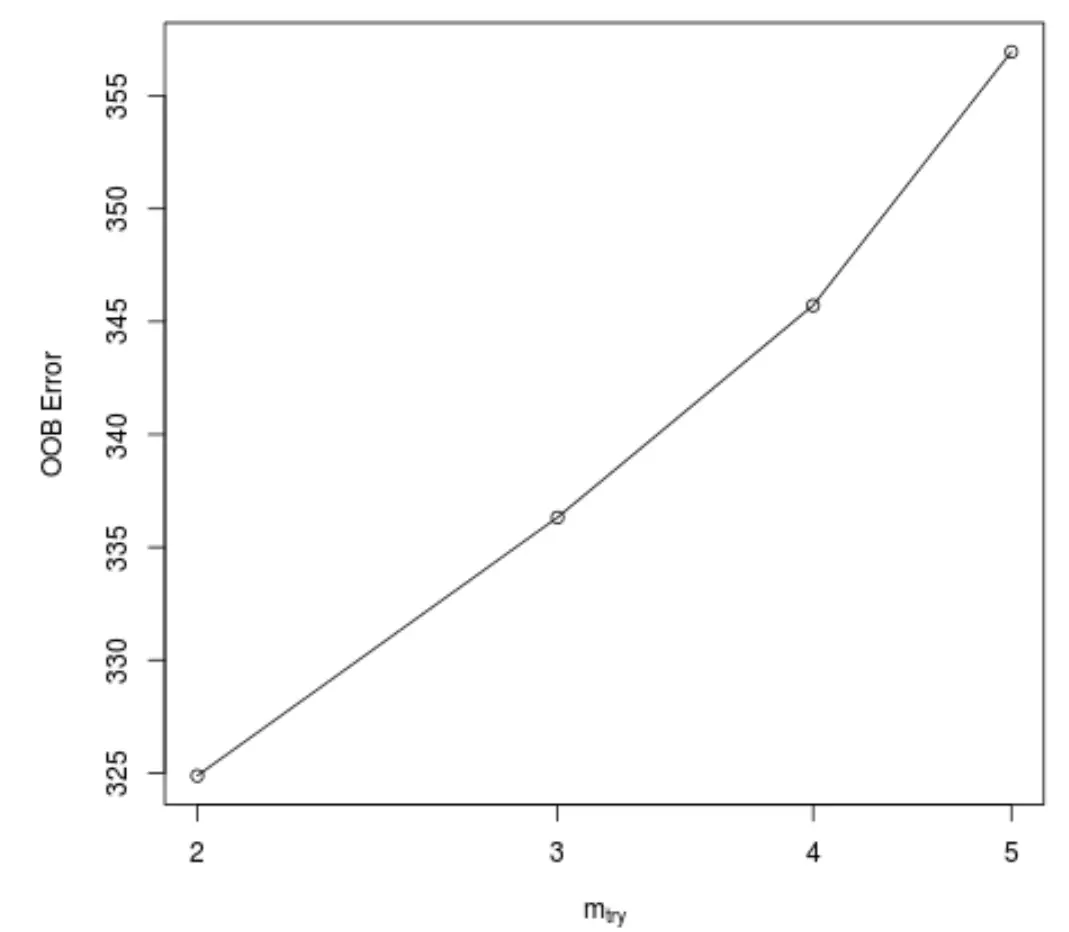
Ağaçları oluştururken her bölmede rastgele seçilen 2 tahmincinin kullanılmasıyla en düşük OOB hatasının elde edildiğini görebiliriz.
Bu aslında başlangıçtaki randomForest() işlevi tarafından kullanılan varsayılan ayara (toplam tahminciler/3 = 6/3 = 2) karşılık gelir.
Adım 4: Tahminlerde bulunmak için son modeli kullanın
Son olarak, yeni gözlemler hakkında tahminlerde bulunmak için düzeltilmiş rastgele orman modelini kullanabiliriz.
#define new observation new <- data.frame(Solar.R=150, Wind=8, Temp=70, Month=5, Day=5) #use fitted bagged model to predict Ozone value of new observation predict(model, newdata=new) 27.19442
Uygun rastgele orman modeli, yordayıcı değişkenlerin değerlerine dayanarak, bu belirli günde ozon değerinin 27.19442 olacağını tahmin etmektedir.
Bu örnekte kullanılan R kodunun tamamını burada bulabilirsiniz.
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil