Sas: dizeler sınırlayıcıya göre nasıl bölünür?
Bir dizeyi belirli bir sınırlayıcıya göre hızla bölmek için SAS’taki scan() işlevini kullanabilirsiniz.
Aşağıdaki örnekte bu fonksiyonun pratikte nasıl kullanılacağı gösterilmektedir.
Örnek: SAS’ta dizeleri sınırlayıcıya göre bölme
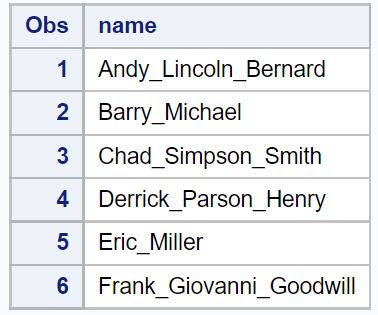
SAS’ta aşağıdaki veri setine sahip olduğumuzu varsayalım:
/*create dataset*/ data my_data1; input name $25.; datalines ; Andy_Lincoln_Bernard Barry_Michael Chad_Simpson_Smith Derrick_Parson_Henry Eric_Miller Frank_Giovanni_Goodwill ; run ; /*print dataset*/ proc print data =my_data1;
Ad dizesini hızlı bir şekilde üç ayrı dizeye bölmek için aşağıdaki kodu kullanabiliriz:
/*create second dataset with name split into three columns*/ data my_data2; set my_data1; name1= scan (name, 1 , '_'); name2= scan (name, 2 , '_'); name3= scan (name, 3 , '_'); run ; /*view second dataset*/ proc print data =my_data2;
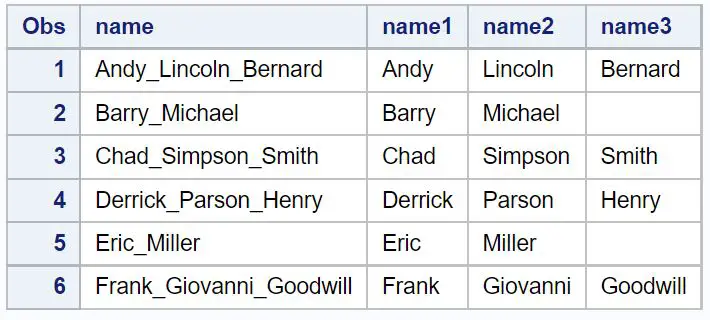
Ad sütunu dizesinin üç yeni sütuna bölündüğünü unutmayın.
Yalnızca bir sınırlayıcının bulunduğu adlar için name3 sütunundaki değer tamamen boştur.
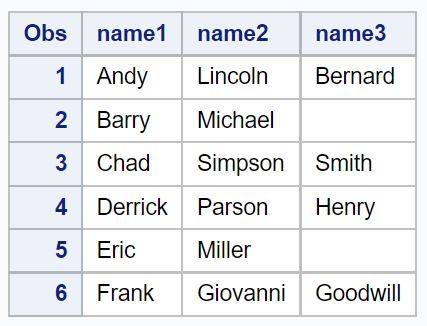
Orijinal ad sütununu yeni veri kümesinden kaldırmak için drop işlevini de kullanabileceğimizi unutmayın:
/*create second dataset with name split into three columns, drop original name*/ data my_data2; set my_data1; name1= scan (name, 1 , '_'); name2= scan (name, 2 , '_'); name3= scan (name, 3 , '_'); dropname ; run ; /*view second dataset*/ proc print data =my_data2;
Ek kaynaklar
Aşağıdaki eğitimlerde SAS’ta diğer ortak görevlerin nasıl gerçekleştirileceği açıklanmaktadır:
SAS’ta veriler nasıl normalleştirilir?
SAS’ta değişkenler nasıl yeniden adlandırılır
SAS’ta kopyalar nasıl kaldırılır
SAS’ta eksik değerler sıfırla nasıl değiştirilir?
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil