Таблиця anova
У цій статті ви знайдете пояснення таблиці ANOVA. Отже, ми пояснюємо вам, що таке таблиця ANOVA, як створити таблицю ANOVA, які формули таблиці ANOVA, і, крім того, ви зможете побачити вправу, розв’язану крок за кроком.
Що таке таблиця ANOVA?
Таблиця ANOVA — це таблиця, яка використовується в статистиці для дисперсійного аналізу. Більш конкретно, таблиця ANOVA містить всю інформацію, необхідну для дисперсійного аналізу.
Таким чином, таблиця ANOVA використовується для узагальнення дисперсійного аналізу. Побудувавши розрахунки дисперсійного аналізу в таблиці, ви можете легко зробити висновки, а також дозволити вам швидко обчислити значення статистики тесту ANOVA.
Формули таблиці ANOVA
У таблиці одностороннього дисперсійного аналізу є три рядки: фактор, помилка та підсумок. Таким чином, у таблиці ANOVA розраховуються суми квадратів кожного рядка та їх ступені вільності. Крім того, розраховується середня квадратична помилка фактора та помилки і, нарешті, визначається тестова статистика ANOVA, яка дорівнює відношенню квадратичних помилок.
Отже, формули для таблиці ANOVA такі:
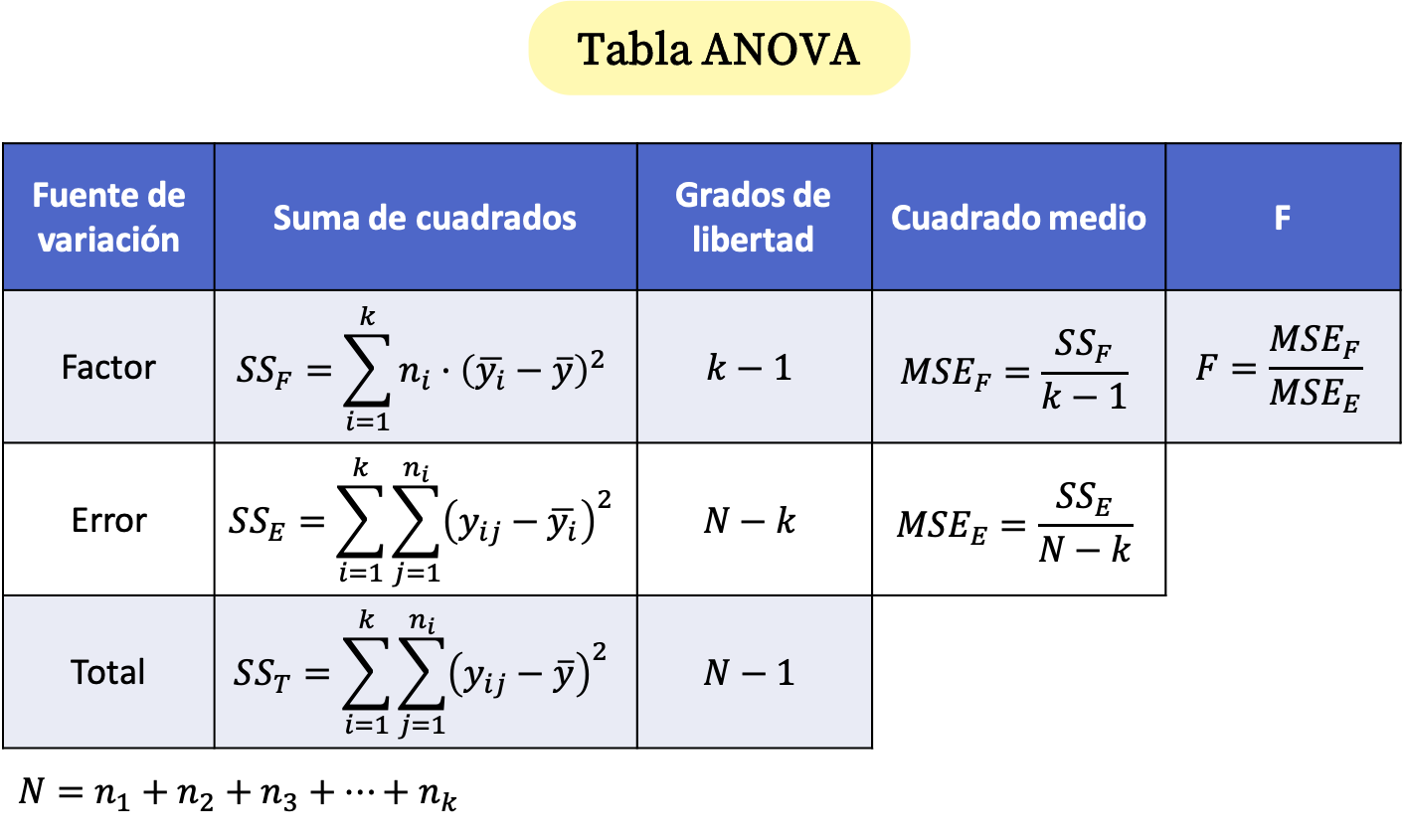
золото:
-

це розмір вибірки i.
-

– загальна кількість спостережень.
-

– кількість різних груп у дисперсійному аналізі.
-

є значення j групи i.
-

є середнім значенням групи i.
-

Це середнє значення всіх проаналізованих даних.
Приклад таблиці ANOVA
Щоб добре зрозуміти концепцію, давайте подивимося, як створити таблицю ANOVA, розв’язуючи приклад крок за кроком.
- Проводиться статистичне дослідження для порівняння балів, отриманих чотирма учнями з трьох різних предметів (A, B і C). У наведеній нижче таблиці детально описано бали, отримані кожним учнем під час тесту, максимальний бал якого становить 20. Побудуйте таблицю ANOVA, щоб порівняти бали, отримані кожним учнем з кожного предмета.
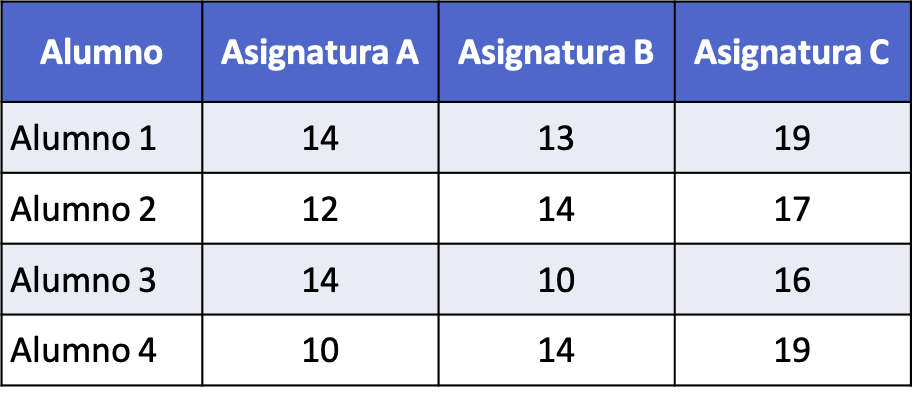
Перше, що нам потрібно зробити, це обчислити середнє значення кожного суб’єкта та загальне середнє значення даних:




Коли ми знаємо значення середніх, ми обчислюємо суми квадратів за допомогою формул у таблиці ANOVA (див. вище):
![\begin{aligned}\displaystyle SS_F&=\sum_{i=1}^k n_i(\overline{y}_i-\overline{y})^2\\[2ex] SS_F&= 4\cdot (12,5-14,33)^2+4\cdot (12,75-14,33)^2+4\cdot (17,75-14,33)^2\\[2ex] SS_F&=70,17\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-77b3fecdc3b577841da684cd80297288_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_E=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y}_i)^2\\[2ex] \displaystyle SS_E=\ &(14-12,5)^2+(12-12,5)^2+(14-12,5)^2+(10-12,5)^2+\\&+(13-12,75)^2+(14-12,75)^2+(10-12,75)^2+(14-12,75)^2+\\&+(19-17,75)^2+(17-17,75)^2+(16-17,75)^2+(19-17,75)^2\\[2ex] SS_E=\ &28,50\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-aa02f1b826df45c26ead3537ecc4c7e5_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_T=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y})^2\\[2ex] \displaystyle SS_T= \ &(14-14,33)^2+(12-14,33)^2+(14-14,33)^2+(10-14,33)^2+\\&+(13-14,33)^2+(14-14,33)^2+(10-14,33)^2+(14-14,33)^2+\\&+(19-14,33)^2+(17-14,33)^2+(16-14,33)^2+(19-14,33)^2\\[2ex] SS_T= \ &98,67\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-2eb66d1d37653749f38916c905108a3b_l3.png "Rendered by QuickLaTeX.com")
Потім визначаємо ступені свободи фактора, похибки та суми:



Тепер ми обчислюємо середні квадрати помилок, розділивши суми квадратів фактора та помилки на їхні відповідні ступені свободи:


І, нарешті, ми обчислюємо значення F-статистики, розділивши дві помилки, обчислені на попередньому кроці:

Коротко кажучи, таблиця дисперсійного аналізу для прикладу даних виглядатиме так:

Після того, як усі значення в таблиці ANOVA були обчислені, все, що залишається, це інтерпретувати її. Для цього ми повинні порівняти ймовірність, що відповідає значенню F-статистики, яка називається p-значенням. Ви можете побачити, як це робиться, натиснувши на таке посилання:
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше