Як виконати багатовимірне масштабування в python
У статистиці багатовимірне масштабування — це спосіб візуалізації подібності спостережень у наборі даних у абстрактному декартовому просторі (зазвичай 2D).
Найпростіший спосіб виконати багатовимірне масштабування в Python — це використовувати функцію MDS() підмодуля sklearn.manifold .
У наступному прикладі показано, як використовувати цю функцію на практиці.
Приклад: багатовимірне масштабування в Python
Припустімо, що у нас є такий фрейм даних pandas, який містить інформацію про різних баскетболістів:
import pandas as pd #create DataFrane df = pd. DataFrame ({' player ': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K '], ' points ': [4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28], ' assists ': [3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11], ' blocks ': [7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1], ' rebounds ': [4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2]}) #set player column as index column df = df. set_index (' player ') #view Dataframe print (df) points assists blocks rebounds player A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Ми можемо використовувати наступний код для виконання багатовимірного масштабування за допомогою функції MDS() модуля sklearn.manifold :
from sklearn. manifold import MDS
#perform multi-dimensional scaling
mds = MDS(random_state= 0 )
scaled_df = mds. fit_transform (df)
#view results of multi-dimensional scaling
print (scaled_df)
[[ 7.43654469 8.10247222]
[4.13193821 10.27360901]
[5.20534681 7.46919526]
[6.22323046 4.45148627]
[3.74110999 5.25591459]
[3.69073384 -2.88017811]
[3.89092087 -5.19100988]
[ -3.68593169 -3.0821144 ]
[ -9.13631889 -6.81016012]
[ -8.97898385 -8.50414387]
[-12.51859044 -9.08507097]]
Кожен рядок оригінального DataFrame було зменшено до (x, y) координат.
Ми можемо використати наступний код для візуалізації цих координат у 2D-просторі:
import matplotlib.pyplot as plt #create scatterplot plt. scatter (scaled_df[:,0], scaled_df[:,1]) #add axis labels plt. xlabel (' Coordinate 1 ') plt. ylabel (' Coordinate 2 ') #add lables to each point for i, txt in enumerate( df.index ): plt. annotate (txt, (scaled_df[:,0][i]+.3, scaled_df[:,1][i])) #display scatterplot plt. show ()
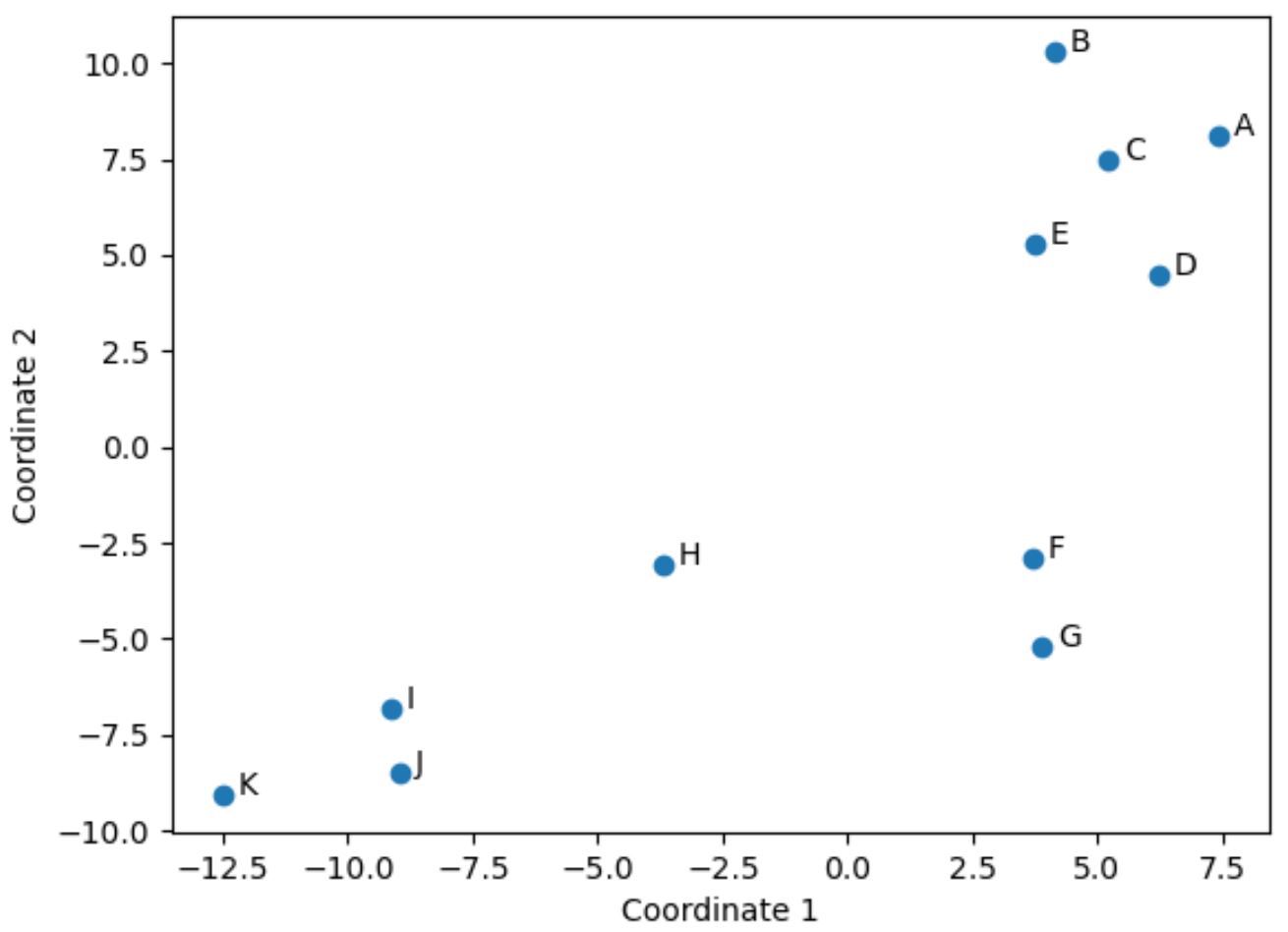
Гравці в оригінальному DataFrame, які мають схожі значення в оригінальних чотирьох стовпцях (очки, результативні передачі, блоки та підбирання), розташовані близько один до одного на сюжеті.
Наприклад, гравці F і G закриті один до одного. Ось їх значення з оригінального DataFrame:
#select rows with index labels 'F' and 'G'
df. loc [[' F ',' G ']]
points assists blocks rebounds
player
F 14 8 8 8
G 16 7 8 10
Їх значення для очок, передач, блоків і підбирань дуже схожі, що пояснює, чому вони так близькі один до одного на двовимірному графіку.
На противагу цьому розглянемо гравців B і K , які знаходяться далеко один від одного в сюжеті.
Якщо ми звернемося до їхніх значень в оригінальному DataFrame, то побачимо, що вони досить різні:
#select rows with index labels 'B' and 'K'
df. loc [[' B ',' K ']]
points assists blocks rebounds
player
B 4 2 3 5
K 28 11 1 2
Таким чином, двовимірний графік є хорошим способом візуалізації того, наскільки схожий кожен гравець за всіма змінними в DataFframe.
Гравці зі схожою статистикою згруповані близько один до одного, тоді як гравці з дуже різною статистикою розташовані далі один від одного в сюжеті.
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в Python:
Як нормалізувати дані в Python
Як видалити викиди в Python
Як перевірити нормальність у Python
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше