Regresyon veya sınıflandırma: fark nedir?
Makine öğrenimi algoritmaları iki farklı türe ayrılabilir: denetimli ve denetimsiz öğrenme algoritmaları .

Denetimli öğrenme algoritmaları iki türe ayrılabilir:
1. Regresyon: Yanıt değişkeni süreklidir.
Örneğin yanıt değişkeni şu şekilde olabilir:
- Ağırlık
- Yükseklik
- Fiyat
- Zaman
- Tüm birimler
Her durumda, bir regresyon modeli sürekli bir miktarı tahmin etmeye çalışır.
Regresyon örneği:
Diyelim ki 100 farklı ev için üç değişken içeren bir veri setimiz var: metrekare, banyo sayısı ve satış fiyatı.
Açıklayıcı değişkenler olarak metrekare ve banyo sayısını, tepki değişkeni olarak da satış fiyatını kullanan bir regresyon modeli uydurabiliriz.
Daha sonra bu modeli, metrekare ve banyo sayısına göre bir evin satış fiyatını tahmin etmek için kullanabiliriz.
Bu bir regresyon modeli örneğidir çünkü tepki değişkeni (satış fiyatı) süreklidir.
Bir regresyon modelinin doğruluğunu ölçmenin en yaygın yolu, tahmin edilen değerlerimizin bir modelde gözlemlenen değerlerimizden ortalama olarak ne kadar uzakta olduğunu bize söyleyen bir ölçüm olan kök ortalama kare hatasının (RMSE) hesaplanmasıdır. Aşağıdaki şekilde hesaplanır:
RMSE = √ Σ(P ben – Ö ben ) 2 / n
Altın:
- Σ “toplam” anlamına gelen süslü bir semboldür
- P i, i’inci gözlem için tahmin edilen değerdir
- O i, i’inci gözlem için gözlemlenen değerdir
- n örneklem büyüklüğüdür
RMSE ne kadar küçük olursa, regresyon modeli verilere o kadar iyi uyum sağlayabilir.
2. Sınıflandırma: Yanıt değişkeni kategoriktir.
Örneğin yanıt değişkeni aşağıdaki değerleri alabilir:
- Erkek veya kadın
- Başarılı veya başarısız
- Düşük, orta veya yüksek
Her durumda, bir sınıflandırma modeli bir sınıf etiketini tahmin etmeye çalışır.
Sınıflandırma örneği:
Diyelim ki 100 farklı üniversite basketbol oyuncusu için üç değişken içeren bir veri setimiz var: maç başına puan ortalaması, lig seviyesi ve NBA’e seçilip seçilmedikleri.
Açıklayıcı değişkenler olarak oyun başına ve bölüm seviyesi başına ortalama puanları kullanan ve yanıt değişkeni olarak “taslaklanmış” bir sınıflandırma modelini uyarlayabiliriz.
Daha sonra bu modeli, belirli bir oyuncunun maç başına aldığı puan ortalamasına ve lig seviyesine göre NBA’e alınıp alınmayacağını tahmin etmek için kullanabiliriz.
Yanıt değişkeni (“yazılı”) kategorik olduğundan bu bir sınıflandırma modeli örneğidir. Yani sadece iki farklı kategoride değer alabiliyor: “Yazılı” veya “Taslaksız”.
Bir sınıflandırma modelinin doğruluğunu ölçmenin en yaygın yolu, model tarafından yapılan doğru sınıflandırmaların yüzdesini hesaplamaktır:
Doğruluk = düzeltme sınıflandırmaları / toplam sınıflandırma denemesi sayısı * %100
Örneğin, bir model, bir oyuncunun olası 100 seçimden 88’inde NBA’e seçilip seçilmeyeceğini doğru bir şekilde tanımlıyorsa, modelin doğruluğu şu şekildedir:
Doğruluk = (88/100) * %100 = %88
Doğruluk ne kadar yüksek olursa, sınıflandırma modeli sonuçları o kadar iyi tahmin edebilir.
Regresyon ve Sınıflandırma Arasındaki Benzerlikler
Regresyon ve sınıflandırma algoritmaları aşağıdaki yönlerden benzerdir:
- Her ikisi de denetimli öğrenme algoritmalarıdır, yani her ikisi de bir yanıt değişkeni içerir.
- Her ikisi de bir yanıtı tahmin etmek amacıyla modeller oluşturmak için bir veya daha fazla açıklayıcı değişken kullanır.
- Her ikisi de açıklayıcı değişkenlerin değerlerindeki değişikliklerin bir yanıt değişkeninin değerlerini nasıl etkilediğini anlamak için kullanılabilir.
Regresyon ve sınıflandırma arasındaki farklar
Regresyon ve sınıflandırma algoritmaları aşağıdaki şekillerde farklılık gösterir:
- Regresyon algoritmaları sürekli bir miktarı tahmin etmeye çalışır ve sınıflandırma algoritmaları bir sınıf etiketini tahmin etmeye çalışır.
- Regresyon ve sınıflandırma modellerinin doğruluğunu nasıl ölçtüğümüz farklılık gösterir.
Regresyonun sınıflandırmaya dönüştürülmesi
Bir regresyon probleminin, yanıt değişkenini basit bir şekilde bölümlere ayırarak bir sınıflandırma problemine dönüştürülebileceğine dikkat edilmelidir.
Örneğin, üç değişken içeren bir veri setimiz olduğunu varsayalım: metrekare, banyo sayısı ve satış fiyatı.
Satış fiyatlarını tahmin etmek için metrekare ve banyo sayısını kullanarak bir regresyon modeli oluşturabiliriz.
Ancak satış fiyatını üç farklı sınıfa ayırabiliriz:
- 80.000 $ – 160.000 $: “Düşük satış fiyatı”
- 161.000 $ – 240.000 $: “Ortalama satış fiyatı”
- 241.000 $ – 320.000 $: “Yüksek satış fiyatı”
Daha sonra, belirli bir evin satış fiyatının hangi sınıfa (düşük, orta veya yüksek) gireceğini tahmin etmek için metrekare ve banyo sayısını açıklayıcı değişkenler olarak kullanabiliriz.
Her evi bir sınıfa yerleştirmeye çalıştığımız için bu bir sınıflandırma modeli örneği olacaktır.
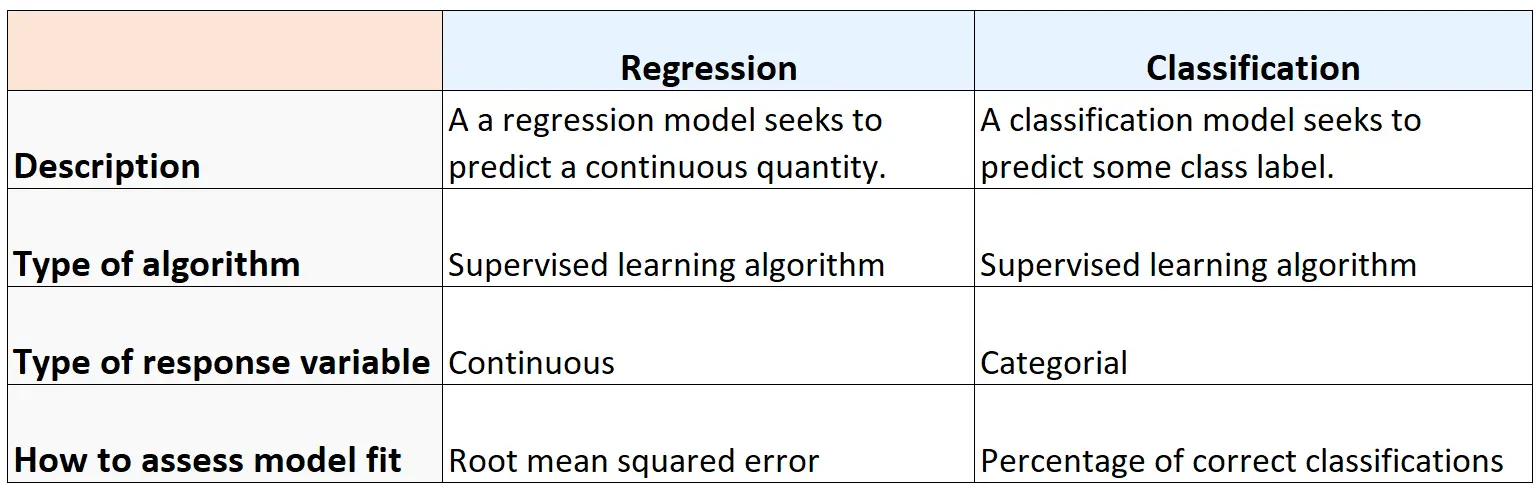
Özet
Aşağıdaki tabloda regresyon ve sınıflandırma algoritmaları arasındaki benzerlikler ve farklılıklar özetlenmektedir:
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil