Як отримати прогнозовані значення та залишки в stata
Лінійна регресія – це метод, який ми можемо використати для розуміння зв’язку між однією або декількома пояснювальними змінними та змінною відповіді.
Коли ми виконуємо лінійну регресію на наборі даних, ми отримуємо рівняння регресії, яке можна використовувати для прогнозування значень змінної відповіді за значеннями пояснювальних змінних.
Потім ми можемо виміряти різницю між прогнозованими значеннями та фактичними значеннями, щоб отримати залишки для кожного прогнозу. Це допомагає нам отримати уявлення про те, наскільки добре наша регресійна модель передбачає значення відповіді.
У цьому підручнику пояснюється, як отримати як прогнозовані значення , так і залишки для моделі регресії в Stata.
Приклад: як отримати прогнозовані значення та залишки
Для цього прикладу ми використаємо вбудований набір даних Stata під назвою auto . Ми будемо використовувати милі на галон і об’єм як пояснювальні змінні, а ціну – як змінну відповіді.
Виконайте наступні кроки, щоб виконати лінійну регресію, а потім отримати прогнозовані значення та залишки для моделі регресії.
Крок 1: Завантажте та відобразіть дані.
Спочатку ми завантажимо дані за допомогою такої команди:
автоматичне використання системи
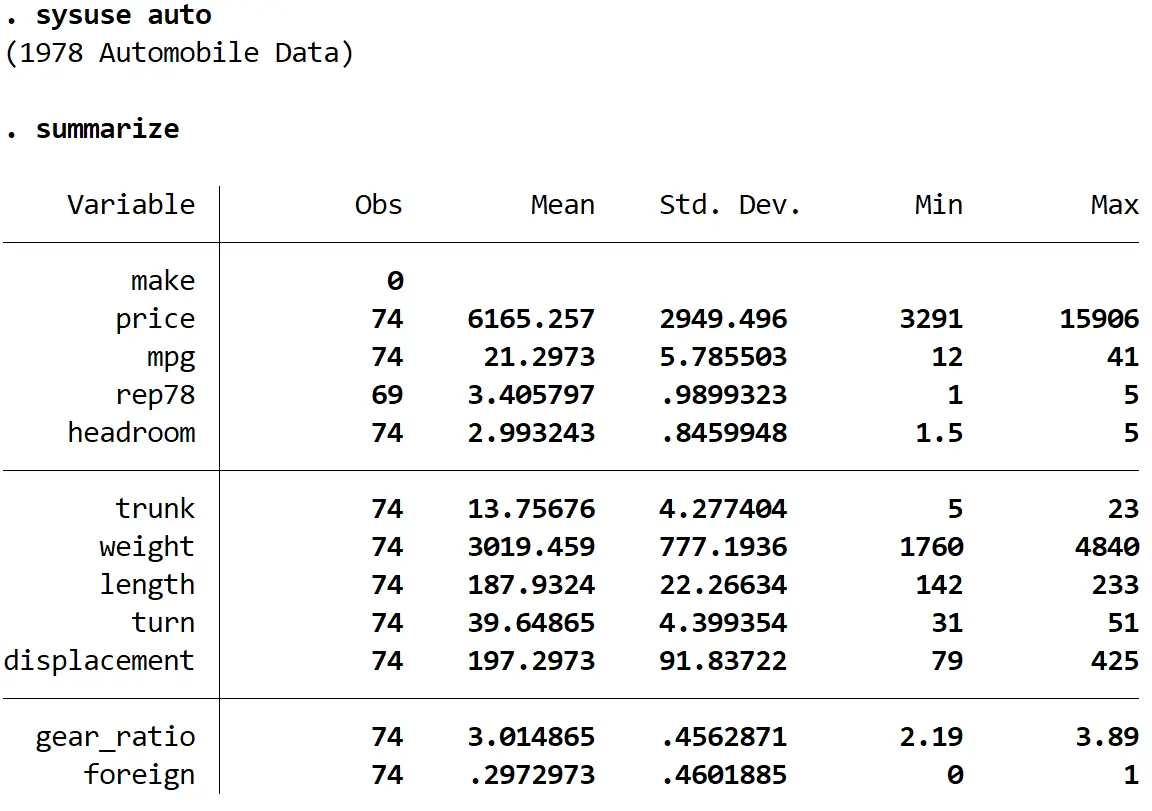
Далі ми отримаємо короткий підсумок даних за допомогою такої команди:
узагальнити
Крок 2. Підберіть регресійну модель.
Далі ми використаємо таку команду, щоб підібрати регресійну модель:
регресія ціна миль на галон об’єм
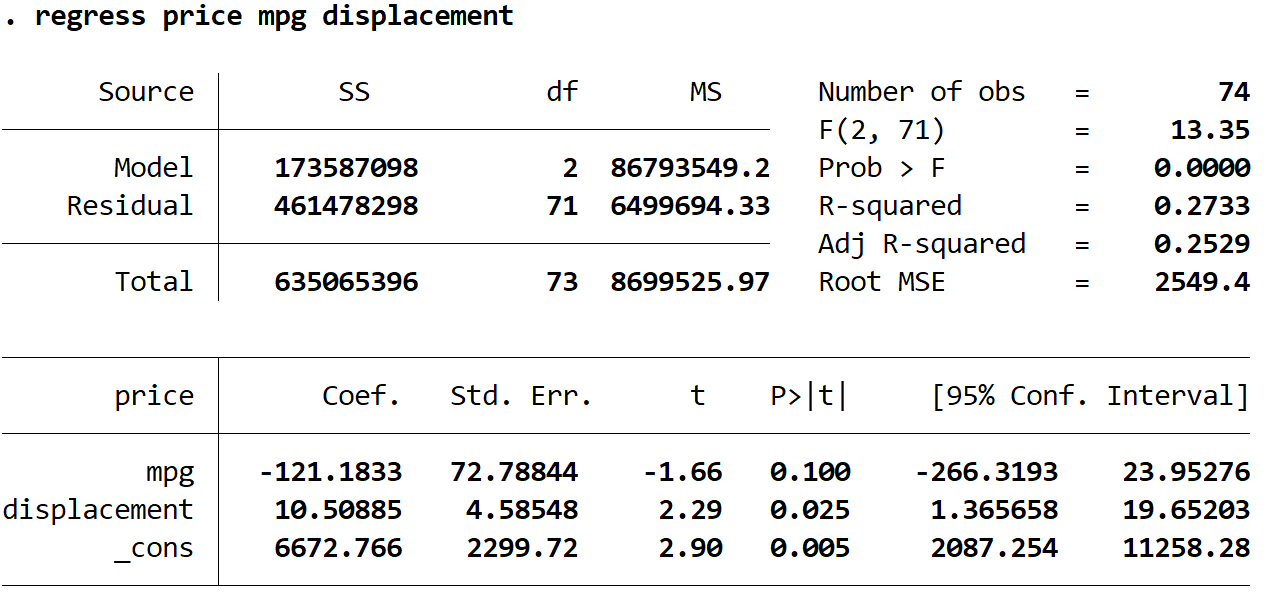
Розраховане рівняння регресії:
орієнтовна ціна = 6672,766 -121,1833*(милі на галлон) + 10,50885*(об’єм двигуна)
Крок 3: Отримайте прогнозовані значення.
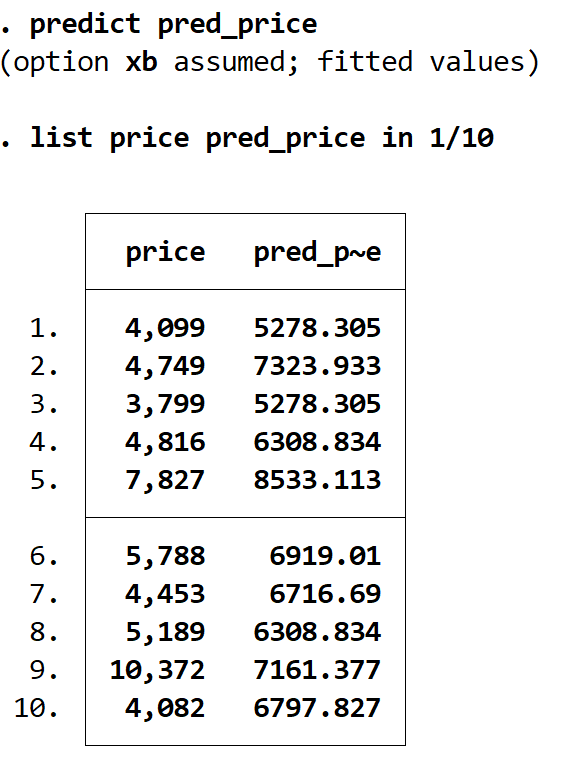
Ми можемо отримати прогнозовані значення, використовуючи команду predict і зберігаючи ці значення в змінній з іменем, яке ми хочемо. У цьому випадку ми будемо використовувати назву pred_price :
передбачити pred_price
Ми можемо відображати фактичні ціни та прогнозовані ціни поруч за допомогою команди списку . Всього передбачено 74 значення, але ми відобразимо лише перші 10 за допомогою команди in 1/10 :
прейскурант pred_price в 1/10
Крок 4: Отримайте залишок.
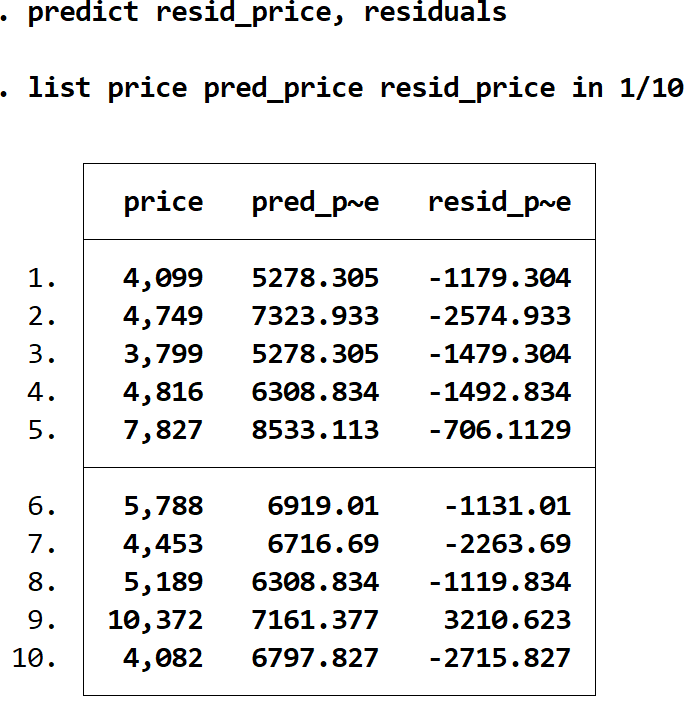
Ми можемо отримати залишки кожного прогнозу, використовуючи команду residuals і зберігаючи ці значення в змінній з будь-яким ім’ям. У цьому випадку ми будемо використовувати назву resid_price :
передбачити residency_price, залишки
Ми можемо відобразити фактичну ціну, очікувану ціну та залишки поруч за допомогою команди list :
роздрібна ціна pred_price resid_price в 1/10
Крок 5: Створіть графік прогнозованих значень проти залишків.
Нарешті, ми можемо створити діаграму розсіювання, щоб візуалізувати зв’язок між прогнозованими значеннями та залишками:
дисперсія reside_price pred_price
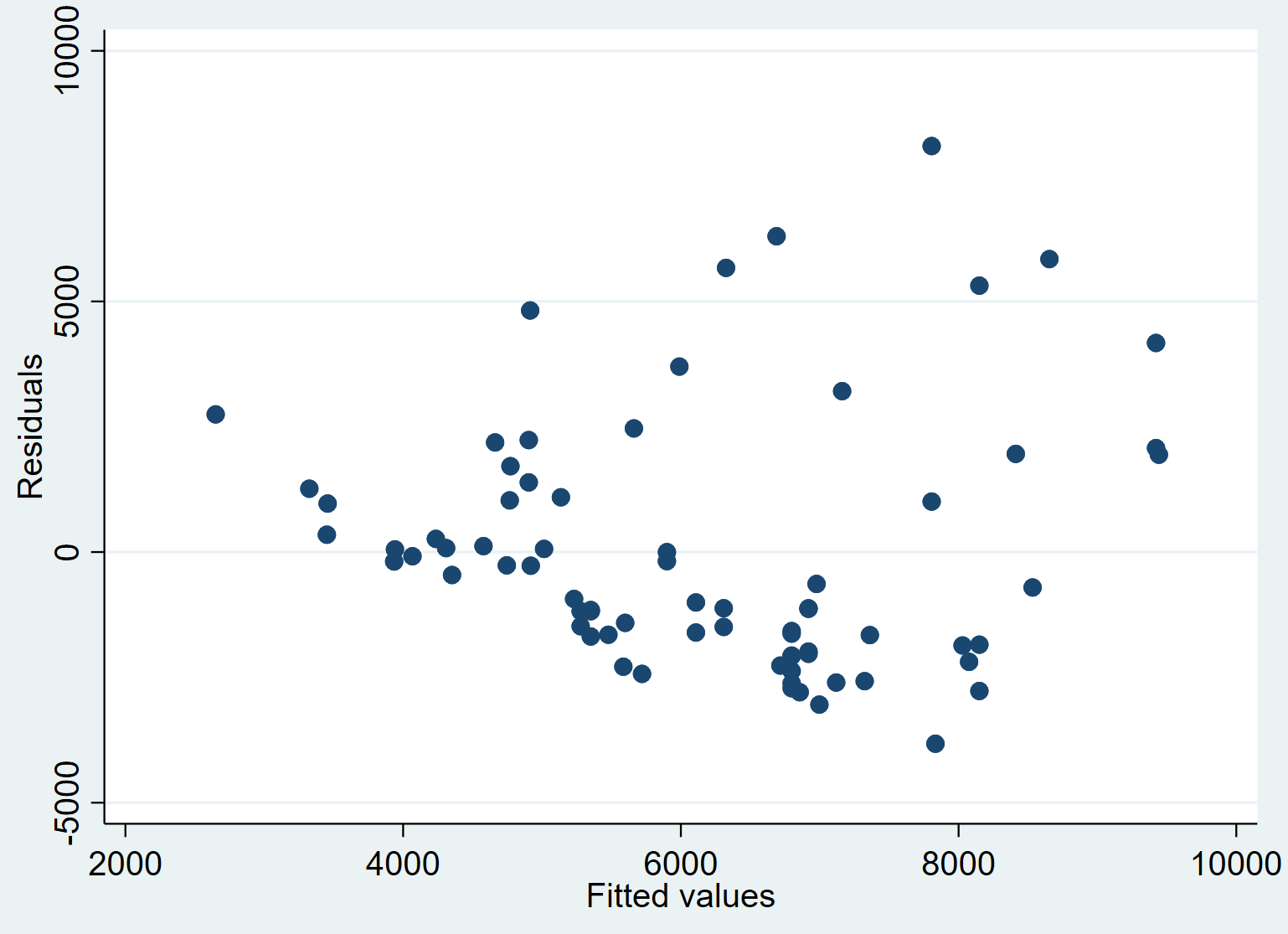
Ми бачимо, що в середньому залишки мають тенденцію до збільшення зі збільшенням підігнаних значень. Це може бути ознакою гетероскедастичності – коли розподіл залишків не є постійним на кожному рівні відповіді.
Ми могли б формально перевірити гетероскедастичність за допомогою тесту Брейша-Пейгана та вирішити це за допомогою стійких стандартних помилок .
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше