Як обчислити зважене стандартне відхилення в python
Зважене стандартне відхилення є корисним способом вимірювання дисперсії значень у наборі даних, коли деякі значення в наборі даних мають вищу вагу, ніж інші.
Формула для обчислення зваженого стандартного відхилення:
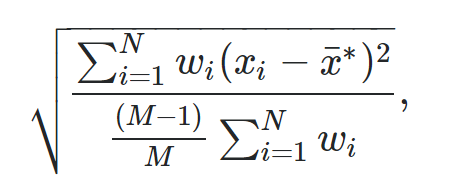
золото:
- N: Загальна кількість спостережень
- M: кількість ненульових ваг
- w i : вектор ваги
- x i : вектор значень даних
- x : Середньозважене значення
Найпростіший спосіб обчислити зважене стандартне відхилення в Python — це використати функцію DescrStatsW() із пакету statsmodels:
DescrStatsW(values, weights=weights, ddof= 1 ). std
У наступному прикладі показано, як використовувати цю функцію на практиці.
Приклад: зважене стандартне відхилення в Python
Припустимо, що у нас є наступний масив значень даних і відповідні ваги:
#define data values values = [14, 19, 22, 25, 29, 31, 31, 38, 40, 41] #define weights weights = [1, 1, 1.5, 2, 2, 1.5, 1, 2, 3, 2]
У наступному коді показано, як обчислити зважене стандартне відхилення для цього масиву значень даних:
from statsmodels. stats . weightstats import DescrStatsW
#calculate weighted standard deviation
DescrStatsW(values, weights=weights, ddof= 1 ). std
8.570050878426773
Зважене стандартне відхилення виявляється рівним 8,57 .
Зверніть увагу, що ми також можемо використовувати var для швидкого обчислення зваженої дисперсії:
from statsmodels. stats . weightstats import DescrStatsW
#calculate weighted variance
DescrStatsW(values, weights=weights, ddof= 1 ). var
73.44577205882352
Зважена дисперсія виявляється 73 446 .
Додаткові ресурси
У наступних посібниках пояснюється, як обчислити зважене стандартне відхилення в іншому статистичному програмному забезпеченні:
Як обчислити зважене стандартне відхилення в Excel
Як обчислити зважене стандартне відхилення в R
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше