Sas'ta proc surveyselect nasıl kullanılır (örneklerle)
SAS’taki bir veri kümesinden rastgele bir örnek seçmek için PROC SURVEYSELECT’i kullanabilirsiniz.
Bu prosedürü pratikte kullanmanın üç yaygın yolu şunlardır:
Örnek 1: Basit rastgele bir örnek seçmek için PROC SURVEYSELECT’i kullanın
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling*/
n =5 /*select a total of 5 observations*/
seed =1; /*set seed to make this example reproducible*/
run ;
Bu özel örnek, veri kümesinden 5 rastgele gözlem seçmektedir.
Örnek 2: Katmanlı rastgele bir örnek seçmek için PROC SURVEYSELECT’i kullanın
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling*/
n =2 /*select 2 observations from each strata*/
seed =1; /*set seed to make this example reproducible*/
strata grouping_var; /*specify variable to use for stratification*/
run ;
Bu özel örnek, veri kümesinin her benzersiz katmanından 2 rastgele gözlem seçer.
Strata ifadesi tabakalandırma için kullanılacak değişkeni belirtir.
Örnek 3: Havuza alınmış rastgele bir örnek seçmek için PROC SURVEYSELECT’i kullanın
proc surveyselect data =my_data
out =my_sample
n =2 /*select 2 clusters*/
seed =1; /*set seed to make this example reproducible*/
clustergrouping_var ; /*specify variable to use for stratification*/
run ;
Bu özel örnek, veri kümesinden 2 rastgele küme seçer ve örnekteki her kümedeki her gözlemi içerir.
Cluster deyimi, kümeleme için kullanılacak değişkeni belirtir.
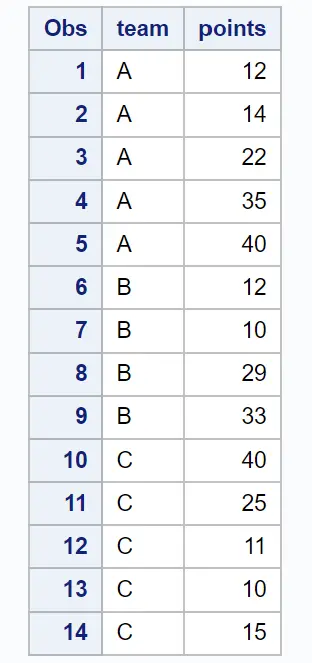
Aşağıdaki örnekler, SAS’ta farklı takımlardan basketbolcular hakkında bilgi içeren aşağıdaki veri kümesiyle her yöntemin pratikte nasıl kullanılacağını gösterir:
/*create dataset*/
data my_data;
input team $points;
datalines ;
AT 12
At 14
At 22
At 35
At 40
B 12
B 10
B29
B 33
C40
C25
C 11
C 10
C15
;
run ;
/*view dataset*/
proc print data = my_data;
Örnek 1: Basit rastgele bir örnek seçmek için PROC SURVEYSELECT’i kullanın
Veri kümesinden 5 gözlemden oluşan basit bir rastgele örnek seçmek için aşağıdaki sözdizimini kullanabiliriz:
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling*/
n =5 /*select a total of 5 observations*/
seed =1; /*set seed to make this example reproducible*/
run ;
/*view sample*/
proc print data =my_sample;
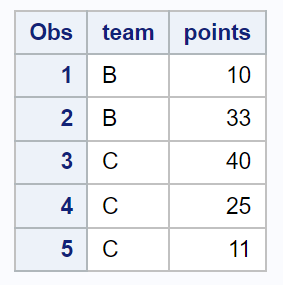
Ortaya çıkan örnek, veri setinden rastgele seçilen 5 gözlem içerir.
Örnek 2: Katmanlı rastgele bir örnek seçmek için PROC SURVEYSELECT’i kullanın
Örneğe dahil edilecek her takımdan rastgele 2 gözlemin seçildiği katmanlı rastgele örneklemeyi gerçekleştirmek için aşağıdaki sözdizimini kullanabiliriz:
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling within strata*/
n =2 /*select 2 observations from each strata*/
seed =1; /*set seed to make this example reproducible*/
strata grouping_var; /*specify variable to use for stratification*/
run ;
/*view sample*/
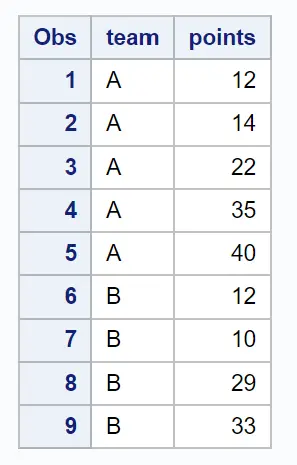
proc print data =my_sample;
Ortaya çıkan örnek, her takımdan rastgele seçilmiş 2 gözlem içerir.
İlgili: Küme Örnekleme ve Katmanlı Örnekleme: Fark Nedir?
Örnek 3: Havuza alınmış rastgele bir örnek seçmek için PROC SURVEYSELECT’i kullanın
Takımları küme olarak kullandığımız ve rastgele 2 küme seçip bu kümelerdeki her gözlemi örneğe dahil ettiğimiz kümelenmiş rastgele örneklemeyi gerçekleştirmek için aşağıdaki sözdizimini kullanabiliriz:
proc surveyselect data =my_data
out =my_sample
n =2 /*select a total of 2 clusters*/
seed =1; /*set seed to make this example reproducible*/
clustergrouping_var ; /*specify variable to use for clustering*/
run ;
/*view sample*/
proc print data =my_sample;
Bu özel örnek, rastgele seçilen iki “küme” olan A ve B takımlarının tüm gözlemlerini içerir.
Not : PROC SURVEYSELECT belgelerinin tamamını burada bulabilirsiniz.
Ek kaynaklar
Aşağıdaki eğitimlerde SAS’ta diğer ortak görevlerin nasıl gerçekleştirileceği açıklanmaktadır:
SAS’ta tanımlayıcı istatistikler nasıl hesaplanır?
SAS’ta frekans tabloları nasıl oluşturulur?
SAS’ta yüzdelikler nasıl hesaplanır?
SAS’ta PivotTable’lar Nasıl Oluşturulur
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil