Як обчислити стандартну помилку середнього в excel
Стандартна помилка середнього — це спосіб вимірювання розподілу значень у наборі даних. Він розраховується таким чином:
Стандартна похибка = s / √n
золото:
- s : вибіркове стандартне відхилення
- n : розмір вибірки
Стандартну помилку середнього будь-якого набору даних у Excel можна обчислити за такою формулою:
= STDEV (діапазон значень) / SQRT ( COUNT (діапазон значень))
У наступному прикладі показано, як використовувати цю формулу.
Приклад: стандартна помилка в Excel
Припустимо, ми маємо наступний набір даних:
На наступному знімку екрана показано, як обчислити стандартну помилку середнього для цього набору даних:
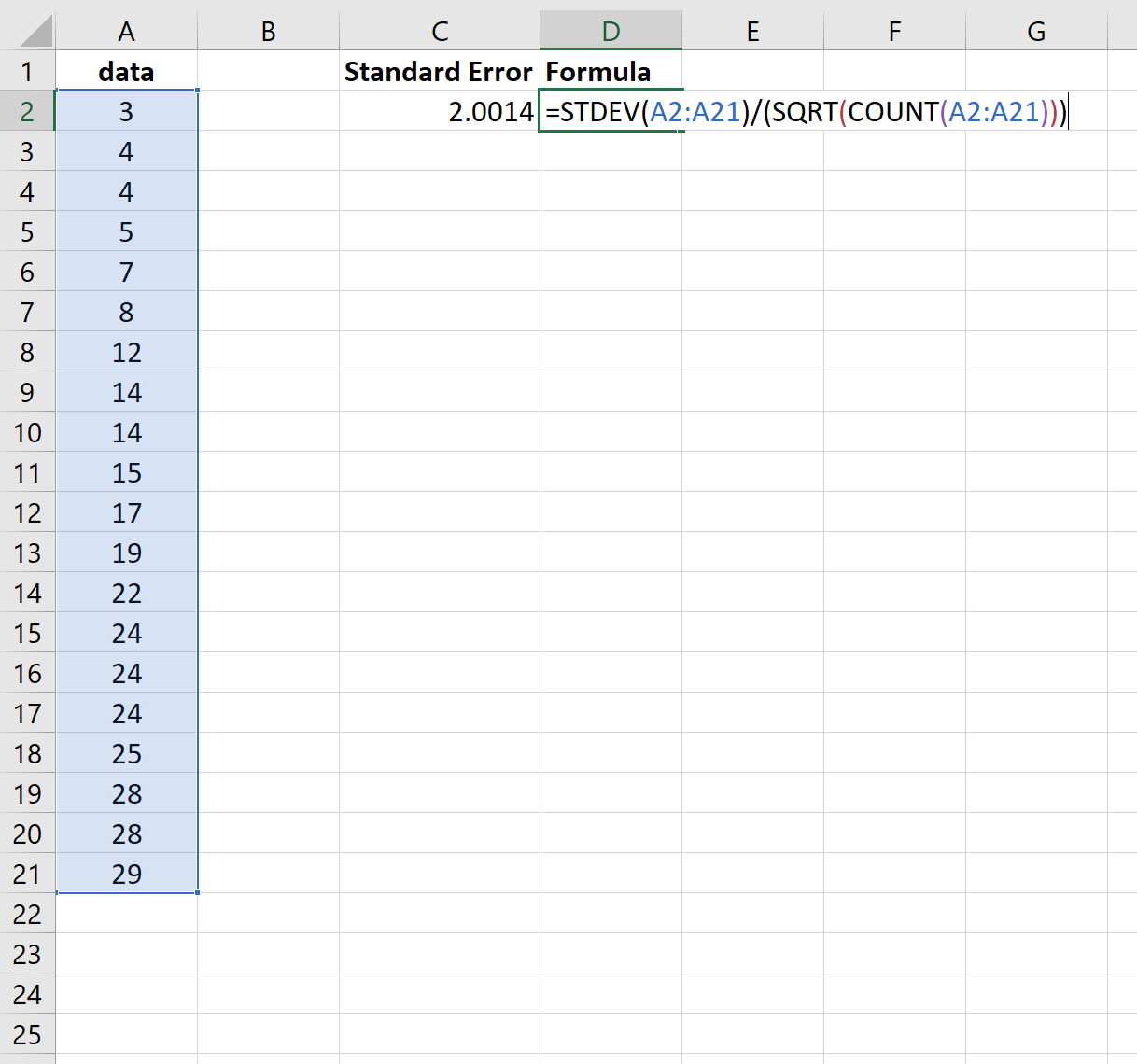
Стандартна помилка виявляється 2,0014 .
Зауважте, що функція =STDEV() обчислює вибіркове середнє значення, яке еквівалентно функції =STDEV.S() в Excel.
Отже, ми могли б використати таку формулу, щоб отримати ті самі результати:
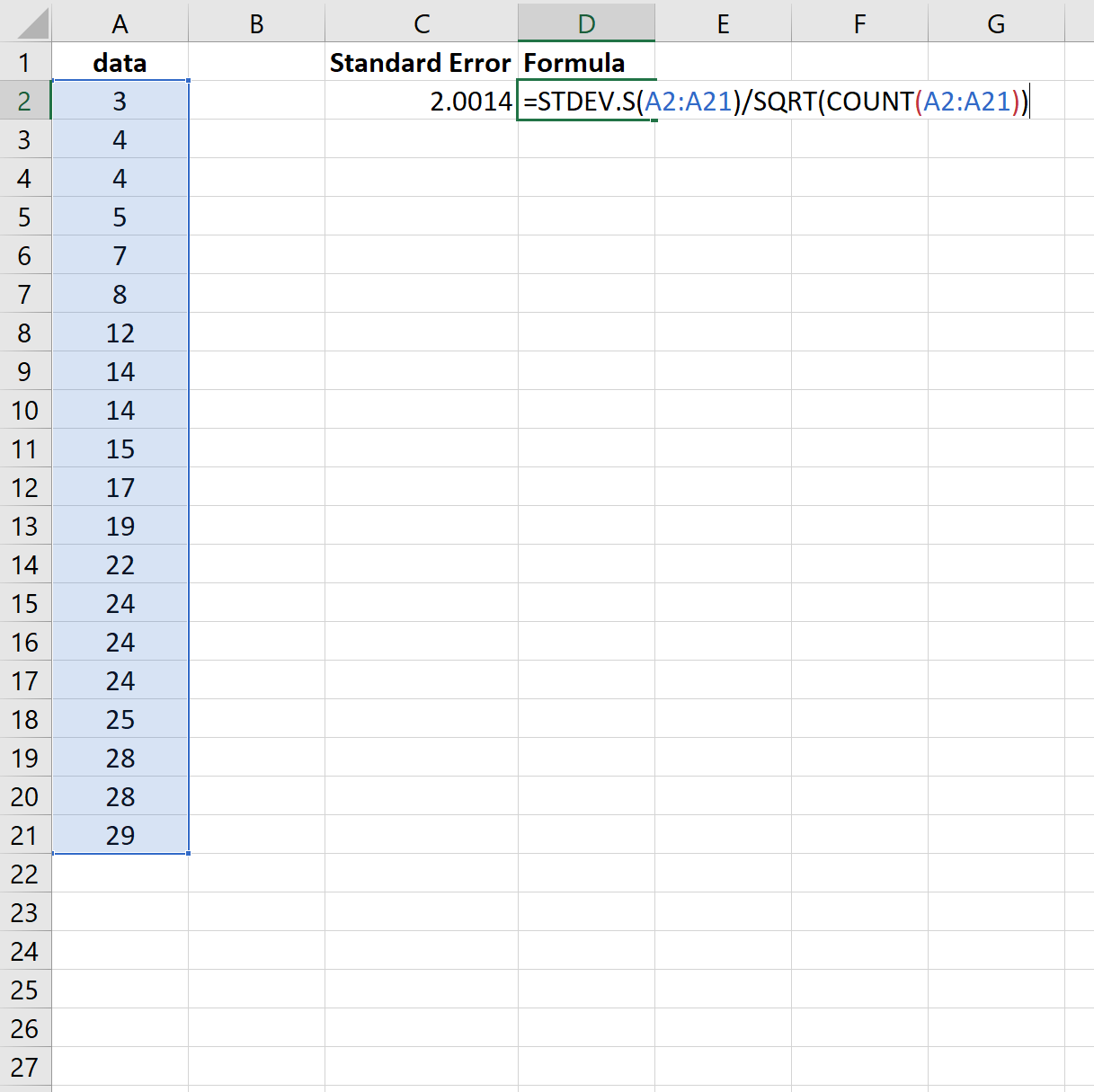
І знову стандартна помилка дорівнює 2,0014 .
Як інтерпретувати стандартну помилку середнього
Стандартна помилка середнього — це просто міра розкиду значень навколо середнього. Інтерпретуючи стандартну помилку середнього, слід пам’ятати про дві речі:
1. Чим більша стандартна помилка середнього значення, тим більше розкидані значення навколо середнього в наборі даних.
Щоб проілюструвати це, розглянемо, якщо ми змінимо останнє значення попереднього набору даних на набагато більше число:
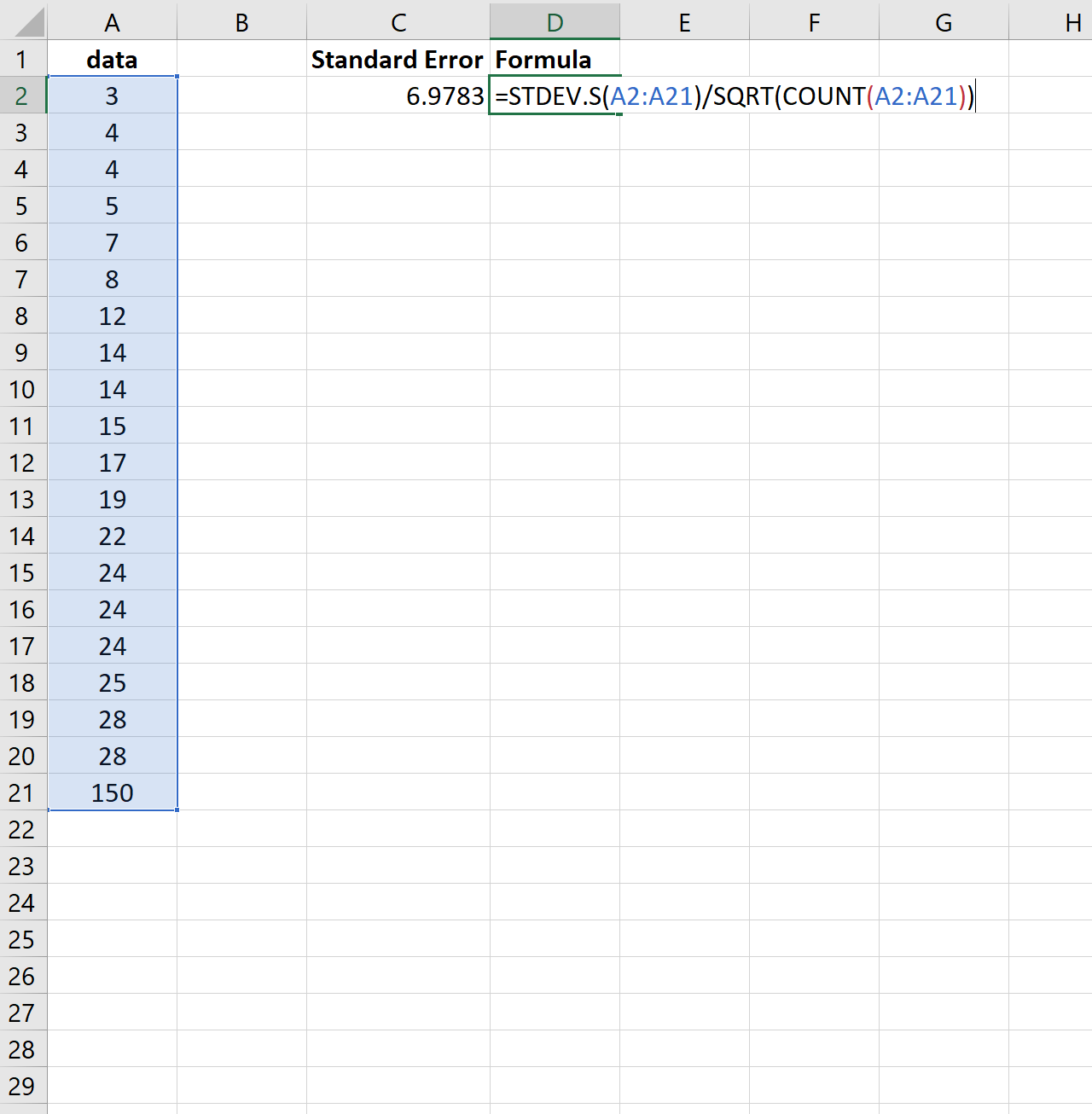
Зверніть увагу, як стандартна помилка зростає з 2,0014 до 6,9783 . Це вказує на те, що значення в цьому наборі даних більш розподілені навколо середнього порівняно з попереднім набором даних.
2. Зі збільшенням розміру вибірки стандартна помилка середнього має тенденцію до зменшення.
Щоб проілюструвати це, розглянемо стандартну помилку середнього для наступних двох наборів даних:
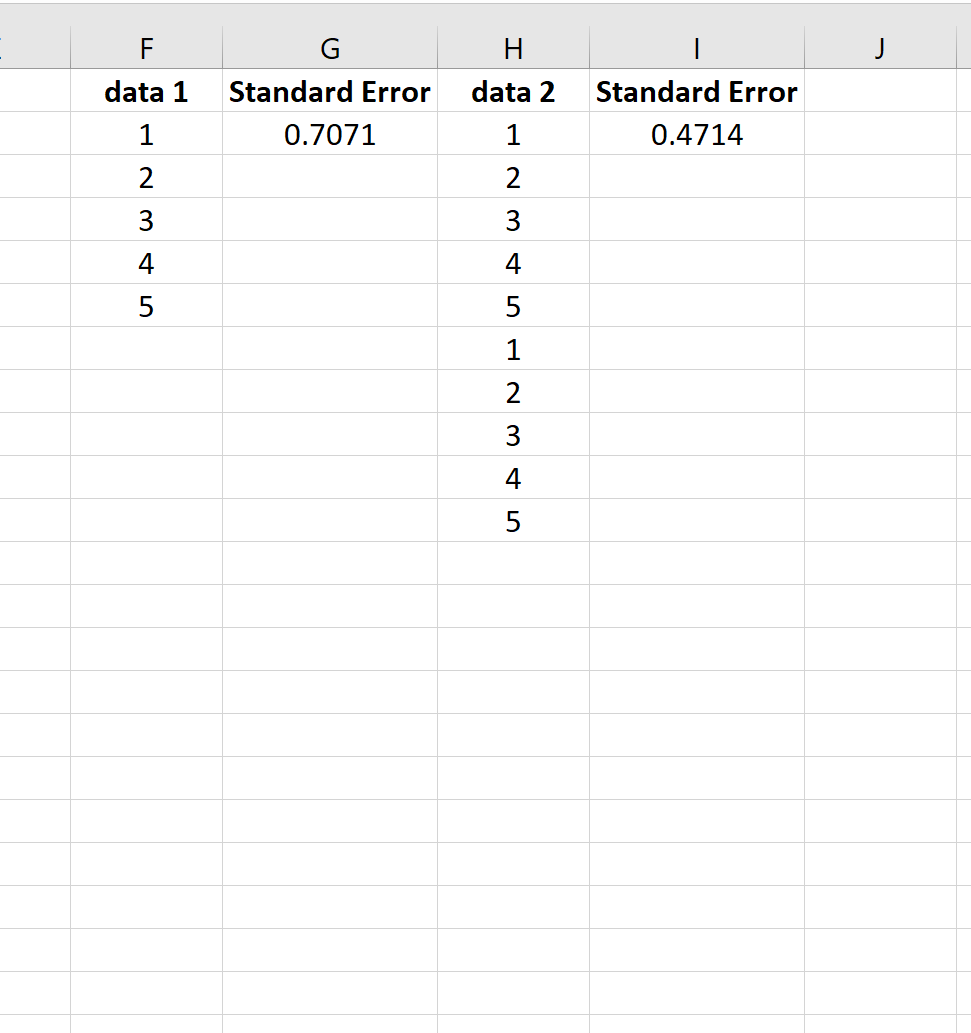
Другий набір даних — це просто перший набір даних, повторений двічі. Отже, обидва набори даних мають однакове середнє значення, але другий набір даних має більший розмір вибірки і, отже, має меншу стандартну помилку.
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше