Sas'ta proc cluster nasıl kullanılır (örnekle)
Kümeleme , bir veri seti içindeki gözlem gruplarını bulmaya çalışan bir makine öğrenme tekniğidir.
Amaç, her küme içindeki gözlemlerin birbirine oldukça benzer olduğu, farklı kümelerdeki gözlemlerin ise birbirinden oldukça farklı olduğu kümeleri bulmaktır.
SAS’ta kümeleme yapmanın en kolay yolu PROC CLUSTER kullanmaktır.
Aşağıdaki örnek PROC CLUSTER’ın pratikte nasıl kullanılacağını göstermektedir.
Örnek: SAS’ta PROC CLUSTER nasıl kullanılır?
Diyelim ki 20 farklı basketbolcunun sayı, asist ve ribaund bilgilerini içeren aşağıdaki veri setine sahibiz:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
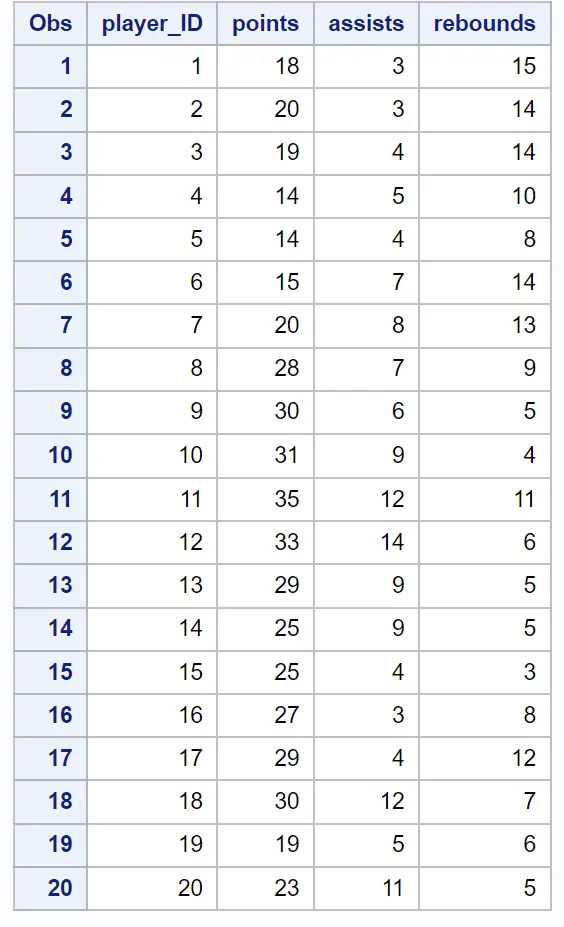
Diyelim ki birbirine benzer istatistiklere sahip oyuncuların “kümelerini” belirlemeye çalışmak için bazı gruplamalar yapmak istiyoruz.
Aşağıdaki kod, kümeleme gerçekleştirmek için SAS’ta PROC CLUSTER’ın nasıl kullanılacağını gösterir:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
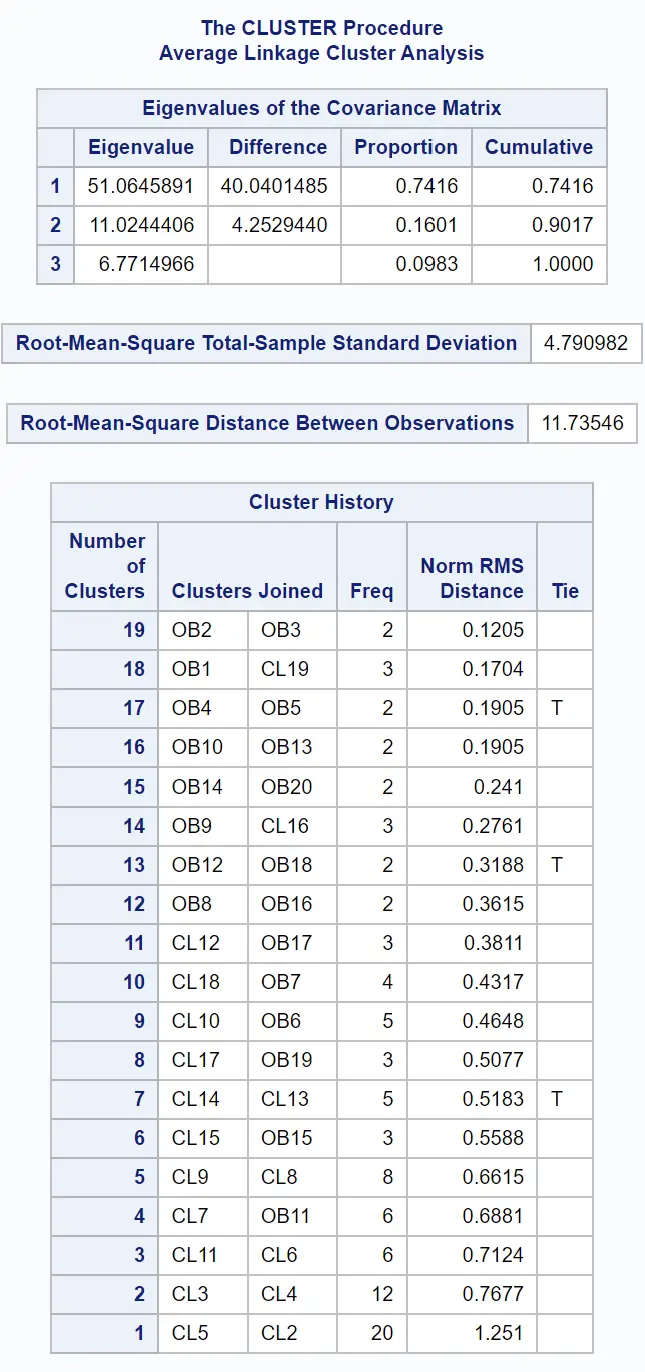
Sonucun ilk tabloları kümelemenin nasıl yapıldığına dair bilgi sağlar:
Veri kümesindeki gözlemler arasındaki benzerliği görsel olarak inceleyebilmemiz için bir dendrogram da üretilir:
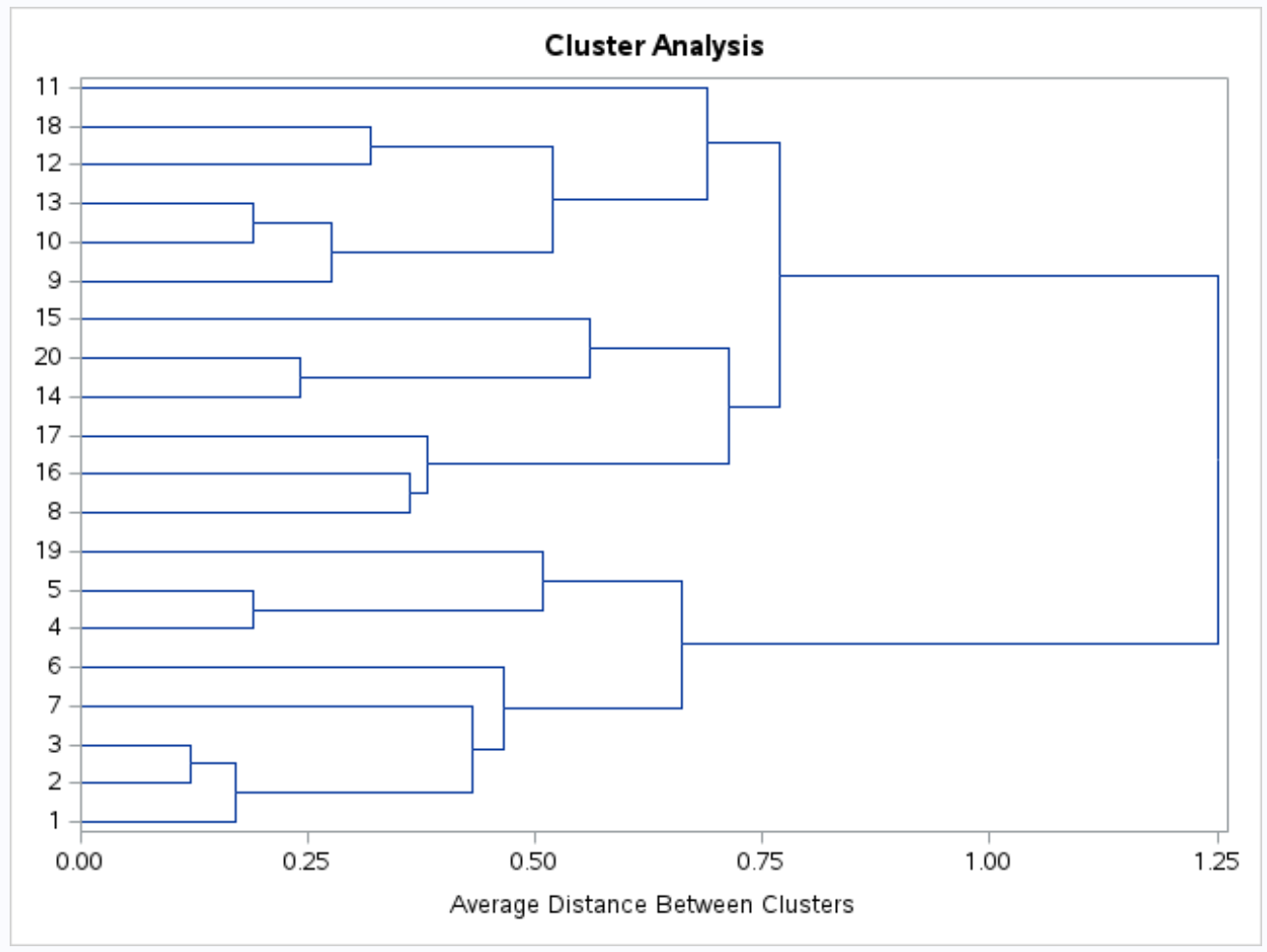
Y ekseni bireysel gözlemleri, x ekseni ise kümeler arasındaki ortalama mesafeyi gösterir.
Bu dendrograma bakıldığında gözlemlerin doğal olarak üç gruba ayrıldığı görülmektedir:
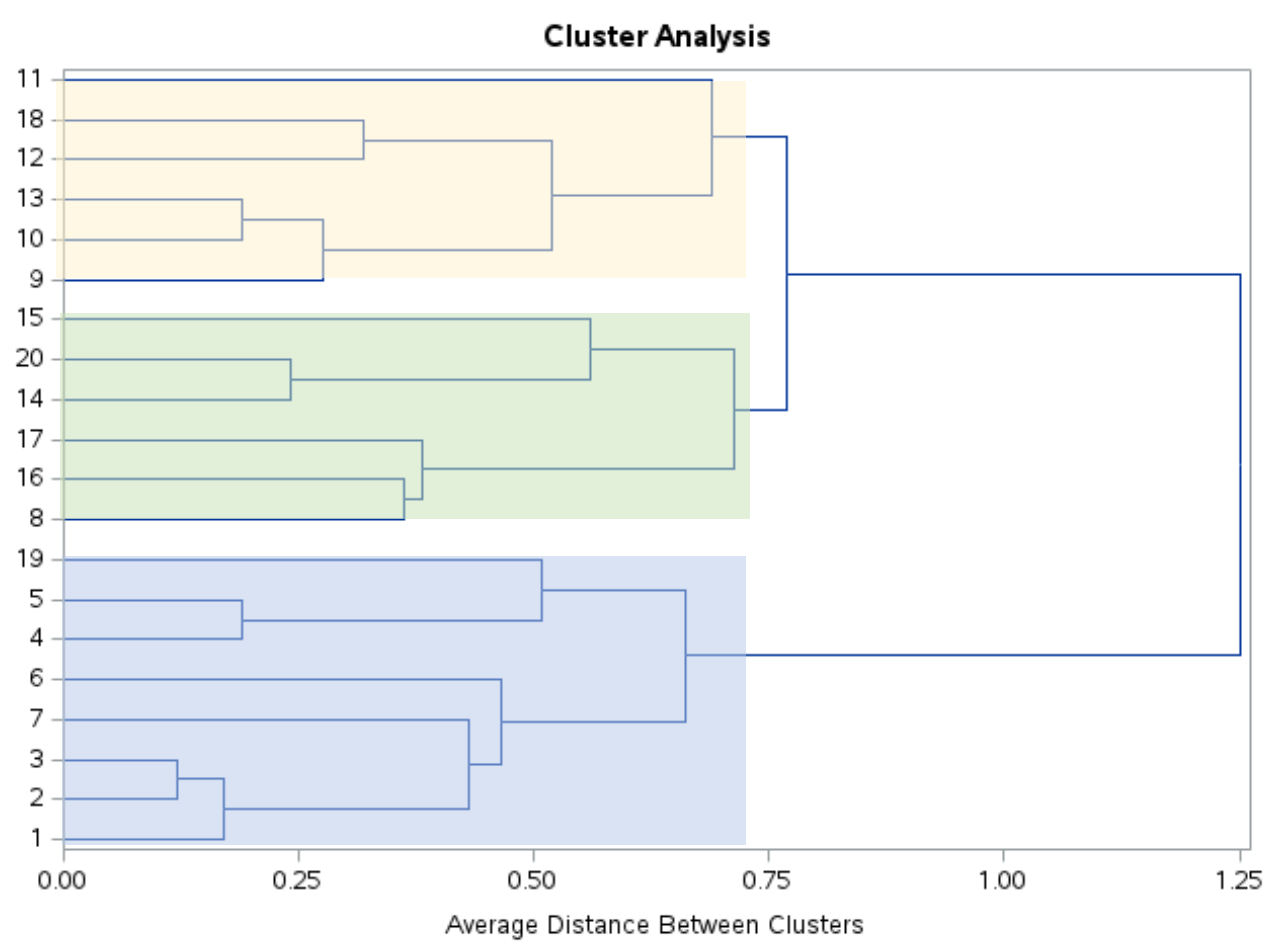
Daha sonra SAS’a orijinal veri kümesindeki her gözlemi üç kümeden birine atamasını söylemek için ncl=3 ile PROC TREE ifadesini kullanabiliriz:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
Ortaya çıkan veri seti, orijinal gözlemlerin her birini ait oldukları kümeyle birlikte gösterir:
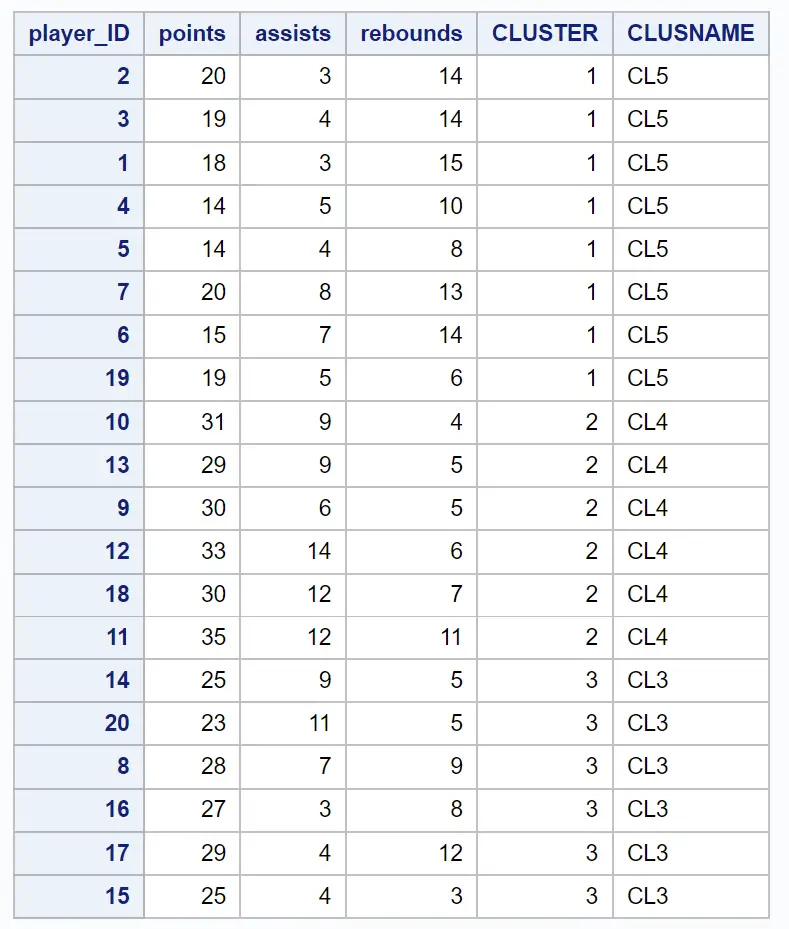
Örneğin şunu görebiliriz: 2, 3, 1, 4, 5, 7, 6 ve 19 kimlikli oyuncuların tümü küme 1’e aittir.
Bu bize bu sekiz oyuncunun sayı, asist ve ribaund değişkenleri açısından “benzer” olduğunu gösteriyor.
Not : Bu örnekte, kümeleme için bağlantı yöntemi olarak ortalamayı kullanmayı seçtik. Kullanabileceğiniz diğer bağlama yöntemlerinin tam listesi için SAS belgelerine bakın.
Ek kaynaklar
Aşağıdaki eğitimlerde SAS’ta diğer ortak görevlerin nasıl gerçekleştirileceği açıklanmaktadır:
SAS’ta Temel Bileşen Analizi Nasıl Gerçekleştirilir?
SAS’ta çoklu doğrusal regresyon nasıl gerçekleştirilir?
SAS’ta lojistik regresyon nasıl gerçekleştirilir?
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil