Короткий вступ до навчання під контролем і без нього
Сфера машинного навчання містить величезний набір алгоритмів, які можна використовувати для розуміння даних. Ці алгоритми можна класифікувати в одну з наступних двох категорій:
1. Алгоритми навчання під наглядом: передбачають створення моделі для оцінки або прогнозування результату на основі одного або кількох вхідних даних.
2. Алгоритми навчання без контролю: включають пошук структури та зв’язків із вхідних даних. Виходу «нагляду» немає.
У цьому посібнику пояснюється різниця між цими двома типами алгоритмів разом із кількома прикладами кожного.
Алгоритми навчання під контролем
Алгоритм навчання під наглядом може бути використаний , якщо у нас є одна або кілька пояснювальних змінних ( X1, змінна відповіді:
Y = f (X) + ε
де f представляє систематичну інформацію, яку X надає про Y, і де ε є випадковою помилкою, незалежною від X із середнім значенням нуля.
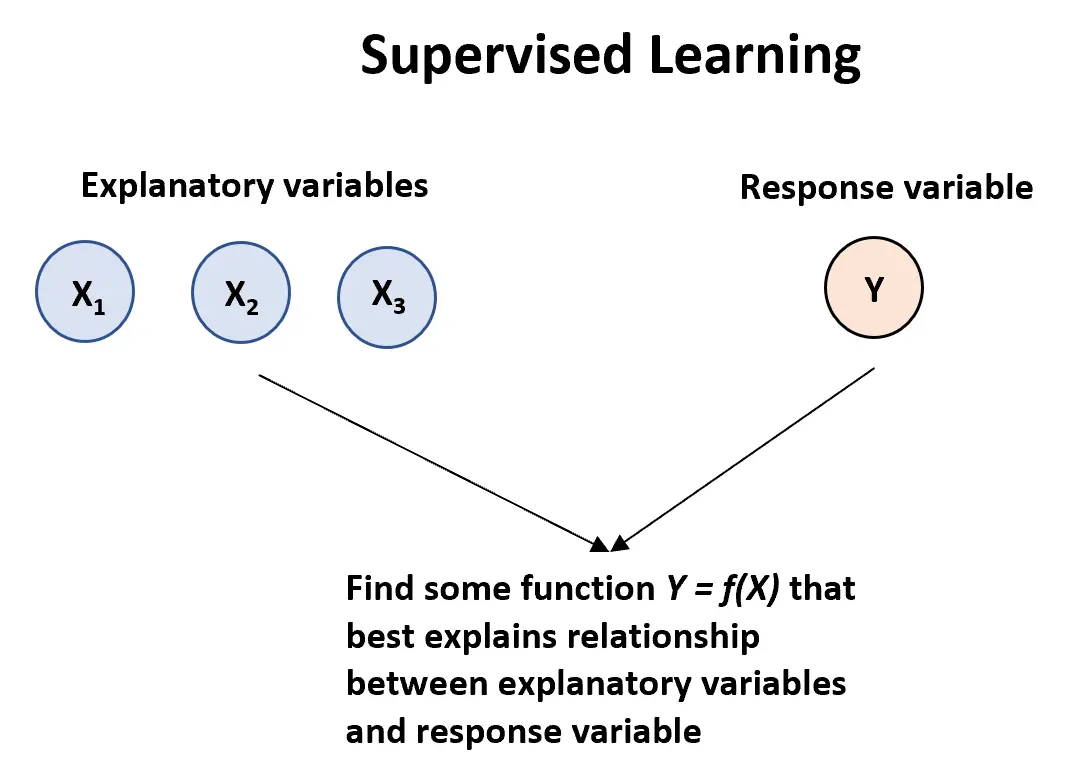
Існує два основних типи алгоритмів навчання під наглядом:
1. Регресія: вихідна змінна є постійною (наприклад, вага, зріст, час тощо)
2. Класифікація: вихідна змінна є категоричною (наприклад, чоловік чи жінка, успіх чи невдача, доброякісний чи злоякісний тощо)
Існує дві основні причини, чому ми використовуємо алгоритми навчання під наглядом:
1. Прогноз: ми часто використовуємо набір пояснювальних змінних, щоб передбачити значення змінної відповіді (наприклад, використовуючи квадратні метри та кількість спалень , щоб передбачити ціну будинку ).
2. Висновок: нам може бути цікаво зрозуміти, як на змінну відповіді впливає зміна значення пояснювальних змінних (наприклад, наскільки в середньому зростає ціна нерухомості, коли кількість кімнат збільшується на одну?)
Залежно від того, чи є наша ціль висновки чи передбачення (або суміш обох), ми можемо використовувати різні методи для оцінки функції f . Наприклад, лінійні моделі пропонують легшу інтерпретацію, але складні для інтерпретації нелінійні моделі можуть запропонувати більш точні прогнози.
Ось список найбільш часто використовуваних алгоритмів навчання під наглядом:
- Лінійна регресія
- Логістична регресія
- Лінійний дискримінантний аналіз
- Квадратичний дискримінантний аналіз
- Дерева рішень
- Наївний Байєс
- Опорні векторні машини
- Нейронні мережі
Алгоритми навчання без контролю
Алгоритм неконтрольованого навчання можна використовувати, якщо у нас є список змінних ( X 1 , дані.
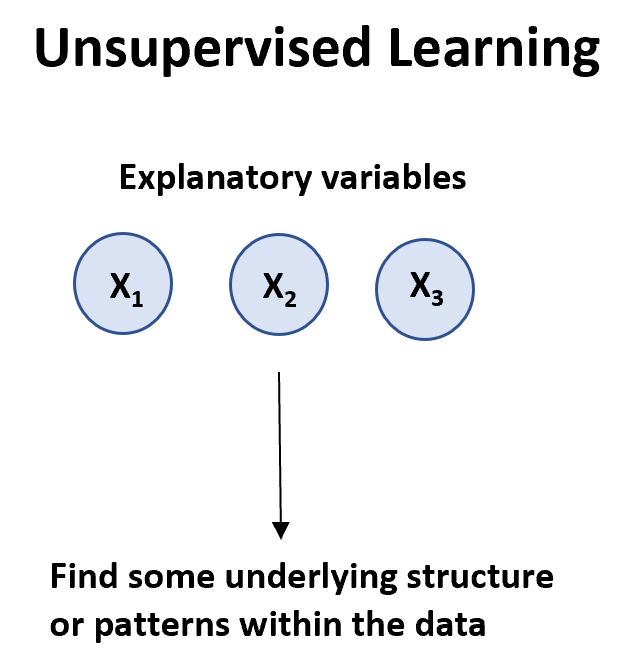
Існує два основних типи алгоритмів неконтрольованого навчання:
1. Кластеризація: використовуючи ці типи алгоритмів, ми намагаємося знайти «кластери» спостережень у наборі даних, які схожі один на одного. Це часто використовується в роздрібній торгівлі, коли компанія хоче визначити групи клієнтів зі схожими купівельними звичками, щоб вони могли створити конкретні маркетингові стратегії, націлені на певні групи клієнтів.
2. Асоціація: використовуючи ці типи алгоритмів, ми намагаємося знайти «правила», які можна використовувати для встановлення асоціацій. Наприклад, роздрібні торговці можуть розробити алгоритм асоціації, який вказує, що «якщо клієнт купує продукт X, він, швидше за все, також купить продукт Y».
Ось список найбільш часто використовуваних алгоритмів неконтрольованого навчання:
- Аналіз головних компонент
- K-означає кластеризацію
- Групування К-медоїдів
- Ієрархічна класифікація
- Апріорний алгоритм
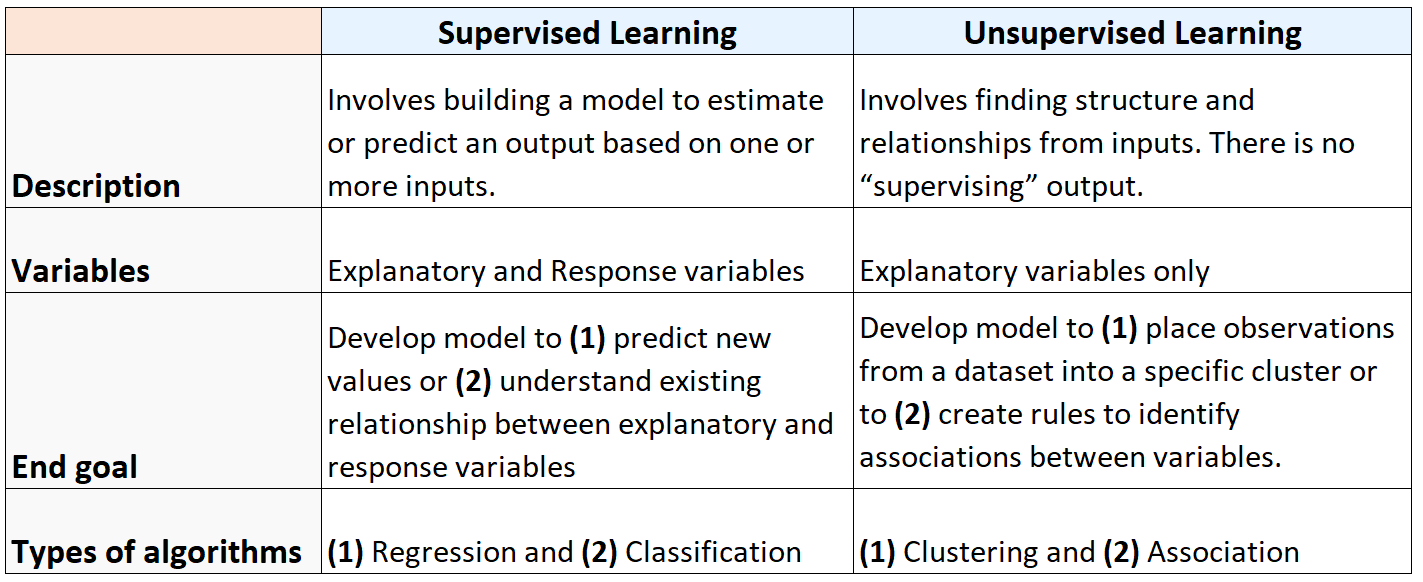
Резюме: навчання під контролем або без нього
У наведеній нижче таблиці підсумовано відмінності між контрольованими та неконтрольованими алгоритмами навчання:
На наступній діаграмі узагальнено типи алгоритмів машинного навчання:

Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше