R'de ols regresyon nasıl gerçekleştirilir (örnekle)
Sıradan en küçük kareler (OLS) regresyonu, bir veya daha fazla yordayıcı değişken ile bir yanıt değişkeni arasındaki ilişkiyi en iyi tanımlayan doğruyu bulmamızı sağlayan bir yöntemdir.
Bu yöntem aşağıdaki denklemi bulmamızı sağlar:
ŷ = b 0 + b 1 x
Altın:
- ŷ : Tahmini yanıt değeri
- b 0 : Regresyon çizgisinin başlangıcı
- b 1 : Regresyon çizgisinin eğimi
Bu denklem, yordayıcı ile yanıt değişkeni arasındaki ilişkiyi anlamamıza yardımcı olabilir ve yordayıcı değişkenin değeri göz önüne alındığında, bir yanıt değişkeninin değerini tahmin etmek için kullanılabilir.
Aşağıdaki adım adım örnek, R’de OLS regresyonunun nasıl gerçekleştirileceğini gösterir.
1. Adım: Verileri oluşturun
Bu örnekte 15 öğrenci için aşağıdaki iki değişkeni içeren bir veri seti oluşturacağız:
- Toplam çalışılan saat sayısı
- Sınav sonucu
Tahmin edici değişken olarak saatleri ve yanıt değişkeni olarak sınav puanını kullanarak bir OLS regresyonu gerçekleştireceğiz.
Aşağıdaki kod, bu sahte veri kümesinin R’de nasıl oluşturulacağını gösterir:
#create dataset df <- data. frame (hours=c(1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14), score=c(64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89)) #view first six rows of dataset head(df) hours score 1 1 64 2 2 66 3 4 76 4 5 73 5 5 74 6 6 81
2. Adım: Verileri görselleştirin
OLS regresyonunu gerçekleştirmeden önce saatlerle sınav puanı arasındaki ilişkiyi görselleştirmek için bir dağılım grafiği oluşturalım:
library (ggplot2) #create scatterplot ggplot(df, aes(x=hours, y=score)) + geom_point(size= 2 )
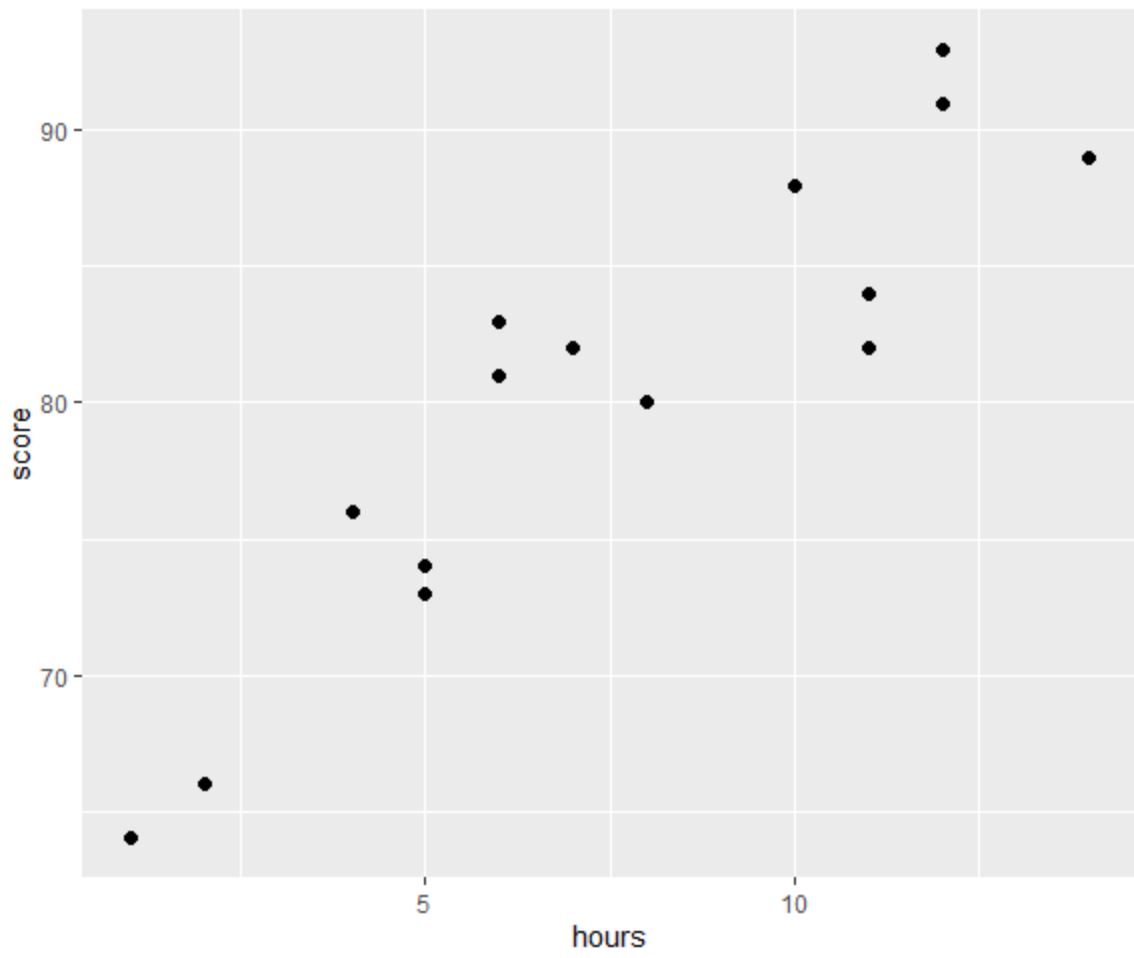
Doğrusal regresyonundört varsayımından biri, yordayıcı ile yanıt değişkeni arasında doğrusal bir ilişkinin olmasıdır.
Grafikten ilişkinin doğrusal olduğunu görebiliriz. Saat sayısı arttıkça puan da doğrusal olarak artma eğilimindedir.
Daha sonra sınav sonuçlarının dağılımını görselleştirmek ve aykırı değerleri kontrol etmek için bir kutu grafiği oluşturabiliriz.
Not : R, üçüncü çeyreğin çeyrekler arası aralığının 1,5 katı üzerinde veya birinci çeyreğin altında çeyrekler arası aralığın 1,5 katı olan bir gözlemi aykırı değer olarak tanımlar.
Bir gözlem aykırı ise kutu grafiğinde küçük bir daire görünecektir:
library (ggplot2) #create scatterplot ggplot(df, aes(y=score)) + geom_boxplot()
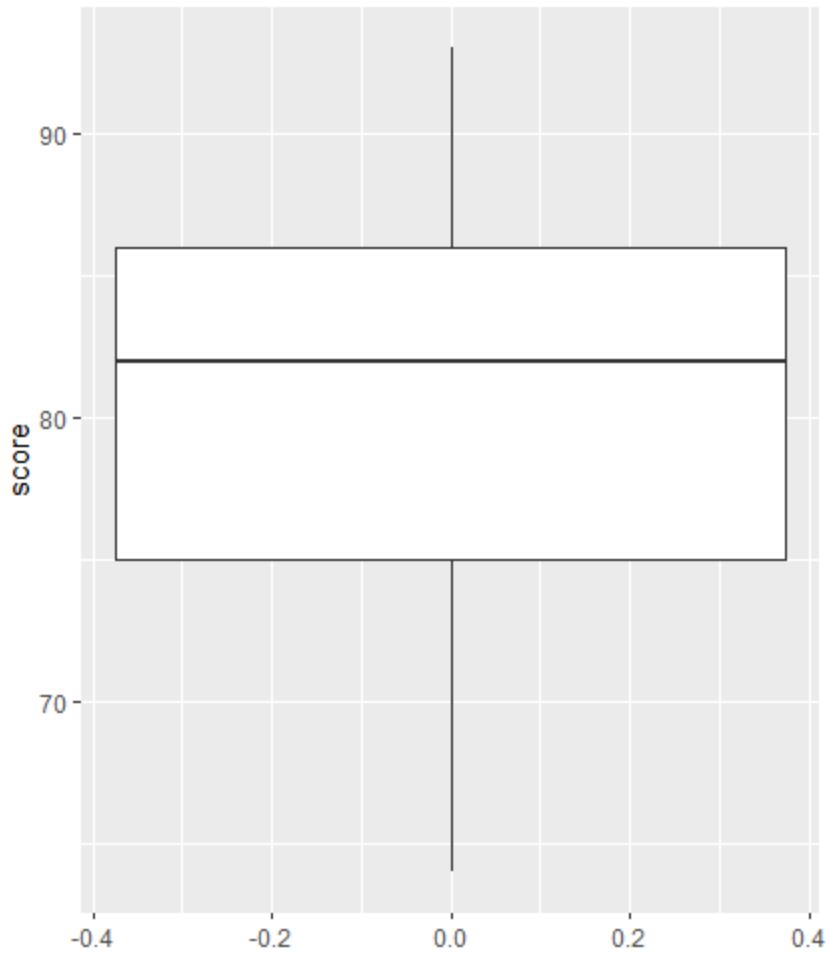
Kutu grafiğinde küçük daireler yok, bu da veri setimizde aykırı değerlerin olmadığı anlamına geliyor.
Adım 3: OLS Regresyonunu Gerçekleştirin
Daha sonra, tahmin değişkeni olarak saatleri ve yanıt değişkeni olarak puanı kullanarak bir OLS regresyonu gerçekleştirmek için R’deki lm() işlevini kullanabiliriz:
#fit simple linear regression model model <- lm(score~hours, data=df) #view model summary summary(model) Call: lm(formula = score ~ hours) Residuals: Min 1Q Median 3Q Max -5,140 -3,219 -1,193 2,816 5,772 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 65,334 2,106 31,023 1.41e-13 *** hours 1.982 0.248 7.995 2.25e-06 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.641 on 13 degrees of freedom Multiple R-squared: 0.831, Adjusted R-squared: 0.818 F-statistic: 63.91 on 1 and 13 DF, p-value: 2.253e-06
Model özetinden uygun regresyon denkleminin şöyle olduğunu görebiliriz:
Puan = 65,334 + 1,982*(saat)
Bu, çalışılan her ek saatin ortalama 1.982 puanlık sınav puanı artışıyla ilişkili olduğu anlamına gelir.
Orijinal değeri olan 65.334 bize sıfır saat ders çalışan bir öğrencinin ortalama beklenen sınav puanını anlatır.
Bu denklemi, öğrencinin ders çalıştığı saat sayısına göre beklenen sınav puanını bulmak için de kullanabiliriz.
Örneğin 10 saat ders çalışan bir öğrencinin sınav puanının 85,15 olması gerekir:
Puan = 65,334 + 1,982*(10) = 85,15
Model özetinin geri kalanını şu şekilde yorumlayabilirsiniz:
- Pr(>|t|): Model katsayılarıyla ilişkili p değeridir. Saatlere ilişkin p değeri (2,25e-06) 0,05’ten anlamlı derecede küçük olduğundan saat ile puan arasında istatistiksel olarak anlamlı bir ilişkinin olduğunu söyleyebiliriz.
- Çoklu R-kare: Bu sayı bize sınav puanlarındaki değişim yüzdesinin çalışılan saat sayısıyla açıklanabileceğini söyler. Genel olarak, bir regresyon modelinin R-kare değeri ne kadar büyük olursa, yordayıcı değişkenlerin yanıt değişkeninin değerini tahmin etmede o kadar iyi olur. Bu durumda puanlardaki değişimin %83,1’i çalışılan saatlerle açıklanabilir.
- Artık standart hata: gözlenen değerler ile regresyon çizgisi arasındaki ortalama mesafedir. Bu değer ne kadar düşük olursa, bir regresyon çizgisinin gözlemlenen verilere o kadar fazla karşılık gelebilmesi mümkündür. Bu durumda sınavda gözlemlenen ortalama puan, regresyon çizgisinin öngördüğü puandan 3.641 puan sapmaktadır.
- F istatistiği ve p değeri: F istatistiği ( 63.91 ) ve karşılık gelen p değeri ( 2.253e-06 ) bize regresyon modelinin genel önemini, yani modeldeki yordayıcı değişkenlerin varyasyonu açıklamada yararlı olup olmadığını anlatır. . yanıt değişkeninde. Bu örnekteki p değeri 0,05’ten küçük olduğundan modelimiz istatistiksel olarak anlamlıdır ve saatlerin puan değişimini açıklamada faydalı olduğu düşünülmektedir.
Adım 4: Artık Grafikler Oluşturun
Son olarak, eşcinsellik ve normallik varsayımlarını kontrol etmek için artık grafikleri oluşturmamız gerekiyor.
Eş varyans varsayımı, bir regresyon modelinin artıklarının , yordayıcı değişkenin her seviyesinde yaklaşık olarak eşit varyansa sahip olmasıdır.
Bu varsayımın karşılandığını doğrulamak için artıkların ve uyumların grafiğini oluşturabiliriz.
X ekseni takılan değerleri, y ekseni ise artıkları görüntüler. Artıklar grafik boyunca sıfır değeri etrafında rastgele ve düzgün bir şekilde dağılmış göründüğü sürece, eş varyanslılığın ihlal edilmediğini varsayabiliriz:
#define residuals res <- resid(model) #produce residual vs. fitted plot plot(fitted(model), res) #add a horizontal line at 0 abline(0,0)
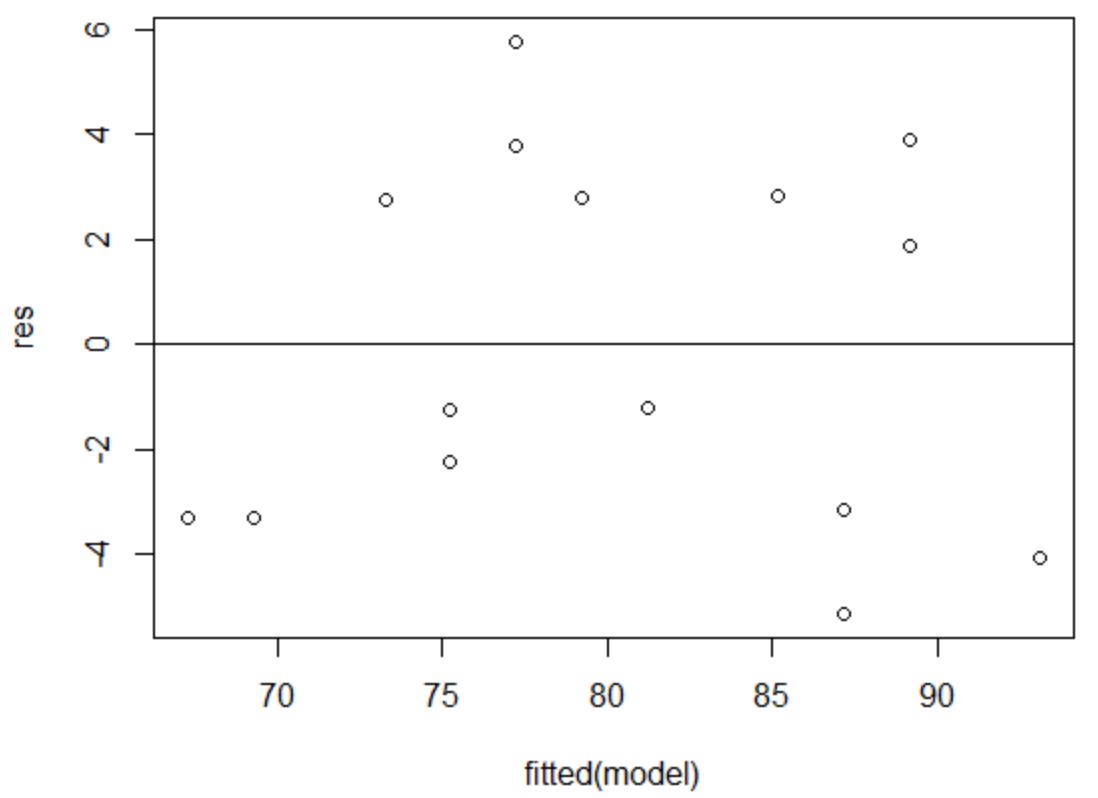
Artıklar sıfır etrafında rastgele dağılmış gibi görünüyor ve fark edilebilir bir desen göstermiyor, dolayısıyla bu varsayım karşılanıyor.
Normallik varsayımı, bir regresyon modelinin artıklarının yaklaşık olarak normal dağıldığını belirtir.
Bu varsayımın karşılanıp karşılanmadığını kontrol etmek için bir QQ grafiği oluşturabiliriz. Çizim noktaları 45 derecelik bir açı oluşturan kabaca düz bir çizgi boyunca uzanıyorsa veriler normal şekilde dağıtılır:
#create QQ plot for residuals qqnorm(res) #add a straight diagonal line to the plot qqline(res)
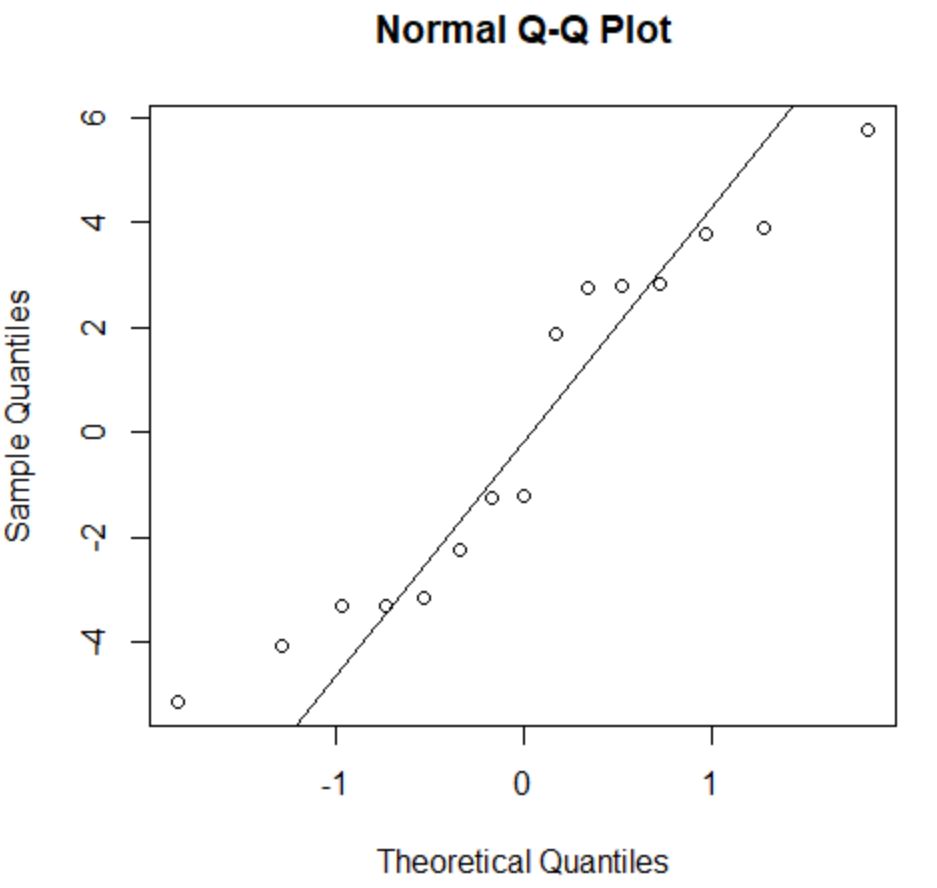
Kalıntılar 45 derece çizgisinden biraz sapıyor ancak ciddi endişe yaratacak kadar değil. Normallik varsayımının karşılandığını varsayabiliriz.
Artıklar normal dağıldığı ve homoskedastic olduğu için OLS regresyon modelinin varsayımlarının karşılandığını doğruladık.
Dolayısıyla modelimizin çıktısı güvenilirdir.
Not : Varsayımlardan bir veya daha fazlası karşılanmazsa verilerimizi dönüştürmeyi deneyebiliriz.
Ek kaynaklar
Aşağıdaki eğitimlerde R’de diğer ortak görevlerin nasıl gerçekleştirileceği açıklanmaktadır:
R’de çoklu doğrusal regresyon nasıl gerçekleştirilir
R’de üstel regresyon nasıl gerçekleştirilir
R’de ağırlıklı en küçük kareler regresyonu nasıl gerçekleştirilir?
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil