Регресія основного компонента в python (крок за кроком)
Враховуючи набір із p- прогностичних змінних і змінну відповіді, множинна лінійна регресія використовує метод найменших квадратів для мінімізації залишкової суми квадратів (RSS):
RSS = Σ(y i – ŷ i ) 2
золото:
- Σ : грецький символ, що означає суму
- y i : фактичне значення відповіді для i-го спостереження
- ŷ i : прогнозоване значення відповіді на основі моделі множинної лінійної регресії
Однак, коли прогностичні змінні сильно корельовані, мультиколінеарність може стати проблемою. Це може зробити оцінки коефіцієнтів моделі ненадійними та мати високу дисперсію.
Одним із способів уникнути цієї проблеми є використання регресії головних компонентів , яка знаходить M лінійних комбінацій (званих «головними компонентами») вихідних p предикторів, а потім використовує найменші квадрати, щоб відповідати моделі лінійної регресії, використовуючи головні компоненти як предиктори.
У цьому посібнику наведено покроковий приклад виконання регресії головних компонентів у Python.
Крок 1. Імпортуйте необхідні пакети
Спочатку ми імпортуємо пакети, необхідні для виконання регресії головних компонентів (PCR) у Python:
import numpy as np
import pandas as pd
import matplotlib. pyplot as plt
from sklearn. preprocessing import scale
from sklearn import model_selection
from sklearn. model_selection import RepeatedKFold
from sklearn.model_selection import train_test_split
from sklearn. PCA import decomposition
from sklearn. linear_model import LinearRegression
from sklearn. metrics import mean_squared_error
Крок 2. Завантажте дані
Для цього прикладу ми використаємо набір даних під назвою mtcars , який містить інформацію про 33 різні автомобілі. Ми будемо використовувати hp як змінну відповіді та наступні змінні як предиктори:
- миль на галлон
- дисплей
- лайно
- вага
- qsec
Наступний код показує, як завантажити та відобразити цей набір даних:
#define URL where data is located
url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/mtcars.csv"
#read in data
data_full = pd. read_csv (url)
#select subset of data
data = data_full[["mpg", "disp", "drat", "wt", "qsec", "hp"]]
#view first six rows of data
data[0:6]
mpg disp drat wt qsec hp
0 21.0 160.0 3.90 2.620 16.46 110
1 21.0 160.0 3.90 2.875 17.02 110
2 22.8 108.0 3.85 2.320 18.61 93
3 21.4 258.0 3.08 3.215 19.44 110
4 18.7 360.0 3.15 3.440 17.02 175
5 18.1 225.0 2.76 3.460 20.22 105
Крок 3: Налаштуйте модель ПЛР
У наведеному нижче коді показано, як адаптувати модель ПЛР до цих даних. Зверніть увагу на наступне:
- pca.fit_transform(scale(X)) : це повідомляє Python, що кожна змінна предиктора повинна бути масштабована, щоб мати середнє значення 0 і стандартне відхилення 1. Це гарантує, що жодна змінна предиктора не матиме надто великого впливу на модель, якщо це відбувається. вимірювати в різних одиницях.
- cv = RepeatedKFold() : це вказує Python використовувати перехресну перевірку k-згортки для оцінки продуктивності моделі. Для цього прикладу ми вибираємо k = 10 згорток, повторених 3 рази.
#define predictor and response variables
X = data[["mpg", "disp", "drat", "wt", "qsec"]]
y = data[["hp"]]
#scale predictor variables
pca = pca()
X_reduced = pca. fit_transform ( scale (X))
#define cross validation method
cv = RepeatedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
regr = LinearRegression()
mse = []
# Calculate MSE with only the intercept
score = -1*model_selection. cross_val_score (regr,
n.p. ones ((len(X_reduced),1)), y, cv=cv,
scoring=' neg_mean_squared_error '). mean ()
mse. append (score)
# Calculate MSE using cross-validation, adding one component at a time
for i in np. arange (1, 6):
score = -1*model_selection. cross_val_score (regr,
X_reduced[:,:i], y, cv=cv, scoring=' neg_mean_squared_error '). mean ()
mse. append (score)
# Plot cross-validation results
plt. plot (mse)
plt. xlabel ('Number of Principal Components')
plt. ylabel ('MSE')
plt. title ('hp')
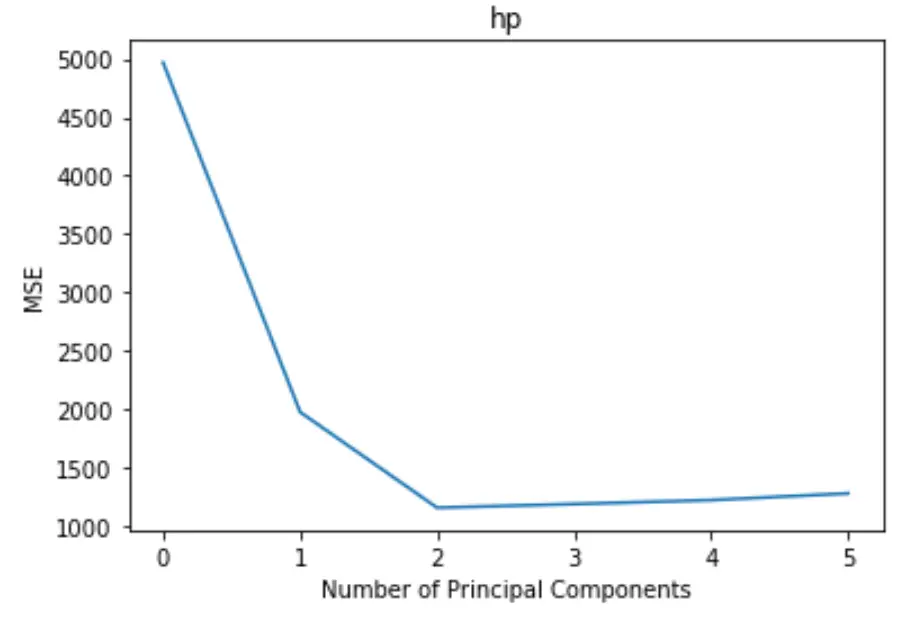
На графіку відображається кількість головних компонентів уздовж осі абсцис і критерій MSE (середня квадратична помилка) уздовж осі у.
З графіка ми бачимо, що MSE тесту зменшується при додаванні двох головних компонентів, але починає збільшуватися, коли ми додаємо більше двох головних компонентів.
Таким чином, оптимальна модель включає лише перші дві основні складові.
Ми також можемо використати наступний код, щоб обчислити відсоток дисперсії у змінній відповіді, що пояснюється додаванням кожного головного компонента до моделі:
n.p. cumsum (np. round (pca. explained_variance_ratio_ , decimals= 4 )* 100 )
array([69.83, 89.35, 95.88, 98.95, 99.99])
Ми бачимо наступне:
- Використовуючи лише перший головний компонент, ми можемо пояснити 69,83% варіації змінної відповіді.
- Додавши другий головний компонент, ми можемо пояснити 89,35% варіації змінної відповіді.
Зауважте, що ми все одно зможемо пояснити більшу дисперсію, використовуючи більше головних компонентів, але ми бачимо, що додавання більше двох головних компонентів фактично не значно збільшує відсоток поясненої дисперсії.
Крок 4. Використовуйте остаточну модель для прогнозування
Ми можемо використовувати остаточну двокомпонентну модель ПЛР, щоб зробити прогнози щодо нових спостережень.
У наведеному нижче коді показано, як розділити вихідний набір даних на навчальний і тестовий набір і використовувати модель ПЛР із двома основними компонентами для прогнозування на тестовому наборі.
#split the dataset into training (70%) and testing (30%) sets
X_train,X_test,y_train,y_test = train_test_split (X,y,test_size= 0.3 , random_state= 0 )
#scale the training and testing data
X_reduced_train = pca. fit_transform ( scale (X_train))
X_reduced_test = pca. transform ( scale (X_test))[:,:1]
#train PCR model on training data
regr = LinearRegression()
reg. fit (X_reduced_train[:,:1], y_train)
#calculate RMSE
pred = regr. predict (X_reduced_test)
n.p. sqrt ( mean_squared_error (y_test, pred))
40.2096
Ми бачимо, що тест RMSE виявляється рівним 40,2096 . Це середнє відхилення між прогнозованим значенням hp і спостережуваним значенням hp для спостережень тестового набору.
Повний код Python, використаний у цьому прикладі, можна знайти тут .
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше