Що таке багатовимірні дані? (визначення та приклади)
Багатовимірні дані стосуються набору даних, у якому кількість ознак p перевищує кількість спостережень N , що часто записується як p >> N.
Наприклад, набір даних із p = 6 ознаками та лише N = 3 спостереженнями вважатиметься високовимірними даними, оскільки кількість ознак перевищує кількість спостережень.
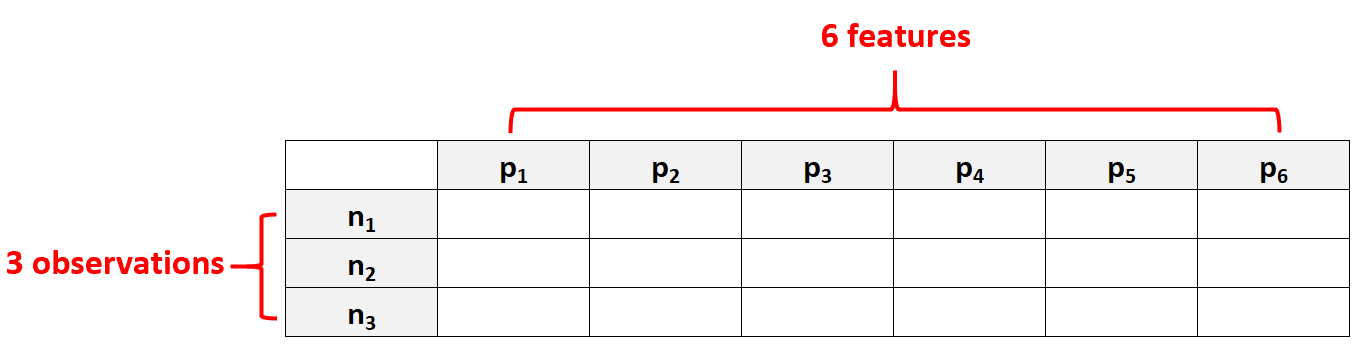
Поширеною помилкою людей є припущення, що «багатомірні дані» означають просто набір даних із багатьма функціями. Однак це невірно. Набір даних може містити 10 000 ознак, але якщо він містить 100 000 спостережень, він не є багатовимірним.
Примітка: зверніться до глави 18 Елементи статистичного навчання для поглибленого обговорення математики, що лежить в основі багатовимірних даних.
Чому багатовимірні дані є проблемою?
Коли кількість ознак у наборі даних перевищує кількість спостережень, ми ніколи не матимемо детермінованої відповіді.
Іншими словами, стає неможливим знайти модель, яка може описати зв’язок між змінними-прогнозами та змінною-відповіддю , оскільки у нас недостатньо спостережень, на яких можна навчити модель.
Приклади багатовимірних даних
Наступні приклади ілюструють багатовимірні набори даних у різних доменах.
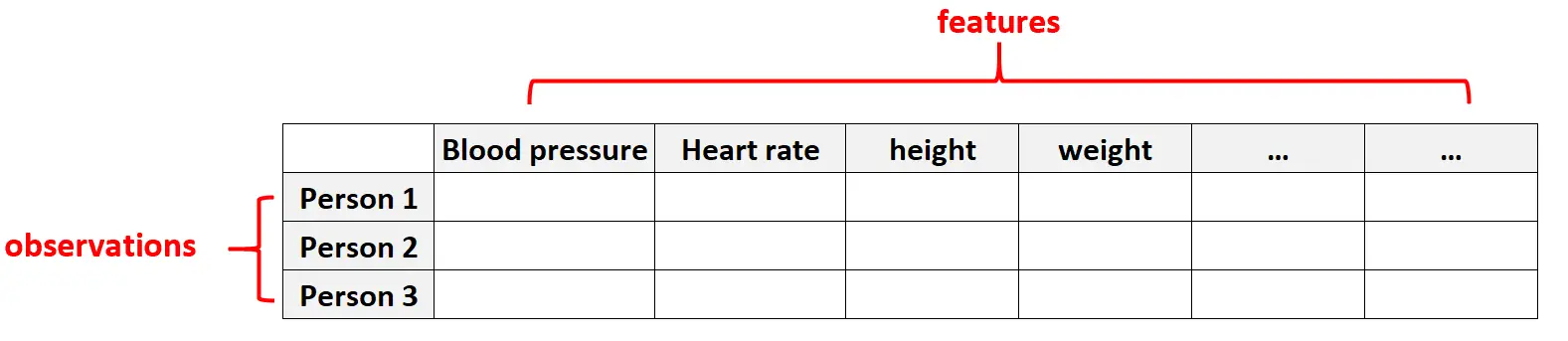
Приклад 1: дані про здоров’я
Багатовимірні дані часто зустрічаються в наборах даних охорони здоров’я, де кількість ознак для певної особи може бути величезною (наприклад, артеріальний тиск, частота серцевих скорочень у стані спокою, стан імунної системи, історія хірургічних операцій, зріст, вага, наявні захворювання тощо).
У цих наборах даних зазвичай кількість ознак перевищує кількість спостережень.
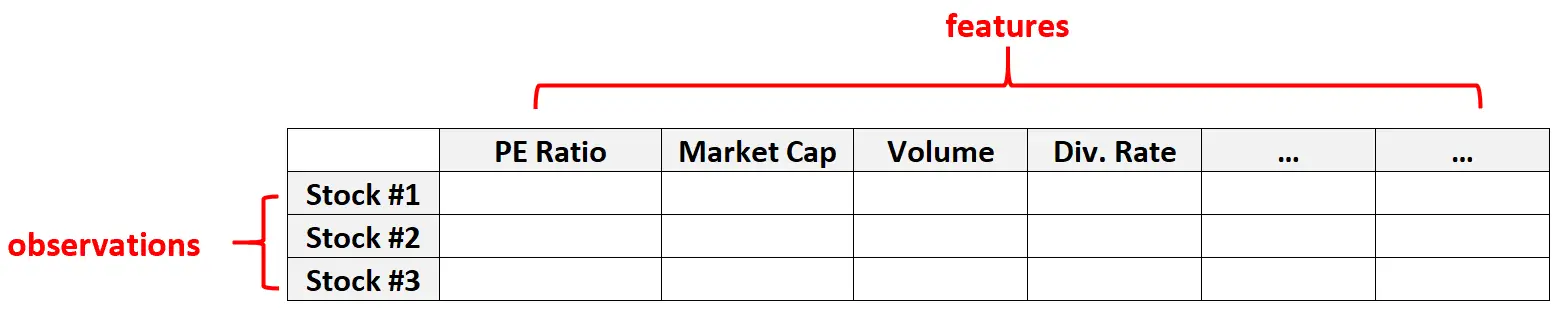
Приклад 2: фінансові дані
Багатовимірні дані також поширені в наборах фінансових даних, де кількість характеристик для даної акції може бути досить великою (наприклад, коефіцієнт прибутковості, ринкова капіталізація, обсяг торгів, ставка дивідендів тощо).
У цих типах наборів даних зазвичай кількість сутностей значно перевищує кількість окремих дій.
Приклад 3: Геноміка
Багатовимірні дані також поширені в галузі геноміки, де кількість генетичних характеристик окремої людини може бути величезною.

Як працювати з великими даними
Є два поширених способи обробки даних великої розмірності:
1. Виберіть менше функцій.
Найочевидніший спосіб уникнути роботи з великовимірними даними — просто включити менше функцій у набір даних.
Існує кілька способів вирішити, які функції видалити з набору даних, зокрема:
- Видаліть об’єкти з багатьма відсутніми значеннями: якщо певний стовпець у наборі даних містить багато пропущених значень, ви можете повністю видалити його, не втрачаючи багато інформації.
- Видаліть функції з низькою дисперсією: якщо даний стовпець у наборі даних має значення, які дуже мало змінюються, ви можете видалити його, оскільки він навряд чи запропонує стільки корисної інформації про змінну відповіді, скільки інші функції.
- Видаліть функції з низькою кореляцією зі змінною відповіді: якщо певна функція не сильно корелює зі змінною відповіді, яка вас цікавить, ви, ймовірно, можете видалити її з набору даних, оскільки це навряд чи є корисною функцією в моделі.
2. Використовуйте метод регулярізації.
Інший спосіб обробки багатовимірних даних без видалення функцій із набору даних полягає у використанні техніки регуляризації, такої як:
Кожну з цих методик можна використовувати для ефективної обробки багатовимірних даних.
На цій сторінці ви можете знайти повний список усіх посібників із статистичного машинного навчання.
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше