R'ye sınıflandırma ve regresyon ağaçları nasıl sığdırılır
Bir dizi yordayıcı değişken ile bir yanıt değişkeni arasındaki ilişki doğrusal olduğunda, çoklu doğrusal regresyon gibi yöntemler, doğru öngörücü modeller üretebilir.
Bununla birlikte, bir dizi öngörü ile bir yanıt arasındaki ilişki daha karmaşık olduğunda doğrusal olmayan yöntemler genellikle daha doğru modeller üretebilir.
Böyle bir yöntem, bir yanıt değişkeninin değerini tahmin eden karar ağaçları oluşturmak için bir dizi tahmin değişkeni kullanan sınıflandırma ve regresyon ağaçlarıdır (CART).
Yanıt değişkeni sürekli ise regresyon ağaçları oluşturabiliriz ve yanıt değişkeni kategorik ise sınıflandırma ağaçları oluşturabiliriz.
Bu eğitimde R’de regresyon ve sınıflandırma ağaçlarının nasıl oluşturulacağı açıklanmaktadır.
Örnek 1: R’de Regresyon Ağacı Oluşturma
Bu örnek için, 263 profesyonel beyzbol oyuncusu hakkında çeşitli bilgiler içeren ISLR paketindeki Hitters veri setini kullanacağız.
Bu veri setini, belirli bir oyuncunun maaşını tahmin etmek için sayı ve oynanan yılların tahmin değişkenlerini kullanan bir regresyon ağacı oluşturmak için kullanacağız.
Bu regresyon ağacını oluşturmak için aşağıdaki adımları kullanın.
Adım 1: Gerekli paketleri yükleyin.
Öncelikle bu örnek için gerekli paketleri yükleyeceğiz:
library (ISLR) #contains Hitters dataset library (rpart) #for fitting decision trees library (rpart.plot) #for plotting decision trees
Adım 2: İlk regresyon ağacını oluşturun.
Öncelikle büyük bir başlangıç regresyon ağacı oluşturacağız. “Karmaşıklık parametresi” anlamına gelen cp için küçük bir değer kullanarak ağacın büyük olduğunu garanti edebiliriz.
Bu, modelin genel R-kare değeri en azından cp tarafından belirtilen değer kadar arttığı sürece regresyon ağacında daha fazla bölme işlemi gerçekleştireceğimiz anlamına gelir.
Daha sonra model sonuçlarını yazdırmak için printcp() fonksiyonunu kullanacağız:
#build the initial tree
tree <- rpart(Salary ~ Years + HmRun, data=Hitters, control=rpart. control (cp= .0001 ))
#view results
printcp(tree)
Variables actually used in tree construction:
[1] HmRun Years
Root node error: 53319113/263 = 202734
n=263 (59 observations deleted due to missingness)
CP nsplit rel error xerror xstd
1 0.24674996 0 1.00000 1.00756 0.13890
2 0.10806932 1 0.75325 0.76438 0.12828
3 0.01865610 2 0.64518 0.70295 0.12769
4 0.01761100 3 0.62652 0.70339 0.12337
5 0.01747617 4 0.60891 0.70339 0.12337
6 0.01038188 5 0.59144 0.66629 0.11817
7 0.01038065 6 0.58106 0.65697 0.11687
8 0.00731045 8 0.56029 0.67177 0.11913
9 0.00714883 9 0.55298 0.67881 0.11960
10 0.00708618 10 0.54583 0.68034 0.11988
11 0.00516285 12 0.53166 0.68427 0.11997
12 0.00445345 13 0.52650 0.68994 0.11996
13 0.00406069 14 0.52205 0.68988 0.11940
14 0.00264728 15 0.51799 0.68874 0.11916
15 0.00196586 16 0.51534 0.68638 0.12043
16 0.00016686 17 0.51337 0.67577 0.11635
17 0.00010000 18 0.51321 0.67576 0.11615
n=263 (59 observations deleted due to missingness)
Adım 3: Ağacı budayın.
Daha sonra, en düşük test hatasına yol açan cp (karmaşıklık parametresi) için kullanılacak en uygun değeri bulmak amacıyla regresyon ağacını budayacağız.
cp için en uygun değerin önceki çıktıdaki en düşük x hatasına yol açan değer olduğuna dikkat edin; bu, çapraz doğrulama verilerinden elde edilen gözlemlerdeki hatayı temsil eder.
#identify best cp value to use
best <- tree$cptable[which. min (tree$cptable[," xerror "])," CP "]
#produce a pruned tree based on the best cp value
pruned_tree <- prune (tree, cp=best)
#plot the pruned tree
prp(pruned_tree,
faclen= 0 , #use full names for factor labels
extra= 1 , #display number of obs. for each terminal node
roundint= F , #don't round to integers in output
digits= 5 ) #display 5 decimal places in output

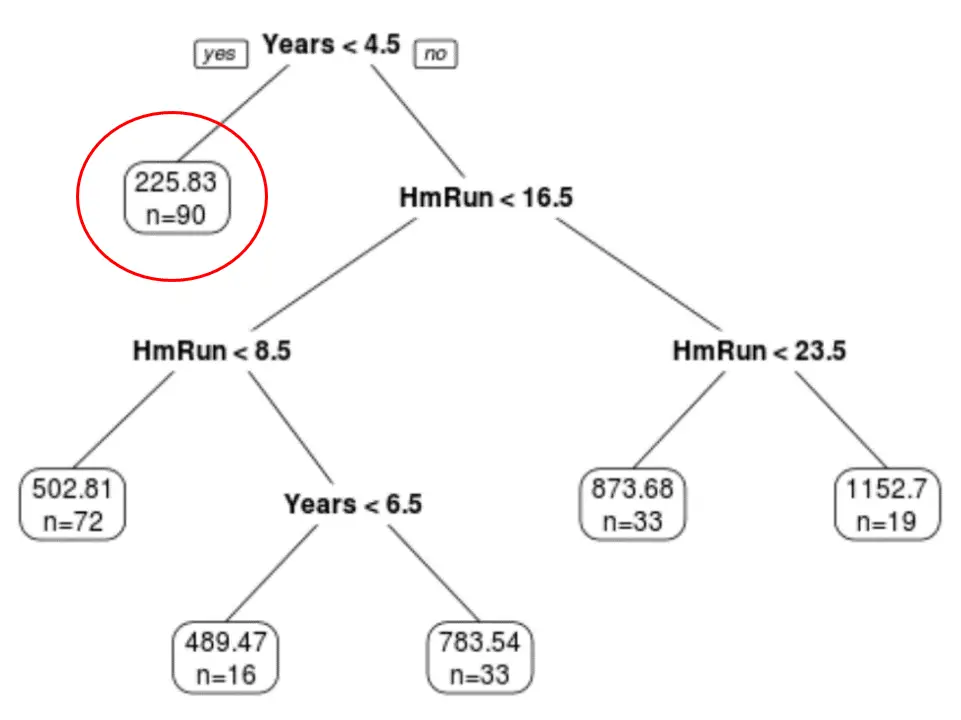
Son budanmış ağacın altı terminal düğümüne sahip olduğunu görebiliriz. Her yaprak düğüm, o düğümdeki oyuncuların tahmini maaşının yanı sıra, orijinal veri kümesindeki o sınıfa ait gözlem sayısını da görüntüler.
Örneğin, orijinal veri setinde 4,5 yıldan az deneyime sahip 90 oyuncunun bulunduğunu ve ortalama maaşlarının 225,83 bin dolar olduğunu görebiliyoruz.
Adım 4: Tahminlerde bulunmak için ağacı kullanın.
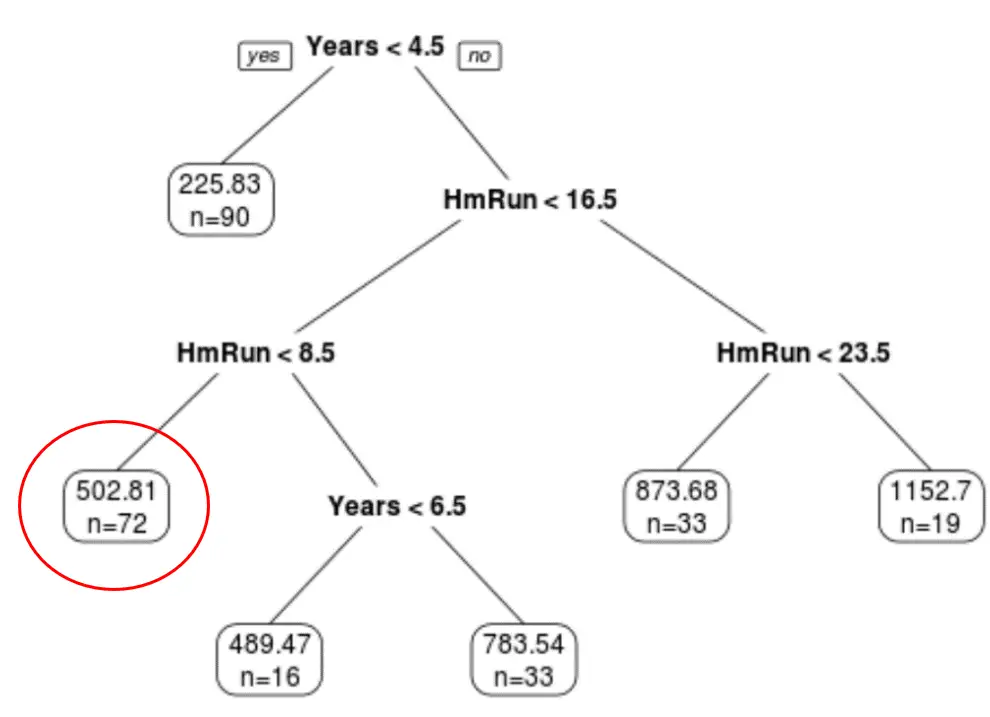
Belirli bir oyuncunun maaşını, yılların deneyimine ve ortalama sayı sayısına dayanarak tahmin etmek için son budanmış ağacı kullanabiliriz.
Örneğin, 7 yıllık tecrübeye sahip ve ortalama 4 home run yapan bir oyuncunun beklenen maaşı 502,81 bin dolar .
Bunu onaylamak için R’deki tahmin() fonksiyonunu kullanabiliriz:
#define new player
new <- data.frame(Years=7, HmRun=4)
#use pruned tree to predict salary of this player
predict(pruned_tree, newdata=new)
502.8079
Örnek 2: R’de bir sınıflandırma ağacı oluşturma
Bu örnek için Titanic’teki yolcular hakkında çeşitli bilgiler içeren rpart.plot paketindeki ptitanic veri setini kullanacağız.
Bu veri setini, belirli bir yolcunun hayatta kalıp kalmadığını tahmin etmek için sınıf , cinsiyet ve yaş tahmin değişkenlerini kullanan bir sınıflandırma ağacı oluşturmak için kullanacağız.
Bu sınıflandırma ağacını oluşturmak için aşağıdaki adımları kullanın.
Adım 1: Gerekli paketleri yükleyin.
Öncelikle bu örnek için gerekli paketleri yükleyeceğiz:
library (rpart) #for fitting decision trees library (rpart.plot) #for plotting decision trees
Adım 2: İlk sınıflandırma ağacını oluşturun.
İlk olarak geniş bir başlangıç sınıflandırma ağacı oluşturacağız. “Karmaşıklık parametresi” anlamına gelen cp için küçük bir değer kullanarak ağacın büyük olduğunu garanti edebiliriz.
Bu, genel model uyumu en azından cp tarafından belirtilen değer kadar arttığı sürece sınıflandırma ağacında daha fazla bölünme gerçekleştireceğimiz anlamına gelir.
Daha sonra model sonuçlarını yazdırmak için printcp() fonksiyonunu kullanacağız:
#build the initial tree
tree <- rpart(survived~pclass+sex+age, data=ptitanic, control=rpart. control (cp= .0001 ))
#view results
printcp(tree)
Variables actually used in tree construction:
[1] age pclass sex
Root node error: 500/1309 = 0.38197
n=1309
CP nsplit rel error xerror xstd
1 0.4240 0 1.000 1.000 0.035158
2 0.0140 1 0.576 0.576 0.029976
3 0.0095 3 0.548 0.578 0.030013
4 0.0070 7 0.510 0.552 0.029517
5 0.0050 9 0.496 0.528 0.029035
6 0.0025 11 0.486 0.532 0.029117
7 0.0020 19 0.464 0.536 0.029198
8 0.0001 22 0.458 0.528 0.029035
Adım 3: Ağacı budayın.
Daha sonra, en düşük test hatasına yol açan cp (karmaşıklık parametresi) için kullanılacak en uygun değeri bulmak amacıyla regresyon ağacını budayacağız.
cp için en uygun değerin önceki çıktıdaki en düşük x hatasına yol açan değer olduğuna dikkat edin; bu, çapraz doğrulama verilerinden elde edilen gözlemlerdeki hatayı temsil eder.
#identify best cp value to use
best <- tree$cptable[which. min (tree$cptable[," xerror "])," CP "]
#produce a pruned tree based on the best cp value
pruned_tree <- prune (tree, cp=best)
#plot the pruned tree
prp(pruned_tree,
faclen= 0 , #use full names for factor labels
extra= 1 , #display number of obs. for each terminal node
roundint= F , #don't round to integers in output
digits= 5 ) #display 5 decimal places in output
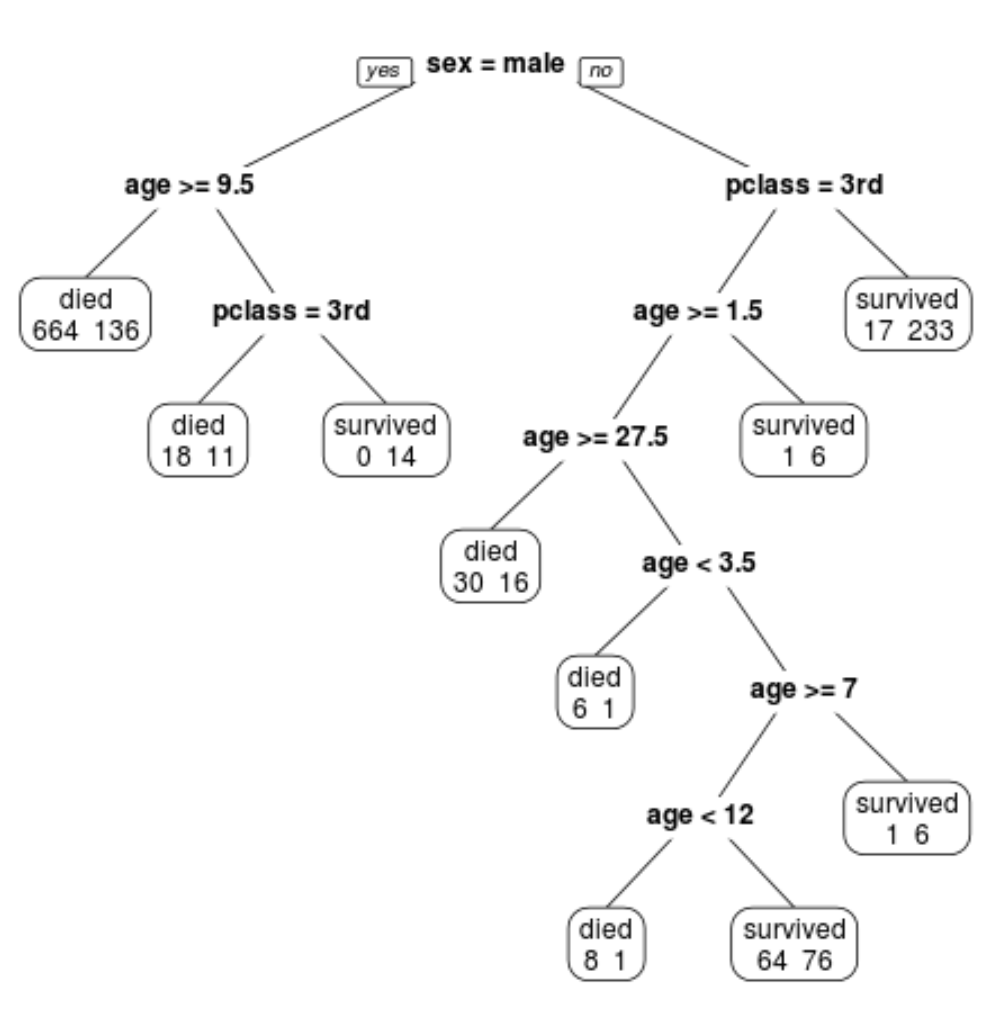
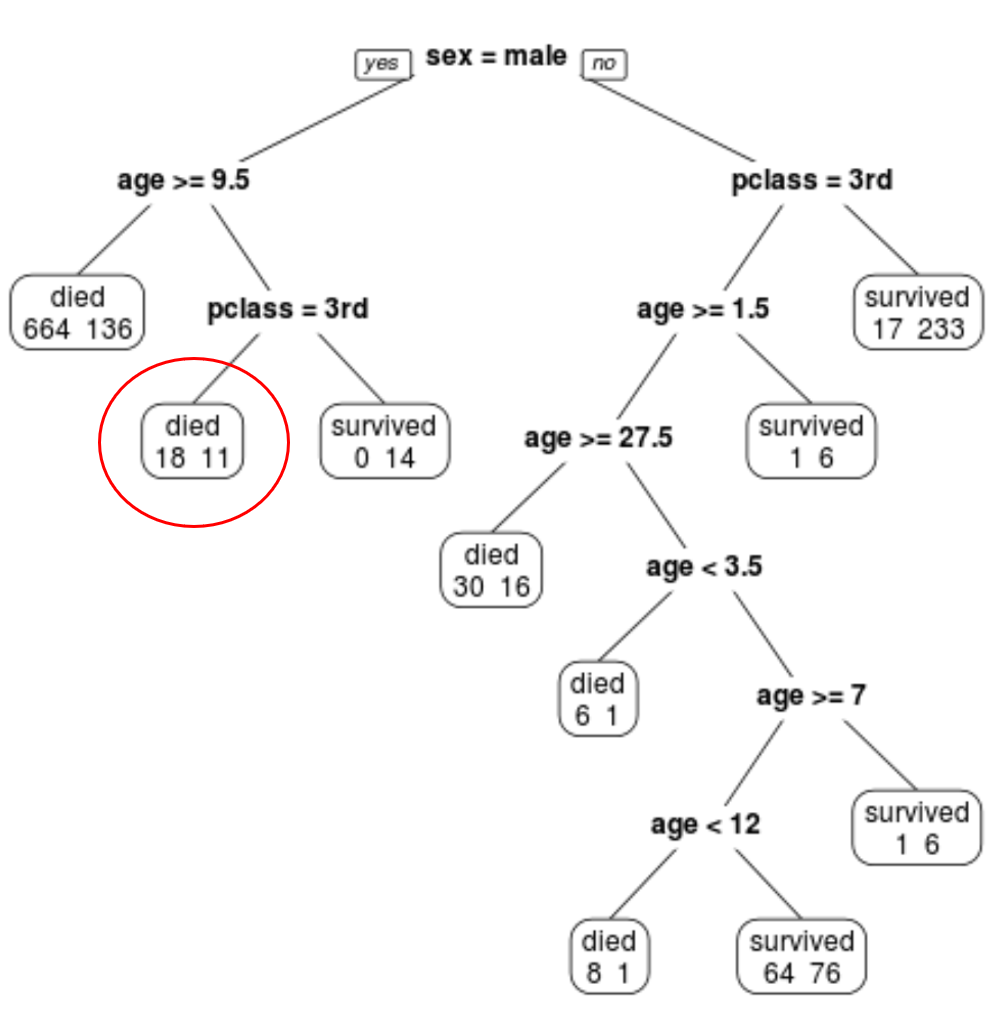
Son budanmış ağacın 10 terminal düğümüne sahip olduğunu görebiliriz. Her terminal düğümü, hayatta kalanların yanı sıra ölen yolcuların sayısını da gösterir.
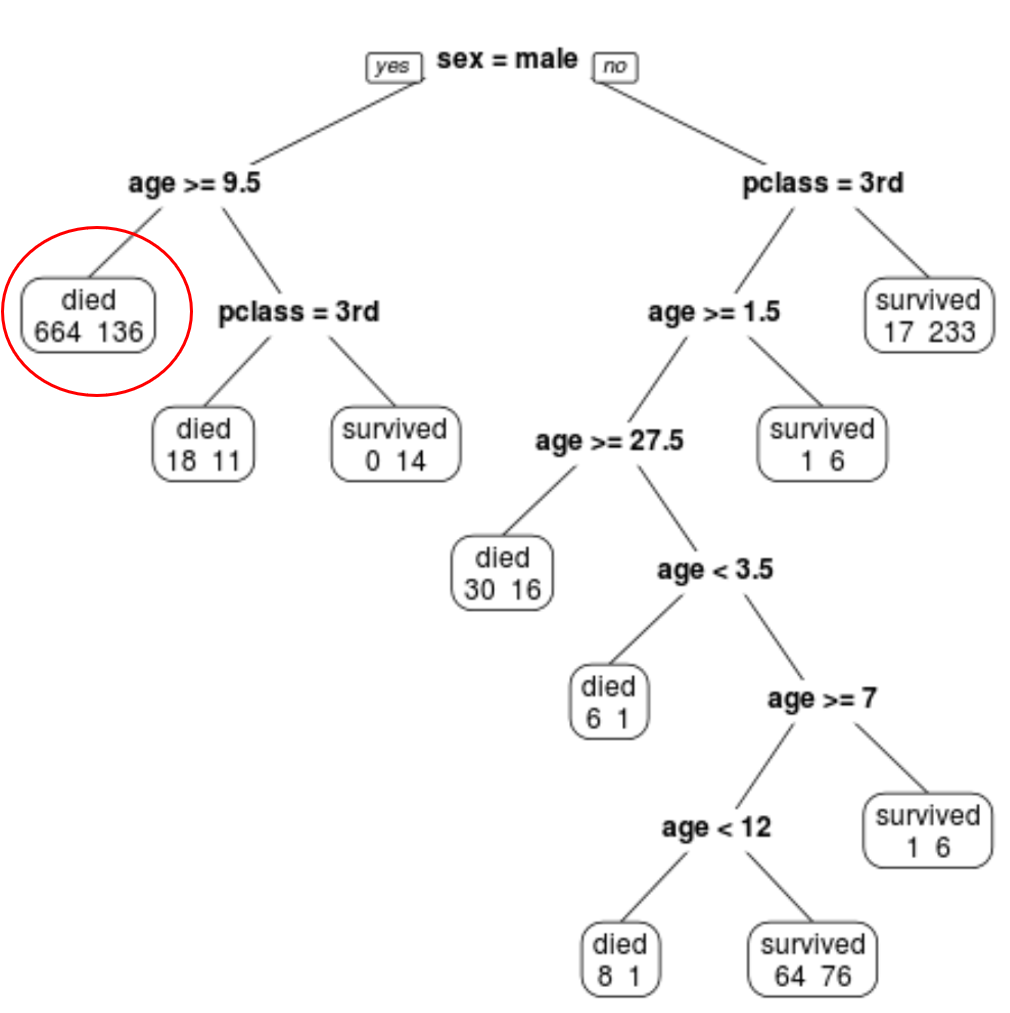
Örneğin en soldaki düğümde 664 yolcunun öldüğünü, 136 yolcunun hayatta kaldığını görüyoruz.
Adım 4: Tahminlerde bulunmak için ağacı kullanın.
Belirli bir yolcunun sınıfına, yaşına ve cinsiyetine göre hayatta kalma olasılığını tahmin etmek için son budanmış ağacı kullanabiliriz.
Örneğin 8 yaşında ve 1. sınıftaki bir erkek yolcunun hayatta kalma olasılığı 11/29 = %37,9’dur.
Bu örneklerde kullanılan R kodunun tamamını burada bulabilirsiniz.
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil