Дисперсійний аналіз (anova)
У цій статті пояснюється, що таке дисперсійний аналіз, також відомий як ANOVA, у статистиці. Отже, ви дізнаєтесь, як виконувати дисперсійний аналіз, що таке таблиця ANOVA та поетапне вирішення вправи. Крім того, він показує, які попередні припущення необхідно дотримуватися для виконання дисперсійного аналізу, і, нарешті, які переваги та недоліки аналізу ANOVA.
Що таке дисперсійний аналіз (ANOVA)?
У статистиці дисперсійний аналіз , також званий ANOVA (аналіз дисперсії), — це техніка, яка дозволяє порівнювати дисперсії середніх значень різних вибірок.
Дисперсійний аналіз (ANOVA) використовується для аналізу, чи існує різниця між середніми більш ніж двома генеральними сукупностями. Таким чином, дисперсійний аналіз дозволяє нам визначити, чи відрізняються середні сукупності двох або більше груп шляхом аналізу мінливості між вибірковими середніми.
Отже, нульова гіпотеза дисперсійного аналізу полягає в тому, що середні значення всіх проаналізованих груп є рівними. Тоді як альтернативна гіпотеза стверджує, що принаймні один із засобів є іншим.
![\begin{cases}H_0: \mu_1=\mu_2=\ldots=\mu_k=\mu\\[2ex]H_1: \exists \mu_i\neq \mu \quad i=1,2,\ldots, k\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-6918550a8ad2954432ea33e07c7b83d0_l3.png "Rendered by QuickLaTeX.com")
Таким чином, дисперсійний аналіз особливо корисний для порівняння середніх значень більш ніж двох груп, оскільки за допомогою цього типу аналізу ви можете досліджувати середні значення всіх груп одночасно, замість того, щоб порівнювати середні значення парами. Нижче ми побачимо переваги та недоліки дисперсійного аналізу.
Таблиця ANOVA
Дисперсійний аналіз узагальнено в таблиці під назвою ANOVA table , формули якої такі:
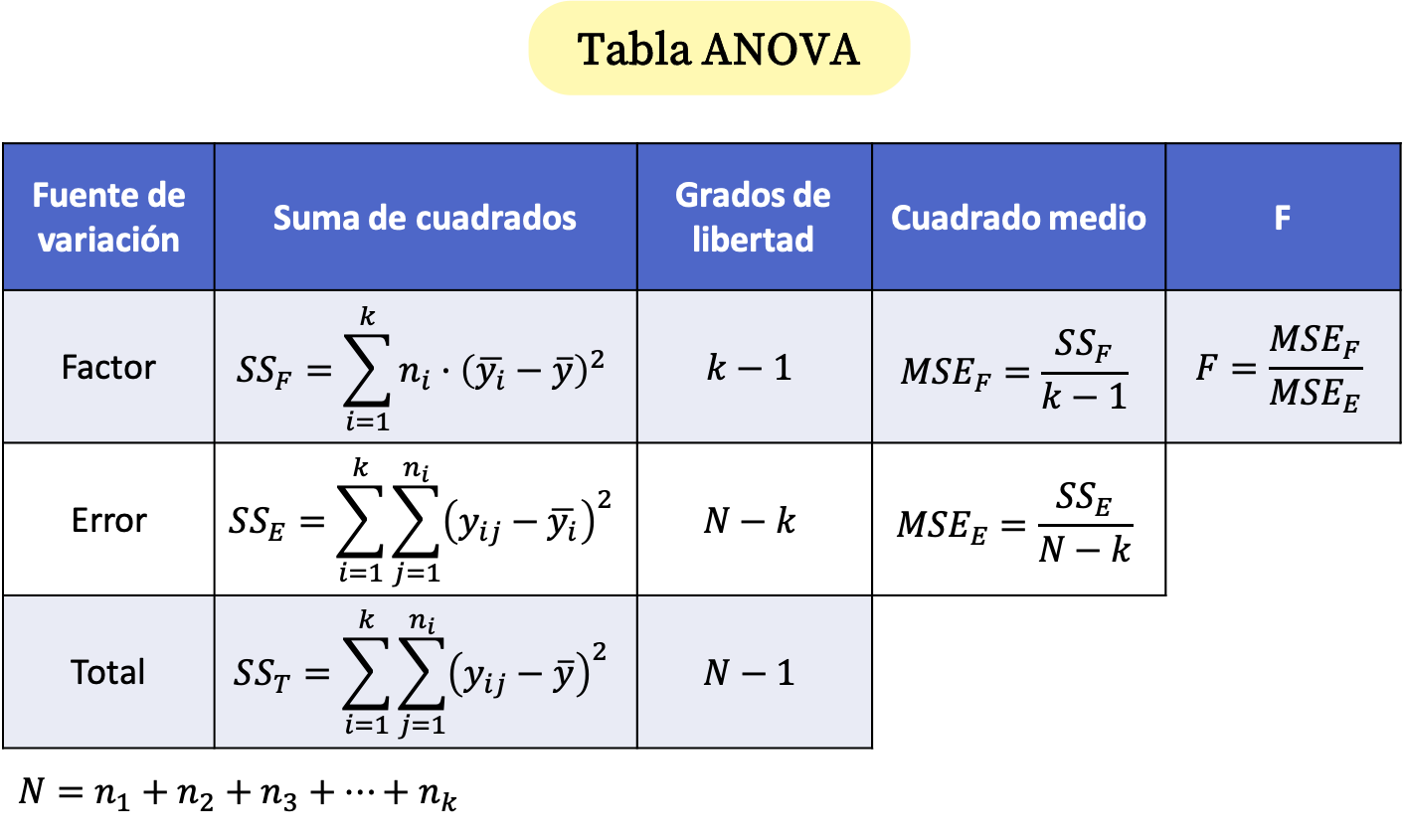
золото:
-

це розмір вибірки i.
-

– загальна кількість спостережень.
-

– кількість різних груп у дисперсійному аналізі.
-

є значення j групи i.
-

є середнім значенням групи i.
-

Це середнє значення всіх проаналізованих даних.
Приклад дисперсійного аналізу (ANOVA)
Щоб остаточно зрозуміти концепцію дисперсійного аналізу, давайте подивимося, як виконувати дисперсійний аналіз, розв’язуючи приклад крок за кроком.
- Проводиться статистичне дослідження для порівняння балів, отриманих чотирма учнями з трьох різних предметів (A, B і C). У наведеній нижче таблиці детально описано бали, отримані кожним учнем під час тестування з максимальним балом 20. Виконайте дисперсійний аналіз, щоб порівняти бали, отримані кожним учнем з кожного предмета.
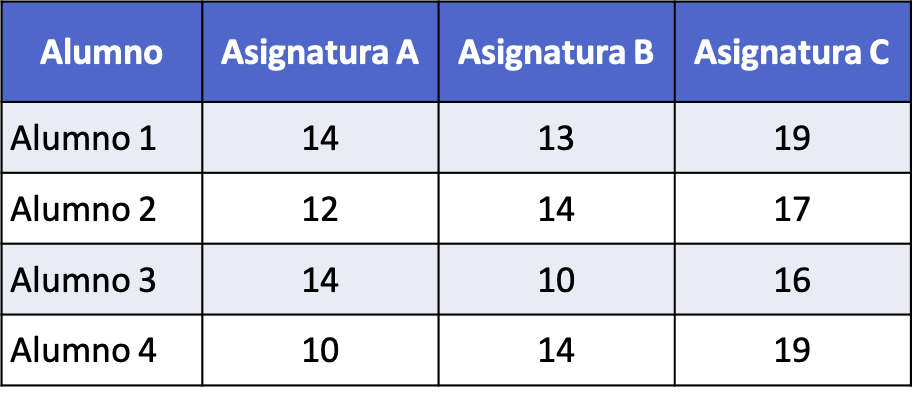
Нульова гіпотеза цього дисперсійного аналізу полягає в тому, що середні значення балів трьох предметів рівні. З іншого боку, нульова гіпотеза полягає в тому, що деякі з цих засобів відрізняються.
![\begin{cases}H_0: \mu_A=\mu_B=\mu_C=\mu\\[2ex]H_1: \exists \mu_i\neq \mu \quad i=A, B, C\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-d1587da405a54d6a2bae626989b04562_l3.png "Rendered by QuickLaTeX.com")
Щоб виконати дисперсійний аналіз, перше, що потрібно зробити, це обчислити середнє значення кожного суб’єкта та загальне середнє значення даних:




Коли ми знаємо значення середніх, ми обчислюємо суму квадратів за допомогою формул дисперсійного аналізу (ANOVA), наведених вище:
![\begin{aligned}\displaystyle SS_F&=\sum_{i=1}^k n_i(\overline{y}_i-\overline{y})^2\\[2ex] SS_F&= 4\cdot (12,5-14,33)^2+4\cdot (12,75-14,33)^2+4\cdot (17,75-14,33)^2\\[2ex] SS_F&=70,17\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-77b3fecdc3b577841da684cd80297288_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_E=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y}_i)^2\\[2ex] \displaystyle SS_E=\ &(14-12,5)^2+(12-12,5)^2+(14-12,5)^2+(10-12,5)^2+\\&+(13-12,75)^2+(14-12,75)^2+(10-12,75)^2+(14-12,75)^2+\\&+(19-17,75)^2+(17-17,75)^2+(16-17,75)^2+(19-17,75)^2\\[2ex] SS_E=\ &28,50\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-aa02f1b826df45c26ead3537ecc4c7e5_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_T=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y})^2\\[2ex] \displaystyle SS_T= \ &(14-14,33)^2+(12-14,33)^2+(14-14,33)^2+(10-14,33)^2+\\&+(13-14,33)^2+(14-14,33)^2+(10-14,33)^2+(14-14,33)^2+\\&+(19-14,33)^2+(17-14,33)^2+(16-14,33)^2+(19-14,33)^2\\[2ex] SS_T= \ &98,67\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-2eb66d1d37653749f38916c905108a3b_l3.png "Rendered by QuickLaTeX.com")
Потім визначаємо ступені свободи фактора, похибки та суми:



Тепер ми обчислюємо середні квадрати помилок, розділивши суми квадратів фактора та помилки на їхні відповідні ступені свободи:


І, нарешті, ми обчислюємо значення F-статистики, розділивши дві помилки, обчислені на попередньому кроці:

Коротко кажучи, таблиця дисперсійного аналізу для прикладу даних виглядатиме так:

Після того, як усі значення в таблиці ANOVA були обчислені, залишається лише інтерпретувати отримані результати. Для цього нам потрібно знайти ймовірність отримання значення, більшого за F-статистику, у F-розподілі Снедекора з відповідними ступенями свободи, тобто нам потрібно визначити p-значення тесту:
![P[F>11,08]=0,004″ title=”Rendered by QuickLaTeX.com” height=”18″ width=”172″ style=”vertical-align: -5px;”></p>
</p>
<p> Отже, якщо ми беремо рівень значущості α=0,05 (найпоширеніший), ми повинні відхилити нульову гіпотезу та прийняти альтернативну гіпотезу, оскільки p-значення тесту нижче за рівень значущості. Це означає, що принаймні деякі засоби досліджуваних груп відрізняються від інших.</p>
</p>
<p class=](https://statorials.org/wp-content/ql-cache/quicklatex.com-b706e5d710c3919d145399dc9d8efca5_l3.png)

Слід зазначити, що в даний час існує кілька комп’ютерних програм, які можуть виконувати дисперсійний аналіз всього за кілька секунд. Однак також важливо знати теорію, що лежить в основі розрахунків.
Припущення дисперсійного аналізу (ANOVA)
Щоб виконати дисперсійний аналіз (ANOVA), мають бути виконані такі умови:
- Незалежність : спостережувані значення не залежать одне від одного. Один із способів забезпечити незалежність спостережень – додати процесу вибірки випадковість.
- Гомоскедастичність : має бути однорідність у дисперсіях, тобто мінливість залишків є постійною.
- Нормальність : Залишки повинні бути нормально розподілені, або іншими словами, вони повинні відповідати нормальному розподілу.
- Безперервність : залежна змінна має бути безперервною.
Типи дисперсійного аналізу (ANOVA)
Існує три типи дисперсійного аналізу (ANOVA) :
- Односторонній дисперсійний аналіз (односторонній дисперсійний аналіз) : У дисперсійному аналізі є лише один фактор, тобто існує лише одна незалежна змінна.
- Двосторонній дисперсійний аналіз (двосторонній дисперсійний аналіз) : дисперсійний аналіз включає два фактори, тому аналізуються дві незалежні змінні та взаємодія між ними.
- Багатофакторний дисперсійний аналіз (MANOVA) : У дисперсійному аналізі існує більше однієї залежної змінної. Мета полягає в тому, щоб визначити, чи незалежні змінні змінюють своє значення, коли змінюються залежні змінні.
Переваги та недоліки дисперсійного аналізу (ANOVA)
Нарешті, ми побачимо, коли нам доцільно використовувати дисперсійний аналіз, а також, які межі цього типу статистичного аналізу.
Основна перевага дисперсійного аналізу (ANOVA) полягає в тому, що він дозволяє порівнювати більше двох груп одночасно. На відміну від t-критерію , де можна проаналізувати лише середнє значення однієї чи двох вибірок, дисперсійний аналіз використовується для визначення того, чи мають кілька сукупностей однакове середнє значення.
Однак дисперсійний аналіз не говорить нам, яка досліджувана група має інше середнє значення, він лише дає нам знати, чи існують суттєво різні середні значення, чи всі середні значення подібні.
Подібним чином, інший недолік дисперсійного аналізу полягає в тому, що чотири попередні припущення (див. вище) повинні бути виконані для виконання дисперсійного аналізу, інакше зроблені висновки можуть бути неправильними. Тому завжди слід перевіряти, чи набір статистичних даних відповідає цим чотирьом вимогам.
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше