Випадковий вибір або випадкове призначення
Випадковий вибір і випадкове призначення є двома статистичними методами, які часто використовуються, але їх часто плутають.
Випадковий відбір стосується процесу випадкового відбору осіб із популяції для участі в дослідженні.
Випадковий розподіл відноситься до процесу випадкового розподілу осіб, які беруть участь у дослідженні, до групи лікування або контрольної групи.
Ви можете розглядати випадковий відбір як процес, який ви використовуєте, щоб «залучити» людей до дослідження, а випадковий розподіл — це те, що ви «робите» з цими особами після того, як їх вибрано для участі в дослідженні.
Важливість випадкового вибору та випадкового призначення
Коли в дослідженні використовується випадковий відбір , воно вибирає осіб із популяції за допомогою випадкового процесу. Наприклад, якщо популяція складається з 1000 осіб, ми можемо використовувати комп’ютер, щоб випадковим чином вибрати 100 із цих осіб із бази даних. Це означає, що кожна особа має однакову ймовірність бути обраною для участі в дослідженні, що збільшує шанси отримати репрезентативну вибірку – таку з характеристиками, подібними до загальної сукупності.
Використовуючи репрезентативну вибірку в нашому дослідженні, ми можемо узагальнити результати нашого дослідження для населення. У статистичних термінах це називається мати зовнішню валідність – це дійсне екстерналізувати наші результати для загальної сукупності.
Коли в дослідженні використовується випадковий розподіл , воно випадковим чином призначає осіб до групи лікування або контрольної групи. Наприклад, якщо ми маємо 100 осіб у дослідженні, ми можемо використовувати генератор випадкових чисел, щоб випадковим чином розподілити 50 осіб до контрольної групи та 50 осіб до групи лікування.
Використовуючи випадковий розподіл, ми збільшуємо ймовірність того, що дві групи матимуть приблизно однакові характеристики, тобто будь-які відмінності, які спостерігаються між двома групами, можна віднести до лікування. Це означає, що дослідження має внутрішню валідність : можна віднести будь-які відмінності між групами до самого лікування, на відміну від відмінностей між окремими особами в групах.
Приклади випадкового вибору та випадкового призначення
У дослідженні можна використовувати як випадковий вибір, так і випадкове призначення, або лише одну з цих методик, або жодну. Потужне дослідження – це те, у якому використовуються обидві методики.
Наведені нижче приклади показують, як дослідження може використовувати обидва, один або жоден із цих методів, а також результати, що виникають.
Приклад 1: використання як випадкового вибору, так і випадкового призначення
Дослідження: дослідники хочуть знати, чи нова дієта призводить до більшої втрати ваги, ніж стандартна дієта в певній громаді з 10 000 людей. Вони набирають 100 людей для участі в дослідженні, використовуючи комп’ютер для випадкового вибору 100 імен із бази даних. Отримавши всі 100 осіб, вони знову використовують комп’ютер, щоб випадковим чином розподілити 50 осіб до контрольної групи (наприклад, дотримуючись стандартної дієти) і 50 осіб до групи лікування (наприклад, дотримуючись нової дієти). Вони реєструють загальну втрату ваги кожної людини через один місяць.
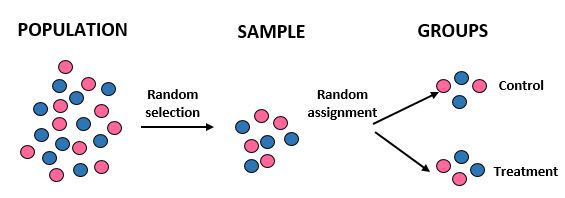
Результати: Дослідники використовували випадковий відбір, щоб отримати вибірку та випадковий розподіл під час розміщення осіб у лікувальній або контрольній групі. Роблячи це, вони можуть узагальнити результати дослідження на загальну популяцію та віднести різницю в середній втраті ваги між двома групами до нової дієти.
Приклад 2: використовуйте лише випадковий вибір
Дослідження: дослідники хочуть знати, чи нова дієта призводить до більшої втрати ваги, ніж стандартна дієта в певній громаді з 10 000 людей. Вони набирають 100 людей для участі в дослідженні, використовуючи комп’ютер для випадкового вибору 100 імен із бази даних. Однак вони вирішують розділити людей на групи виключно за статтю. До контрольної групи відносять жінок, до лікувальної — чоловіків. Вони реєструють загальну втрату ваги кожної людини через один місяць.
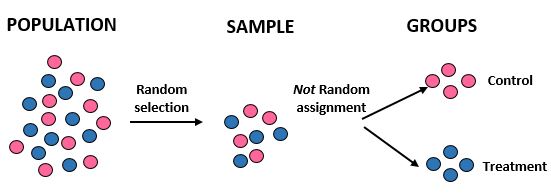
Результати: Дослідники використовували випадковий відбір, щоб отримати свою вибірку, але вони не використовували випадковий розподіл, коли поміщали людей у лікувальну або контрольну групу. Замість цього вони використовували певний фактор – стать – щоб вирішити, до якої групи віднести людей. Роблячи це, вони можуть узагальнити результати дослідження на загальну популяцію, але вони не можуть віднести відмінності в середній втраті ваги між двома групами до нової дієти. Внутрішня достовірність дослідження була скомпрометована, оскільки різниця у втраті ваги насправді могла бути просто спричинена статтю, а не новою дієтою.
Приклад 3: використовуйте лише випадкове призначення
Дослідження: дослідники хочуть знати, чи нова дієта призводить до більшої втрати ваги, ніж стандартна дієта в певній громаді з 10 000 людей. Вони набирають 100 чоловіків-спортсменів для участі в дослідженні. Потім вони використовують комп’ютерну програму для випадкового розподілу 50 спортсменів-чоловіків до контрольної групи та 50 до групи лікування. Вони реєструють загальну втрату ваги кожної людини через один місяць.
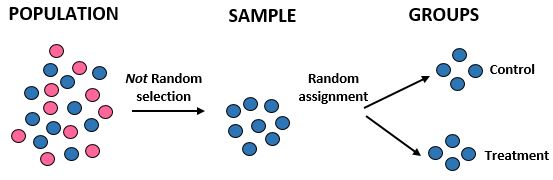
Результати: дослідники не використовували випадковий відбір, щоб отримати свою вибірку, оскільки вони спеціально вибрали 100 спортсменів-чоловіків. З цієї причини їхня вибірка не є репрезентативною для загальної сукупності, тому їх зовнішня валідність скомпрометована – вони не зможуть узагальнити результати дослідження для загальної сукупності. Однак вони використали випадковий розподіл, тобто вони можуть віднести будь-яку різницю у втраті ваги до нової дієти.
Приклад 4: не використовуйте жодну техніку
Дослідження: дослідники хочуть знати, чи нова дієта призводить до більшої втрати ваги, ніж стандартна дієта в певній громаді з 10 000 людей. Вони набирають 50 спортсменів-чоловіків і 50 спортсменок-жінок для участі в дослідженні. Потім вони відносять усіх спортсменок до контрольної групи, а всіх спортсменів-чоловіків — до групи лікування. Вони реєструють загальну втрату ваги кожної людини через один місяць.
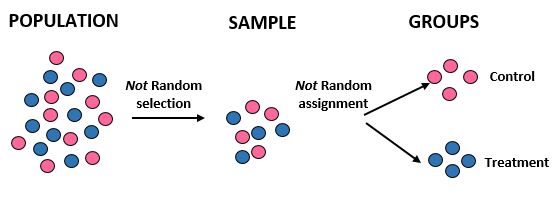
Результати: Дослідники не використовували випадковий відбір, щоб отримати свою вибірку, оскільки вони спеціально обрали 100 спортсменів. З цієї причини їхня вибірка не є репрезентативною для загальної сукупності, тому їх зовнішня валідність скомпрометована – вони не зможуть узагальнити результати дослідження для загальної сукупності. Крім того, вони поділяють людей на групи за статтю, а не покладаються на випадковий розподіл, що означає, що їх внутрішня валідність також скомпрометована – відмінності у втраті ваги можуть бути наслідком статі, а не дієти.
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше