Набір перевірки та набір тестів: у чому різниця?
Коли ми адаптуємо алгоритм машинного навчання до набору даних, ми зазвичай ділимо набір даних на три частини:
1. Навчальний набір : використовується для навчання моделі.
2. Набір перевірки : використовується для оптимізації параметрів моделі.
3. Тестовий набір : використовується для отримання неупередженої оцінки кінцевої продуктивності моделі.
Наступна діаграма надає візуальне пояснення цих трьох різних типів наборів даних:
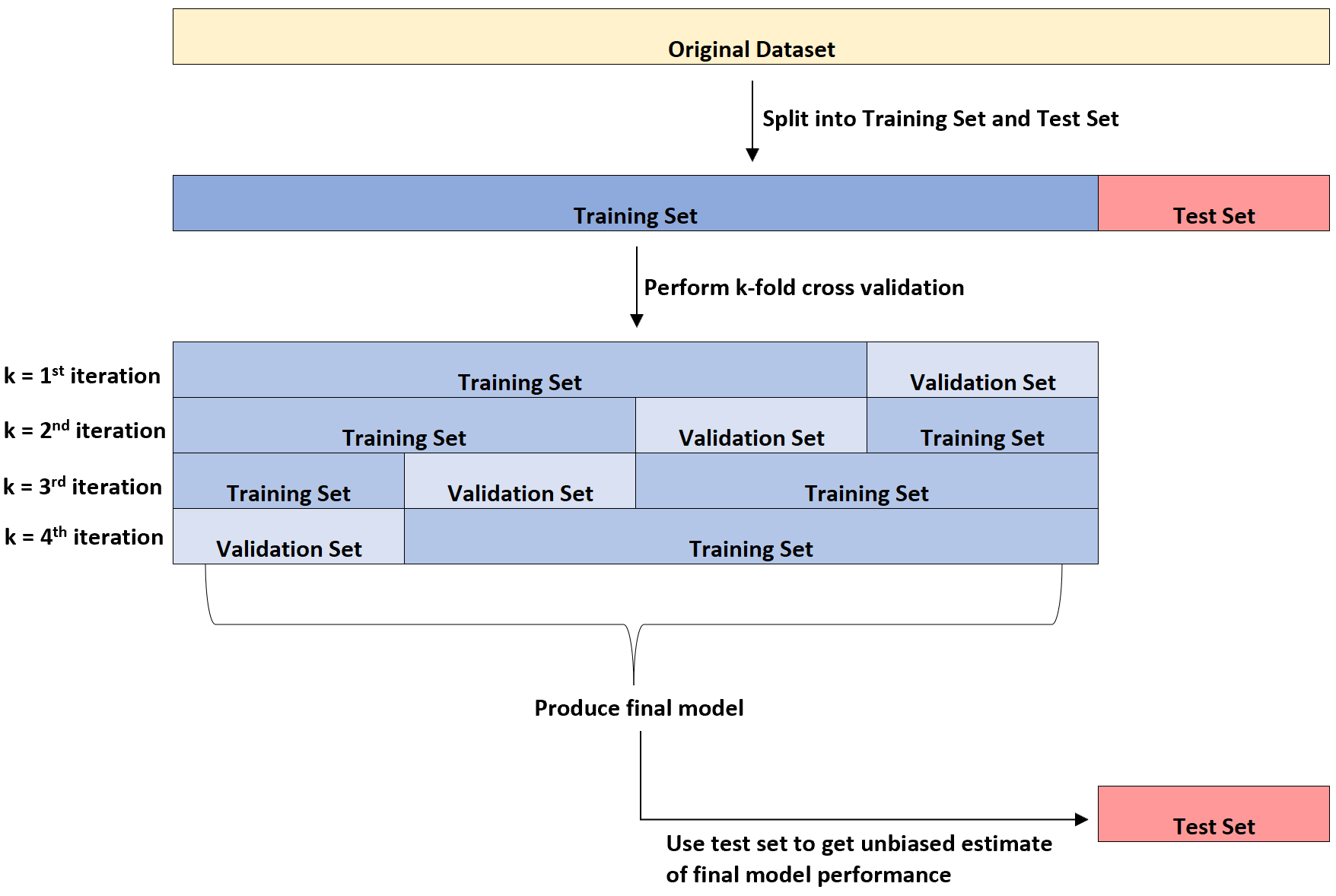
Одним з моментів плутанини для студентів є різниця між набором перевірки та тестовим набором.
Простіше кажучи, перевірочний набір використовується для оптимізації параметрів моделі, тоді як тестовий набір використовується для надання неупередженої оцінки кінцевої моделі.
Можна показати, що частота помилок, виміряна за допомогою k-кратної перехресної перевірки, має тенденцію недооцінювати справжню частоту помилок, коли модель застосовується до невидимого набору даних.
Таким чином, ми адаптуємо остаточну модель до набору тестів , щоб отримати неупереджену оцінку того, яким буде справжній рівень помилок у реальному світі.
Наступний приклад ілюструє різницю між перевірочним набором і тестовим набором на практиці.
Приклад: розуміння різниці між перевірочним набором і тестовим набором
Припустімо, інвестор у нерухомість хоче використати (1) кількість спалень, (2) загальну кількість квадратних футів і (3) кількість ванних кімнат, щоб передбачити ціну продажу даного будинку.
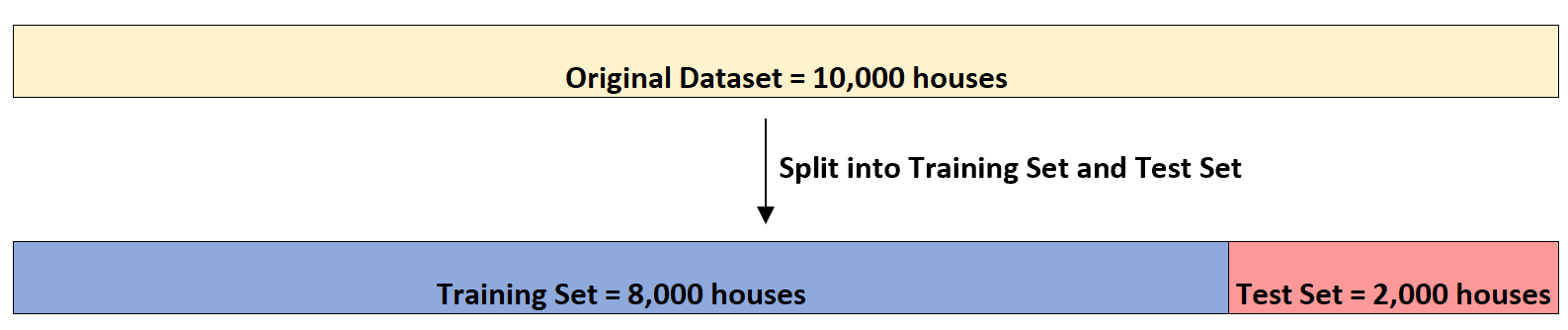
Скажімо, у нього є набір даних із цією інформацією про 10 000 будинків. По-перше, він розділить набір даних на навчальний набір з 8000 будинків і тестовий набір з 2000 будинків:
Тоді він чотири рази підбере модель множинної лінійної регресії до набору даних. Щоразу він використовуватиме 6000 будинків для навчального набору та 2000 будинків для перевірочного набору.
Це називається k-кратною перехресною перевіркою.
Навчальний набір використовується для навчання моделі, а набір перевірки використовується для оцінки продуктивності моделі. Кожного разу для набору перевірки буде використовуватися інша група з 2000 будинків.
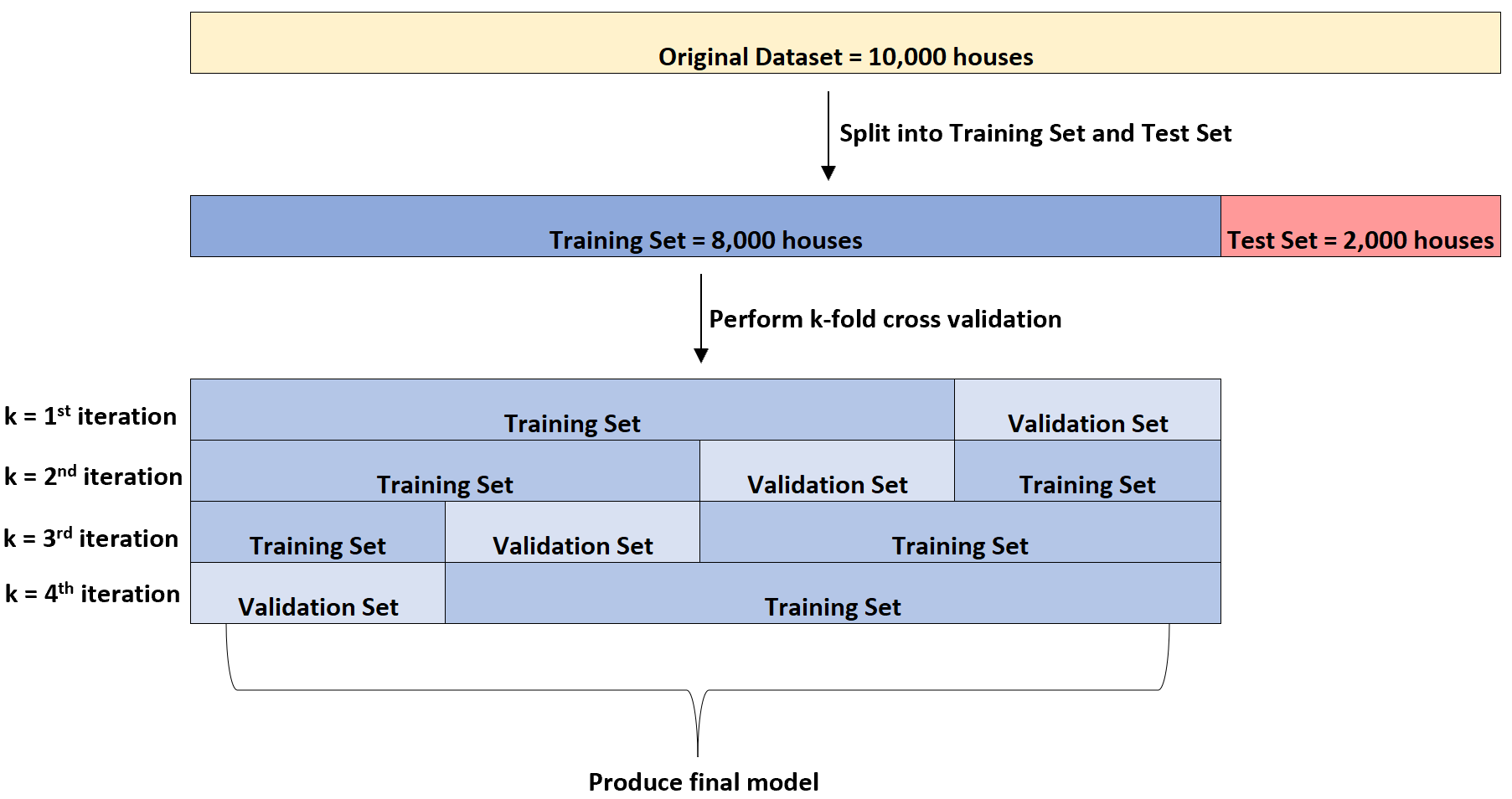
Він може виконувати цю k-кратну перехресну перевірку на кількох різних типах моделей регресії, щоб визначити модель, яка має найменшу помилку (тобто визначити модель, яка найкраще відповідає набору даних).
Лише після того, як він визначив найкращу модель, він використає набір для тестування на 2000 будинків, представлений на початку, щоб отримати неупереджену оцінку кінцевої продуктивності моделі.
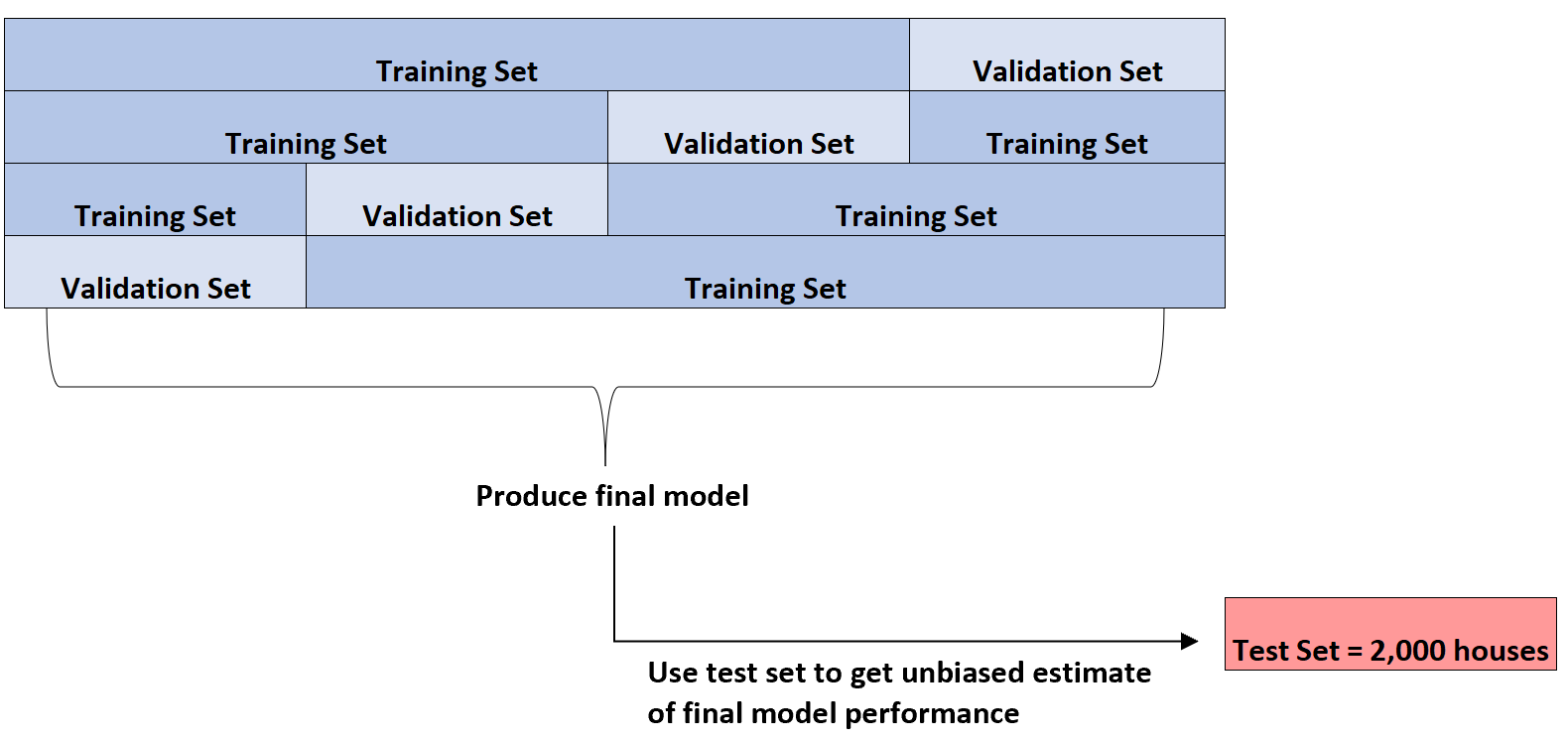
Наприклад, він може ідентифікувати конкретний тип регресійної моделі, середня абсолютна похибка якої становить 8,345 . Тобто середня абсолютна різниця між прогнозованою ціною житла та фактичною ціною житла становить 8345 дол.
Потім він може підібрати цю точну модель регресії до тестового набору з 2000 будинків, який ще не використовувався, і виявити, що середня абсолютна похибка моделі становить 8,847 .
Таким чином, неупереджена оцінка істинної середньої абсолютної похибки моделі становить 8847 доларів.
Додаткові ресурси
Простий посібник із перехресної перевірки K-Fold
Як виконати перехресну перевірку K-Fold у Python
Як виконати перехресну перевірку K-Fold у R
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше