Асиметрія (статистика)
У цій статті пояснюється, що означає асиметрія в статистиці. Таким чином, ви знайдете визначення асиметрії в статистиці, які є різні типи асиметрії, як розраховується коефіцієнт асиметрії та як він інтерпретується.
Що таке асиметрія в статистиці?
У статистиці асиметрія — це міра, яка вказує на ступінь симетрії (або асиметрії) розподілу відносно його середнього значення. Простіше кажучи, асиметрія — це статистичний параметр, який використовується для визначення ступеня симетрії (або асиметрії) розподілу без необхідності його графічного представлення.
Отже, спотворений розподіл — це такий, який має іншу кількість значень ліворуч від середнього, ніж праворуч. З іншого боку, у симетричному розподілі є однакова кількість значень ліворуч і праворуч від середнього.
Наприклад, експоненціальний розподіл є асиметричним, а нормальний – симетричним.
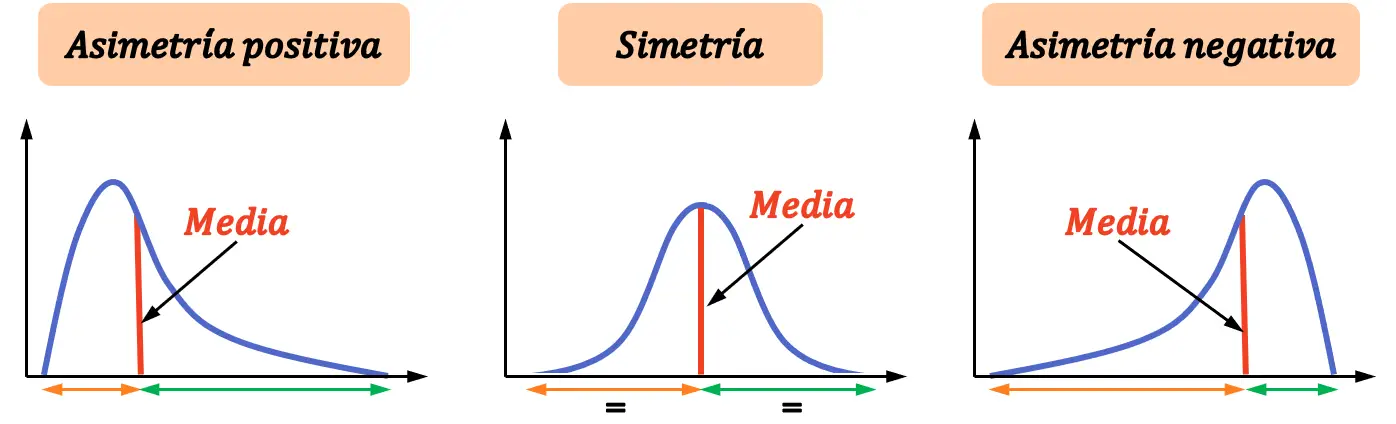
Види асиметрії
У статистиці виділяють три види асиметрії :
- Позитивна асиметрія : розподіл має більше різних значень праворуч від середнього, ніж ліворуч.
- Симетрія : розподіл має однакову кількість значень ліворуч від середнього, як і праворуч від середнього.
- Негативна асиметрія : розподіл має більше різних значень ліворуч від середнього, ніж праворуч.
Коефіцієнт асиметрії
Коефіцієнт асиметрії або індекс асиметрії — це статистичний коефіцієнт, який допомагає визначити асиметрію розподілу. Отже, розрахувавши коефіцієнт асиметрії, ви можете дізнатися тип асиметрії розподілу без необхідності робити його графічне представлення.
Хоча існують різні формули для розрахунку коефіцієнта асиметрії, і ми побачимо їх усі нижче, незалежно від використовуваної формули, інтерпретація коефіцієнта асиметрії завжди виконується наступним чином:
- Якщо коефіцієнт асиметрії додатний, розподіл є позитивно викривленим .
- Якщо коефіцієнт асиметрії дорівнює нулю, то розподіл є симетричним .
- Якщо коефіцієнт асиметрії негативний, розподіл є негативно зміщеним .
Коефіцієнт асиметрії Фішера
Коефіцієнт асиметрії Фішера дорівнює третьому моменту середнього значення, поділеному на стандартне відхилення вибірки. Тому формула для коефіцієнта асиметрії Фішера має вигляд:

Для розрахунку коефіцієнта Фішера можна використовувати будь-яку з наступних двох формул:

![\displaystyle\gamma_1=\frac{\operatorname{E}[X^3] - 3\mu\sigma^2 - \mu^3}{\sigma^3}](https://statorials.org/wp-content/ql-cache/quicklatex.com-92f7c8482d520258f24cc0166d898d1e_l3.png "Rendered by QuickLaTeX.com")
золото

це математична надія,

середнє арифметичне,

стандартне відхилення і

загальна кількість даних.
З іншого боку, якщо дані згруповані, ви можете використовувати таку формулу:

Де в даному випадку

Це ознака класу і

абсолютна частота курсу.
Коефіцієнт асиметрії Пірсона
Коефіцієнт асиметрії Пірсона дорівнює різниці між середнім значенням вибірки та модою, поділеній на її стандартне відхилення (або стандартне відхилення). Отже , формула для коефіцієнта асиметрії Пірсона має такий вигляд:

золото

– коефіцієнт Пірсона,
середнє арифметичне,

мода і
стандартне відхилення.
Майте на увазі, що коефіцієнт асиметрії Пірсона можна обчислити, лише якщо це унімодальний розподіл, тобто якщо в даних є лише одна мода.
Деякі автори використовують медіану замість моди для розрахунку коефіцієнта асиметрії Пірсона, але зазвичай використовується наведена вище формула.
Коефіцієнт асиметрії Боулі
Коефіцієнт асиметрії Боулі дорівнює сумі третього квартиля плюс перший квартиль мінус подвоєна медіана, поділена на різницю між третім і першим квартилями. Таким чином, формула для цього коефіцієнта асиметрії виглядає так:

золото

І

Це відповідно перший і третій квартилі і

є медіаною розподілу.
Нагадаємо, що медіана розподілу збігається з другим квартилем.
Для чого використовується асиметрія в статистиці?
Щоб повністю зрозуміти значення асиметрії в статистиці, давайте подивимося, як обчислюється ця характеристика розподілу.
Асиметрія в основному використовується для визначення форми розподілу ймовірностей, тому що, обчисливши коефіцієнт асиметрії, ви можете дізнатися, чи є це від’ємним асиметричним, позитивним асиметричним чи симетричним розподілом, не потребуючи його графічного представлення.
Крім того, асиметрія разом із ексцесом використовується для визначення того, чи може набір даних наблизити нормальний розподіл. Іншими словами, коефіцієнт асиметрії та коефіцієнт ексцесу обчислюються, щоб перевірити, чи відповідає ряд даних припущенням нормального розподілу, і, якщо так, це виявляється дуже корисним, оскільки означає, що можна застосувати багато статистичних теорем.
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше