Як створити гістограму залишків у r
Одне з основних припущень лінійної регресії полягає в тому, що залишки мають нормальний розподіл.
Один із способів візуально перевірити це припущення — створити гістограму залишків і спостерігати, чи має розподіл «форму дзвона», що нагадує нормальний розподіл .
Цей підручник надає покроковий приклад створення гістограми залишків для моделі регресії в R.
Крок 1: Створіть дані
По-перше, створимо фейкові дані для роботи:
#make this example reproducible set.seed(0) #createdata x1 <- rnorm(n=100, 2, 1) x2 <- rnorm(100, 4, 3) y <- rnorm(100, 2, 3) data <- data.frame(x1, x2, y) #view first six rows of data head(data) x1 x2 y 1 3.262954 6.3455776 -1.1371530 2 1.673767 1.6696701 -0.6886338 3 3.329799 2.1520303 5.8081615 4 3.272429 4.1397409 3.7815228 5 2.414641 0.6088427 4.3269030 6 0.460050 5.7301563 6.6721111
Крок 2. Підберіть регресійну модель
Далі ми підберемо модель множинної лінійної регресії до даних:
#fit multiple linear regression model
model <- lm(y ~ x1 + x2, data=data)
Крок 3: Створіть гістограму залишків
Нарешті, ми використаємо пакет візуалізації ggplot для створення гістограми залишків моделі:
#load ggplot2
library (ggplot2)
#create histogram of residuals
ggplot(data = data, aes (x = model$residuals)) +
geom_histogram(fill = ' steelblue ', color = ' black ') +
labs(title = ' Histogram of Residuals ', x = ' Residuals ', y = ' Frequency ')
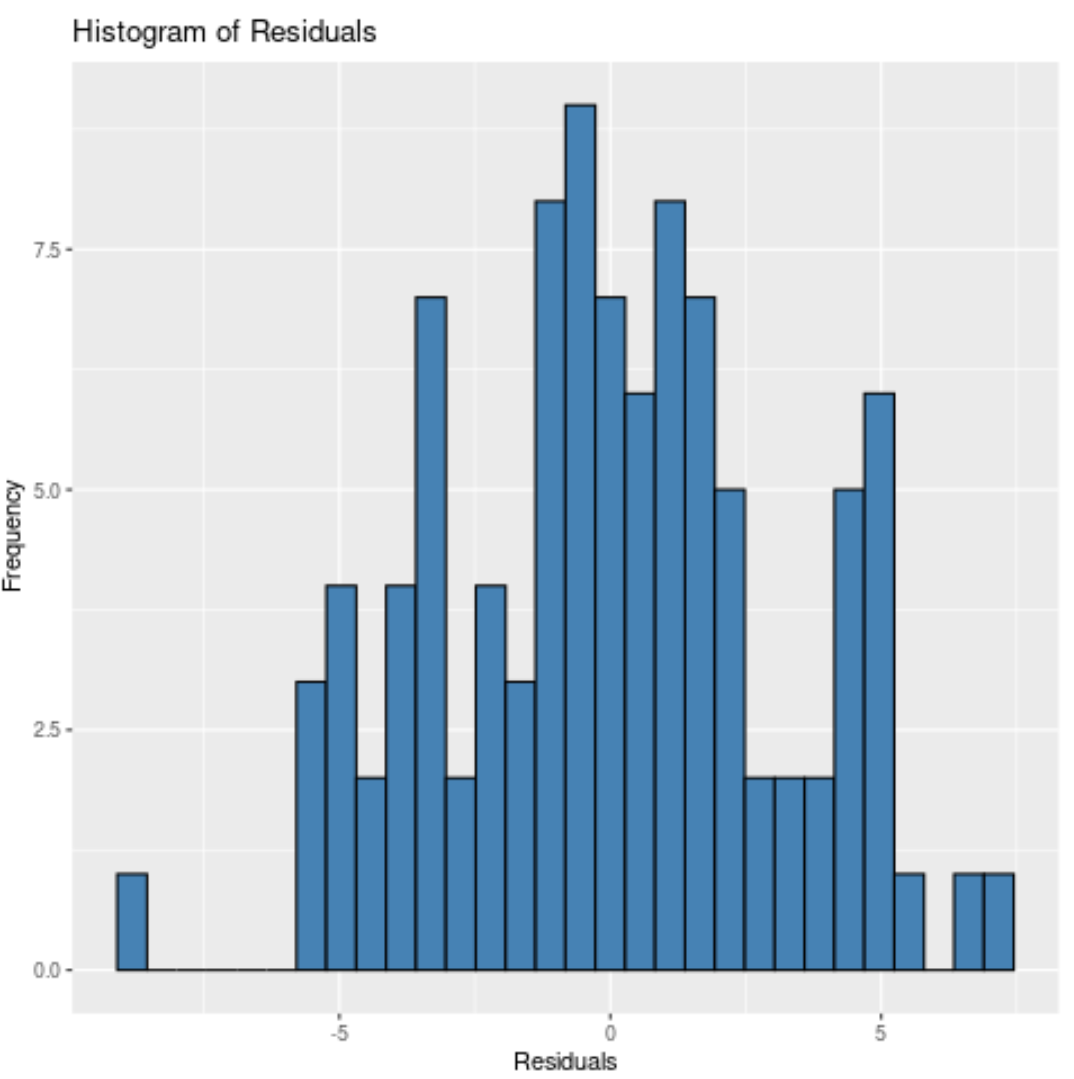
Зверніть увагу, що ми також можемо вказати кількість бункерів для розміщення залишків за допомогою аргументу bin .
Чим менше прямокутників, тим ширшими будуть стовпчики на гістограмі. Наприклад, ми можемо вказати 20 бункерів :
#create histogram of residuals
ggplot(data = data, aes (x = model$residuals)) +
geom_histogram(bins = 20 , fill = ' steelblue ', color = ' black ') +
labs(title = ' Histogram of Residuals ', x = ' Residuals ', y = ' Frequency ')
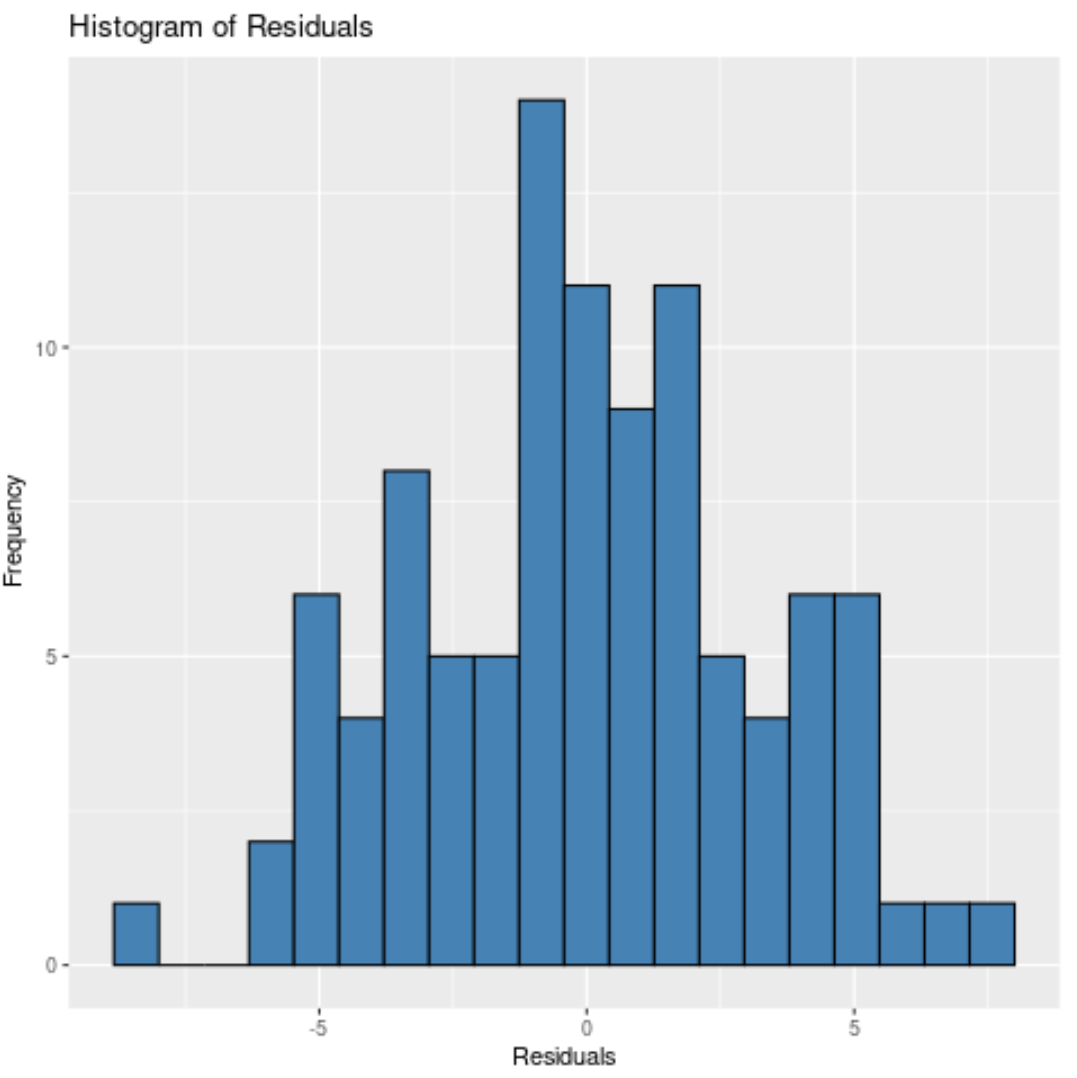
Або ми можемо вказати 10 бункерів :
#create histogram of residuals
ggplot(data = data, aes (x = model$residuals)) +
geom_histogram(bins = 10 , fill = ' steelblue ', color = ' black ') +
labs(title = ' Histogram of Residuals ', x = ' Residuals ', y = ' Frequency ')
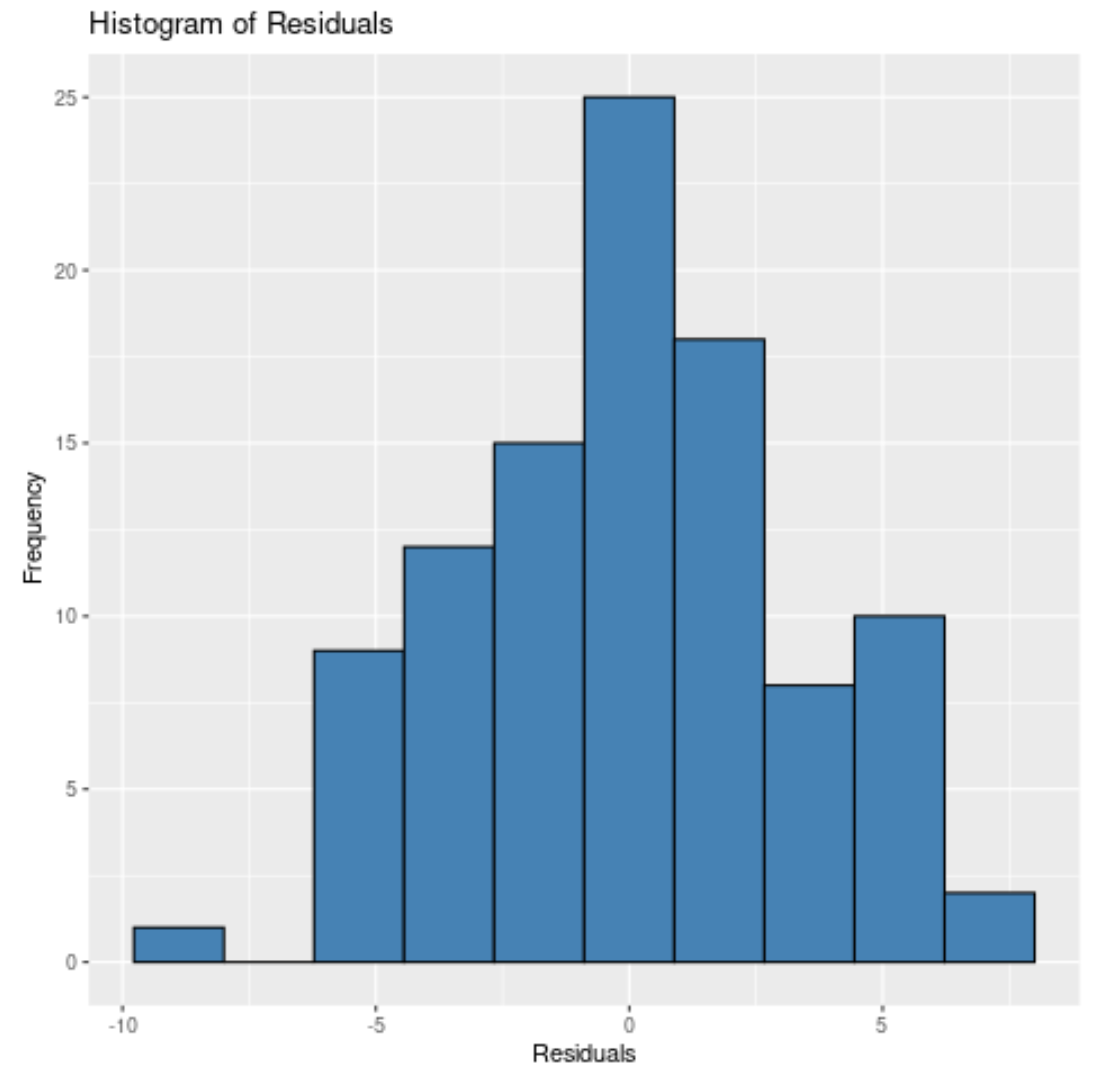
Незалежно від того, скільки ящиків ми вкажемо, ми бачимо, що залишки розподілені приблизно нормально.
Ми також можемо виконати формальний статистичний тест, як Шапіро-Вілка, Колмогорова-Смирнова або Жарка-Бера, щоб перевірити на нормальність.
Однак майте на увазі, що ці тести чутливі до великих розмірів вибірки, тобто вони часто роблять висновок, що залишки не є нормальними, коли розмір вибірки великий.
З цієї причини часто легше оцінити нормальність, створивши гістограму залишків.
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше