Лінійний дискримінантний аналіз у python (крок за кроком)
Лінійний дискримінантний аналіз — це метод, який можна використовувати, якщо у вас є набір змінних-прогнозів і ви хочете класифікувати змінну відповіді на два або більше класів.
Цей підручник надає покроковий приклад того, як виконувати лінійний дискримінантний аналіз у Python.
Крок 1. Завантажте необхідні бібліотеки
Спочатку ми завантажимо функції та бібліотеки, необхідні для цього прикладу:
from sklearn. model_selection import train_test_split
from sklearn. model_selection import RepeatedStratifiedKFold
from sklearn. model_selection import cross_val_score
from sklearn. discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import datasets
import matplotlib. pyplot as plt
import pandas as pd
import numpy as np
Крок 2: Завантажте дані
Для цього прикладу ми використаємо набір даних райдужної оболонки ока з бібліотеки sklearn. Наступний код показує, як завантажити цей набір даних і перетворити його на pandas DataFrame для зручності використання:
#load iris dataset iris = datasets. load_iris () #convert dataset to pandas DataFrame df = pd.DataFrame(data = np.c_[iris[' data '], iris[' target ']], columns = iris[' feature_names '] + [' target ']) df[' species '] = pd. Categorical . from_codes (iris.target, iris.target_names) df.columns = [' s_length ', ' s_width ', ' p_length ', ' p_width ', ' target ', ' species '] #view first six rows of DataFrame df. head () s_length s_width p_length p_width target species 0 5.1 3.5 1.4 0.2 0.0 setosa 1 4.9 3.0 1.4 0.2 0.0 setosa 2 4.7 3.2 1.3 0.2 0.0 setosa 3 4.6 3.1 1.5 0.2 0.0 setosa 4 5.0 3.6 1.4 0.2 0.0 setosa #find how many total observations are in dataset len( df.index ) 150
Ми бачимо, що загалом набір даних містить 150 спостережень.
Для цього прикладу ми створимо модель лінійного дискримінантного аналізу, щоб класифікувати, до якого виду належить дана квітка.
У моделі ми будемо використовувати наступні змінні предиктора:
- Довжина чашолистка
- Ширина чашолистка
- Довжина пелюстки
- Ширина пелюстки
І ми використаємо їх, щоб передбачити змінну відповіді Species , яка підтримує такі три потенційні класи:
- сетоза
- лишай
- Вірджинія
Крок 3: Налаштуйте модель LDA
Далі ми підберемо модель LDA до наших даних за допомогою функції LinearDiscriminantAnalsys від sklearn:
#define predictor and response variables X = df[[' s_length ',' s_width ',' p_length ',' p_width ']] y = df[' species '] #Fit the LDA model model = LinearDiscriminantAnalysis() model. fit (x,y)
Крок 4. Використовуйте модель для прогнозування
Коли ми підігнали модель за допомогою наших даних, ми можемо оцінити продуктивність моделі за допомогою повторної стратифікованої k-кратної перехресної перевірки.
Для цього прикладу ми будемо використовувати 10 згинань і 3 повторення:
#Define method to evaluate model
cv = RepeatedStratifiedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
#evaluate model
scores = cross_val_score(model, X, y, scoring=' accuracy ', cv=cv, n_jobs=-1)
print( np.mean (scores))
0.9777777777777779
Ми бачимо, що модель досягла середньої точності 97,78% .
Ми також можемо використовувати модель, щоб передбачити, до якого класу належить нова квітка, на основі вхідних значень:
#define new observation new = [5, 3, 1, .4] #predict which class the new observation belongs to model. predict ([new]) array(['setosa'], dtype='<U10')
Ми бачимо, що модель передбачає, що це нове спостереження належить до виду під назвою setosa .
Крок 5: Візуалізуйте результати
Нарешті, ми можемо створити графік LDA, щоб візуалізувати лінійні дискримінанти моделі та візуалізувати, наскільки добре вона розділяє три різні види в нашому наборі даних:
#define data to plot X = iris.data y = iris.target model = LinearDiscriminantAnalysis() data_plot = model. fit (x,y). transform (X) target_names = iris. target_names #create LDA plot plt. figure () colors = [' red ', ' green ', ' blue '] lw = 2 for color, i, target_name in zip(colors, [0, 1, 2], target_names): plt. scatter (data_plot[y == i, 0], data_plot[y == i, 1], alpha=.8, color=color, label=target_name) #add legend to plot plt. legend (loc=' best ', shadow= False , scatterpoints=1) #display LDA plot plt. show ()
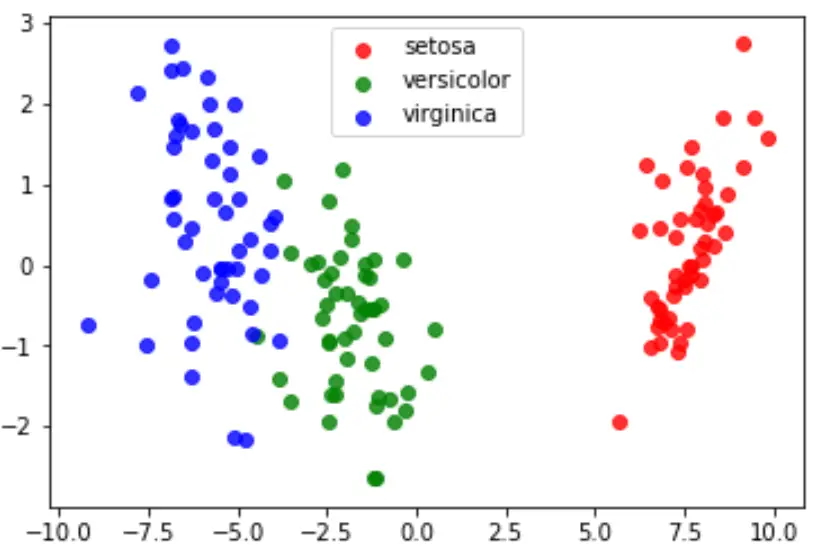
Ви можете знайти повний код Python, використаний у цьому посібнику, тут .
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше