Google e-tablolar'da açıklayıcı istatistikler nasıl hesaplanır?
Tanımlayıcı istatistikler bir veri kümesini tanımlayan değerlerdir. Veri setindeki değerlerin dağılımının yanı sıra veri setinin merkezinin nerede olduğunu anlamamıza da yardımcı olurlar.
Aşağıdaki örnek, Google E-Tablolar’daki bir veri kümesi için aşağıdaki açıklayıcı istatistiklerin nasıl hesaplanacağını gösterir:
- Ortalama (ortalama değer)
- Medyan (ortalama değer)
- Moda (en sık görülen değer)
- Aralık (minimum ve maksimum değer arasındaki fark)
- Standart sapma (değerlerin dağılımı)
- Örneklem büyüklüğü (toplam gözlem sayısı)
Örnek: Google E-Tablolarda Tanımlayıcı İstatistiklerin Hesaplanması
Diyelim ki Google E-Tablolar’da 20 değere sahip aşağıdaki veri kümesine sahibiz:
Aşağıdaki ekran görüntüsü, kullanılan formüller de dahil olmak üzere bu veri kümesi için çeşitli tanımlayıcı istatistiklerin nasıl hesaplanacağını gösterir:
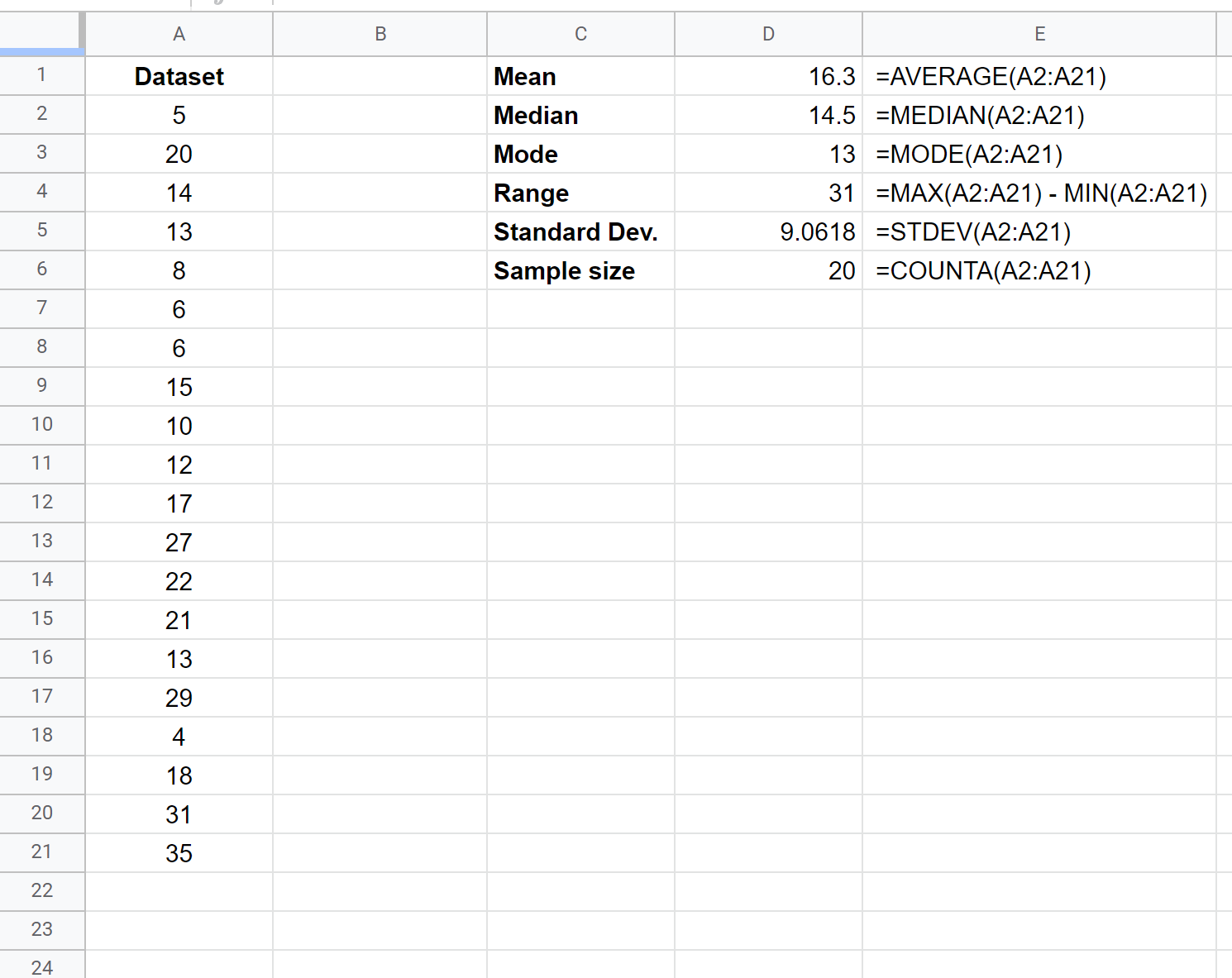
Veri kümesinin merkezinin nerede olduğuna dair fikir edinmek için aşağıdaki tanımlayıcı istatistikleri kullanabiliriz:
- Ortalama: 16.3
- Medyan: 14.5
- Mod: 13
Veri kümesindeki değerlerin dağılımı hakkında fikir edinmek için aşağıdaki tanımlayıcı istatistikleri kullanabiliriz:
- Aralık: 31
- Standart sapma: 9,0618
Son olarak, veri kümesindeki toplam gözlem sayısını anlamak için aşağıdaki tanımlayıcı istatistiği kullanabiliriz:
- Örneklem büyüklüğü: 20
Bu altı tanımlayıcı istatistiği kullanarak bu veri setindeki değerlerin dağılımını oldukça iyi anlayabiliriz.
Ek kaynaklar
Tanımlayıcı veya çıkarımsal istatistikler: fark nedir?
Menzil vs. Standart Sapma: Her Biri Ne Zaman Kullanılmalı
Ortalama ve Medyan: Her Biri Ne Zaman Kullanılmalı?
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil