Yüksek boyutlu veri nedir? (tanım ve örnekler)
Yüksek boyutlu veriler, p özellik sayısının gözlem sayısından N daha büyük olduğu ve genellikle p >> N olarak yazılan bir veri kümesini ifade eder.
Örneğin, p = 6 özelliğe ve yalnızca N = 3 gözleme sahip bir veri seti, özelliklerin sayısı gözlem sayısından daha fazla olduğu için yüksek boyutlu veri olarak kabul edilecektir.
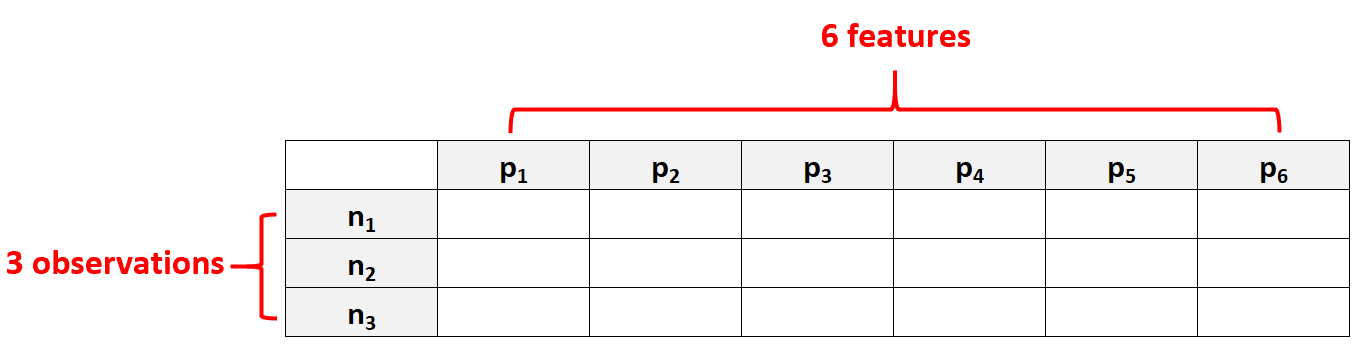
İnsanların yaptığı yaygın bir hata, “yüksek boyutlu verinin” yalnızca birçok özelliğe sahip bir veri seti anlamına geldiğini varsaymaktır. Ancak bu yanlıştır. Bir veri seti 10.000 özellik içerebilir ancak 100.000 gözlem içeriyorsa yüksek boyutlu değildir.
Not: Yüksek boyutlu verilerin ardındaki matematiğin derinlemesine bir tartışması için İstatistiksel Öğrenmenin Unsurları Bölüm 18’e bakın.
Yüksek boyutlu veriler neden bir sorundur?
Bir veri kümesindeki özelliklerin sayısı gözlem sayısını aştığında hiçbir zaman deterministik bir cevaba sahip olamayacağız.
Başka bir deyişle, yordayıcı değişkenler ile yanıt değişkeni arasındaki ilişkiyi tanımlayabilecek bir model bulmak imkansız hale geliyor çünkü modeli eğitmek için yeterli gözlemimiz yok.
Yüksek boyutlu veri örnekleri
Aşağıdaki örnekler farklı alanlardaki yüksek boyutlu veri kümelerini göstermektedir.
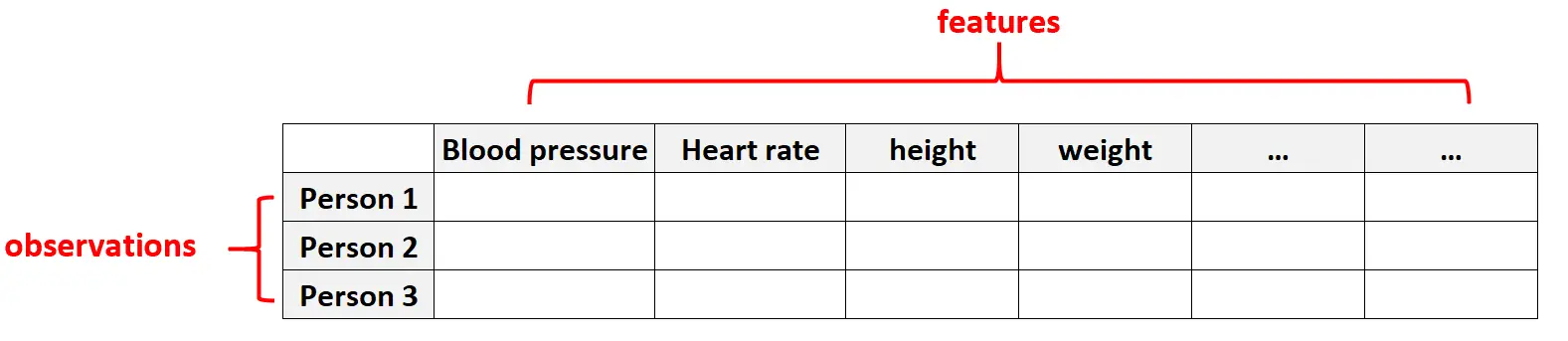
Örnek 1: Sağlık verileri
Yüksek boyutlu veriler, belirli bir kişiye ait özelliklerin sayısının çok fazla olabileceği sağlık hizmeti veri kümelerinde yaygındır (örn. kan basıncı, dinlenme kalp atış hızı, bağışıklık sistemi durumu, ameliyat geçmişi, boy, kilo, mevcut koşullar, vb.).
Bu veri setlerinde özellik sayısının gözlem sayısından daha fazla olması yaygındır.
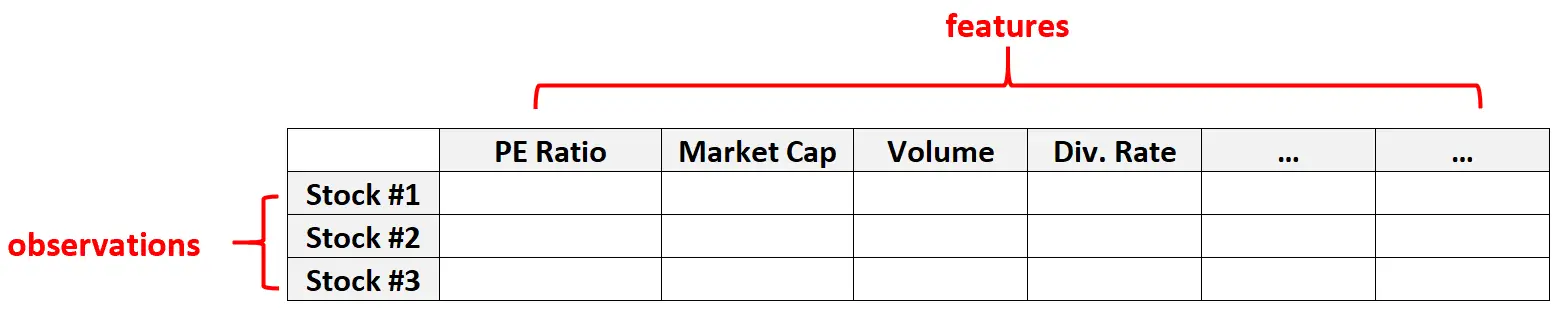
Örnek 2: finansal veriler
Yüksek boyutlu veriler, belirli bir hisse senedine ilişkin özellik sayısının oldukça büyük olabildiği finansal veri kümelerinde de yaygındır (yani PE oranı, piyasa değeri, işlem hacmi, temettü oranı vb.)
Bu tür veri kümelerinde varlık sayısının bireysel eylem sayısından çok daha fazla olması yaygındır.
Örnek 3: Genomik
Belirli bir bireyin genetik özelliklerinin sayısının çok fazla olabileceği genomik alanında da yüksek boyutlu veriler yaygındır.

Büyük veriler nasıl işlenir
Yüksek boyutlu verileri işlemenin iki yaygın yolu vardır:
1. Daha az özellik eklemeyi seçin.
Yüksek boyutlu verilerle uğraşmaktan kaçınmanın en belirgin yolu, veri setine daha az özellik eklemektir.
Bir veri kümesinden hangi özelliklerin kaldırılacağına karar vermenin birkaç yolu vardır:
- Birçok eksik değeri olan özellikleri kaldırın: Bir veri kümesindeki belirli bir sütunda birçok eksik değer varsa, fazla bilgi kaybetmeden onu tamamen kaldırabilirsiniz.
- Düşük varyanslı özellikleri kaldırın: Bir veri kümesindeki belirli bir sütun, çok az değişen değerlere sahipse, bir yanıt değişkeni hakkında diğer özelliklerden daha fazla yararlı bilgi sunma olasılığı düşük olduğundan, onu kaldırabilirsiniz.
- Yanıt değişkeniyle düşük korelasyona sahip özellikleri kaldırın: Belirli bir özellik, ilgilendiğiniz yanıt değişkeniyle yüksek düzeyde korelasyona sahip değilse, muhtemelen onu veri kümesinden kaldırabilirsiniz, çünkü bunun bir modelde yararlı bir özellik olması pek olası değildir.
2. Bir düzenleme yöntemi kullanın.
Veri kümesinden özellikleri kaldırmadan yüksek boyutlu verileri işlemenin başka bir yolu da aşağıdaki gibi bir düzenleme tekniği kullanmaktır:
Bu tekniklerin her biri, yüksek boyutlu verileri verimli bir şekilde işlemek için kullanılabilir.
Tüm istatistiksel makine öğrenimi eğitimlerinin tam listesini bu sayfada bulabilirsiniz.
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil