Як виконати просту лінійну регресію в r (крок за кроком)
Проста лінійна регресія — це техніка, яку ми можемо використати, щоб зрозуміти зв’язок між окремою пояснювальною змінною та окремою змінною відповіді .
Коротше кажучи, ця техніка знаходить рядок, який найкраще «відповідає» даним, і має такий вигляд:
ŷ = b 0 + b 1 x
золото:
- ŷ : оцінене значення відповіді
- b 0 : Початок лінії регресії
- b 1 : Нахил лінії регресії
Це рівняння може допомогти нам зрозуміти взаємозв’язок між пояснювальною змінною та змінною відповіді та (якщо воно є статистично значущим) його можна використовувати для прогнозування значення змінної відповіді, враховуючи значення пояснювальної змінної.
Цей підручник надає покрокове пояснення того, як виконати просту лінійну регресію в R.
Крок 1. Завантажте дані
Для цього прикладу ми створимо підроблений набір даних, що містить такі дві змінні для 15 студентів:
- Загальна кількість годин, відпрацьованих на окремі іспити
- Результат іспиту
Ми спробуємо підібрати просту модель лінійної регресії, використовуючи години як пояснювальну змінну та результати іспитів як змінну відповіді.
Наступний код показує, як створити цей фальшивий набір даних у R:
#create dataset df <- data.frame(hours=c(1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14), score=c(64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89)) #view first six rows of dataset head(df) hours score 1 1 64 2 2 66 3 4 76 4 5 73 5 5 74 6 6 81 #attach dataset to make it more convenient to work with attach(df)
Крок 2: Візуалізуйте дані
Перш ніж підганяти просту модель лінійної регресії, ми повинні спочатку візуалізувати дані, щоб зрозуміти їх.
По-перше, ми хочемо переконатися, що зв’язок між годинами та оцінкою приблизно лінійний, оскільки це велике базове припущення простої лінійної регресії. Ми можемо створити просту діаграму розсіювання, щоб візуалізувати зв’язок між двома змінними:
scatter.smooth(hours, score, main=' Hours studied vs. Exam Score ')
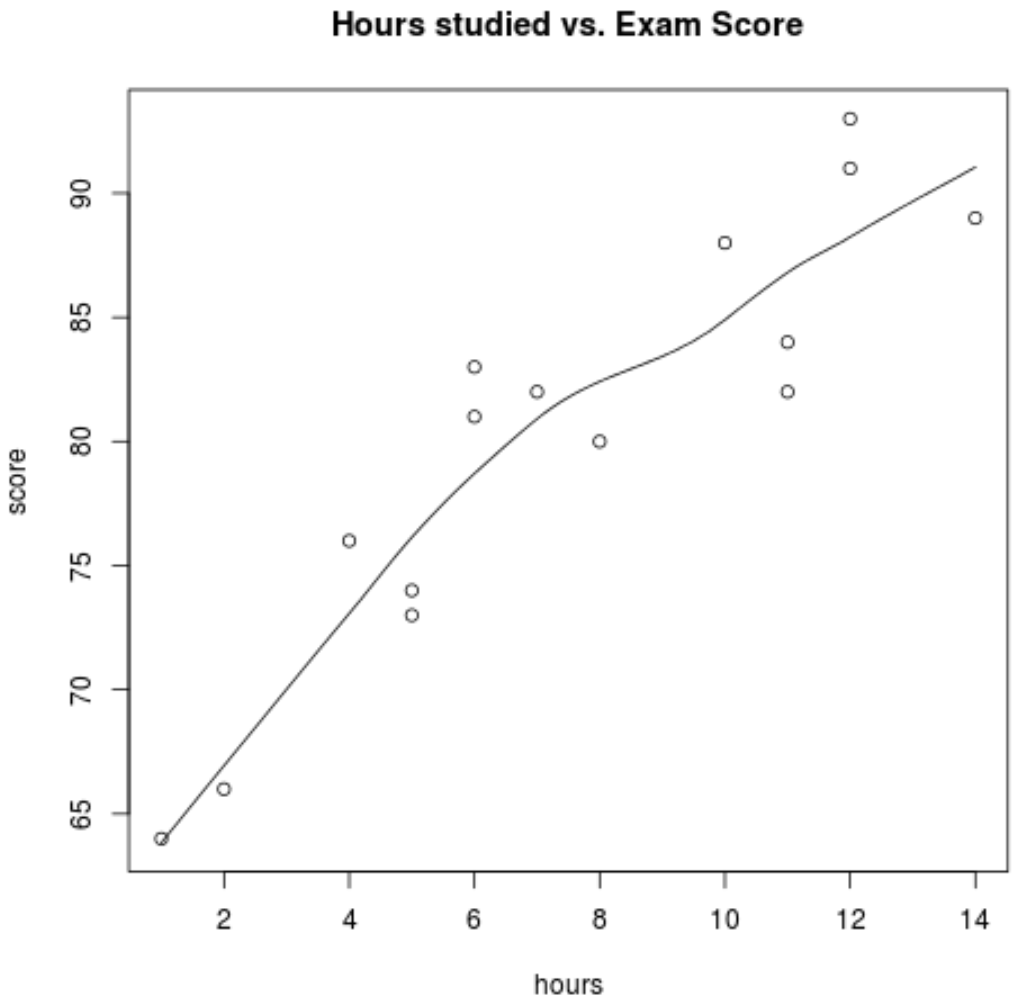
З графіка ми бачимо, що залежність виглядає лінійною. Зі збільшенням кількості годин оцінка також має тенденцію до лінійного зростання.
Тоді ми можемо створити коробкову діаграму для візуалізації розподілу результатів іспиту та перевірки викидів . За замовчуванням R визначає спостереження як викид, якщо воно в 1,5 рази перевищує інтерквартильний діапазон вище третього квартиля (Q3) або в 1,5 рази перевищує інтерквартильний діапазон нижче першого квартиля (Q1).
Якщо спостереження виходить за межі, на прямокутній діаграмі з’явиться маленьке коло:
boxplot(score)
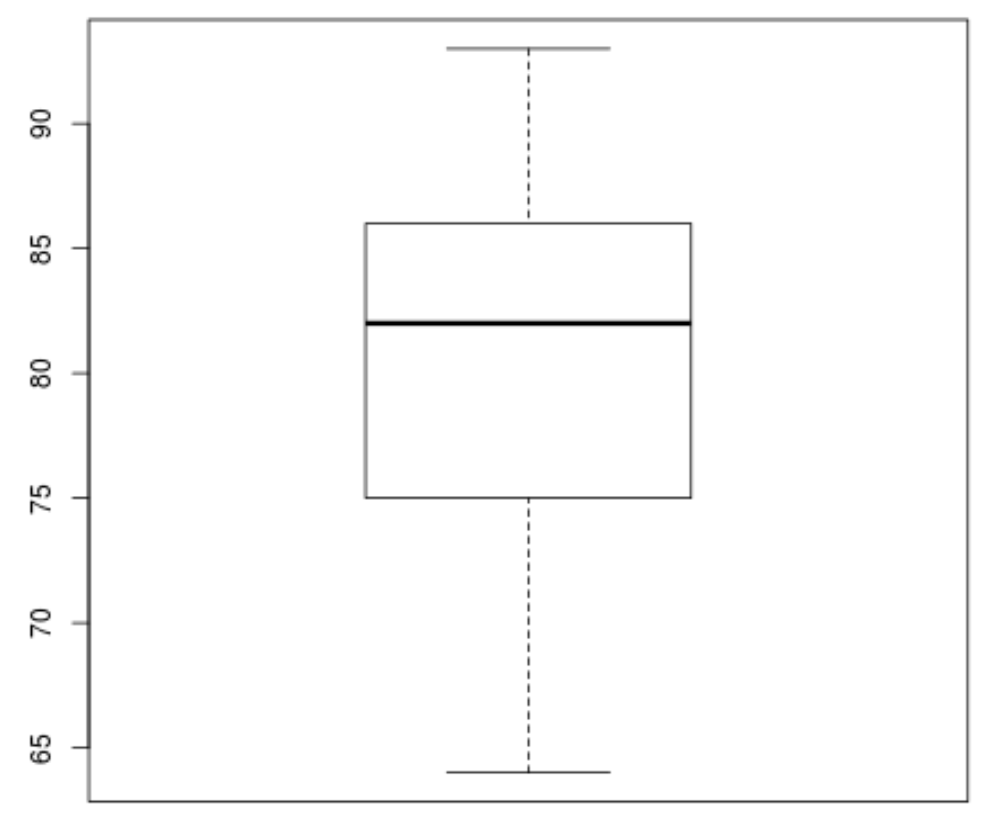
На прямокутній діаграмі немає маленьких кружечків, а це означає, що в нашому наборі даних немає викидів.
Крок 3: Виконайте просту лінійну регресію
Після того, як ми підтвердили, що зв’язок між нашими змінними є лінійним і немає викидів, ми можемо перейти до підгонки простої моделі лінійної регресії, використовуючи години як пояснювальну змінну та бал як змінну відповіді:
#fit simple linear regression model model <- lm(score~hours) #view model summary summary(model) Call: lm(formula = score ~ hours) Residuals: Min 1Q Median 3Q Max -5,140 -3,219 -1,193 2,816 5,772 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 65,334 2,106 31,023 1.41e-13 *** hours 1.982 0.248 7.995 2.25e-06 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.641 on 13 degrees of freedom Multiple R-squared: 0.831, Adjusted R-squared: 0.818 F-statistic: 63.91 on 1 and 13 DF, p-value: 2.253e-06
З підсумку моделі ми можемо побачити, що підігнане рівняння регресії таке:
Оцінка = 65,334 + 1,982*(години)
Це означає, що кожна додаткова вивчена година пов’язана зі збільшенням середнього балу на іспиті на 1982 бали. А вихідне значення 65 334 говорить нам про середній очікуваний іспитовий бал для студента, який навчається нуль годин.
Ми також можемо використати це рівняння, щоб знайти очікуваний бал за іспит на основі кількості годин, які навчається студент. Наприклад, студент, який навчається 10 годин, повинен набрати іспитовий бал 85,15 :
Оцінка = 65,334 + 1,982*(10) = 85,15
Ось як інтерпретувати решту короткого опису моделі:
- Pr(>|t|): це p-значення, пов’язане з коефіцієнтами моделі. Оскільки p-значення для годин (2,25e-06) значно менше, ніж 0,05, ми можемо сказати, що існує статистично значущий зв’язок між годинами та балом .
- Множинний R-квадрат: це число говорить нам, що відсоток варіації оцінок на іспитах можна пояснити кількістю вивчених годин. Загалом, чим більше значення R-квадрат регресійної моделі, тим краще пояснювальні змінні здатні передбачити значення змінної відповіді. У цьому випадку 83,1% варіації балів можна пояснити вивченими годинами.
- Залишкова стандартна помилка: це середня відстань між спостережуваними значеннями та лінією регресії. Чим менше це значення, тим більше лінія регресії може відповідати даним спостереження. У цьому випадку середній бал, отриманий на іспиті, відхиляється на 3641 бал від балу, передбаченого лінією регресії.
- F-статистика та p-значення: F-статистика ( 63.91 ) і відповідне p-значення ( 2.253e-06 ) говорять нам про загальну значущість регресійної моделі, тобто чи корисні пояснювальні змінні в моделі для пояснення варіації . у змінній відповіді. Оскільки p-значення в цьому прикладі менше 0,05, наша модель є статистично значущою, і години вважаються корисними для пояснення варіації оцінки .
Крок 4: Створіть залишкові ділянки
Після підгонки моделі простої лінійної регресії до даних останнім кроком є створення графіків залишків.
Одне з ключових припущень лінійної регресії полягає в тому, що залишки регресійної моделі розподілені приблизно нормально і є гомоскедастичними на кожному рівні пояснювальної змінної. Якщо ці припущення не виконуються, результати нашої моделі регресії можуть бути оманливими або ненадійними.
Щоб переконатися, що ці припущення виконуються, ми можемо створити такі залишкові графіки:
Графік залишків проти підігнаних значень: цей графік корисний для підтвердження гомоскедастичності. На осі абсцис відображаються підігнані значення, а на осі у – залишки. Поки залишки виглядають випадково та рівномірно розподіленими по всьому графіку навколо нульового значення, ми можемо припустити, що гомоскедастичність не порушена:
#define residuals res <- resid(model) #produce residual vs. fitted plot plot(fitted(model), res) #add a horizontal line at 0 abline(0,0)
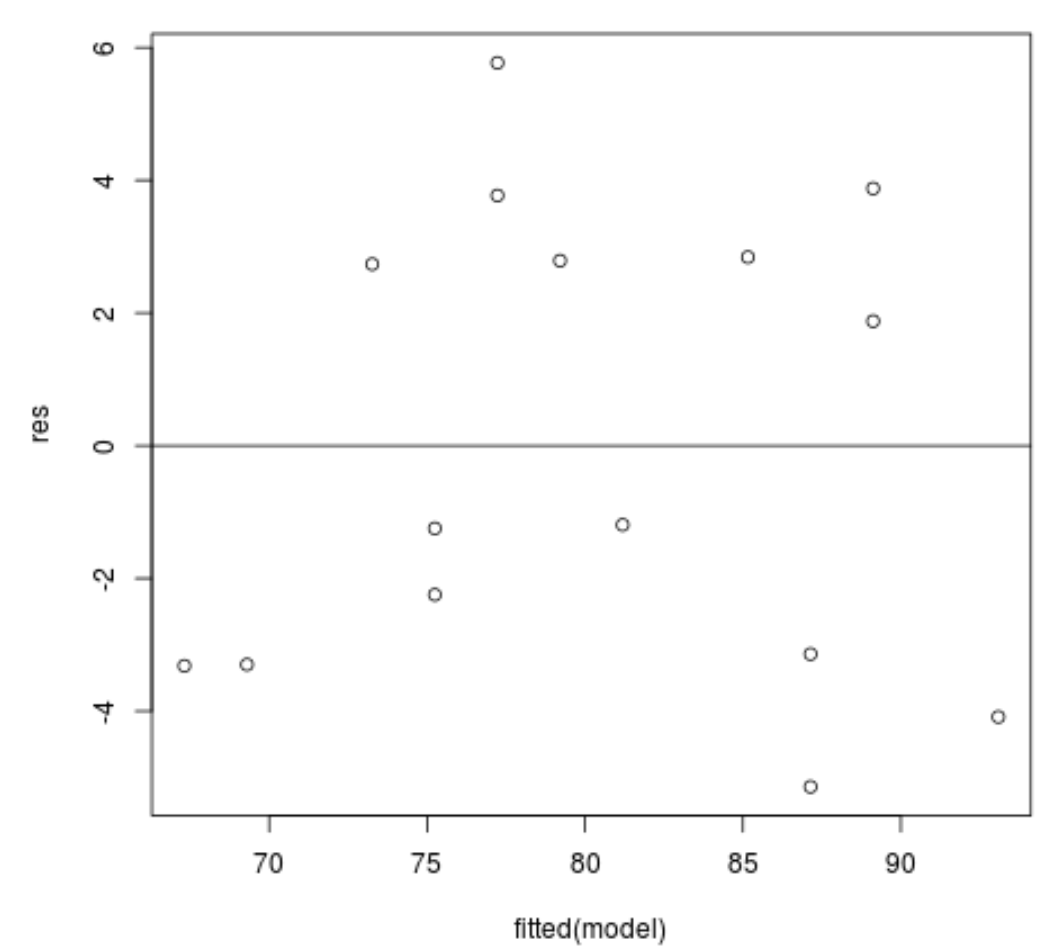
Залишки, здається, випадково розкидані навколо нуля і не виявляють помітної моделі, тому це припущення виконується.
Графік QQ: цей графік корисний для визначення того, чи відповідають залишки нормальному розподілу. Якщо значення даних на графіку йдуть по приблизно прямій лінії під кутом 45 градусів, то дані розподіляються нормально:
#create QQ plot for residuals qqnorm(res) #add a straight diagonal line to the plot qqline(res)
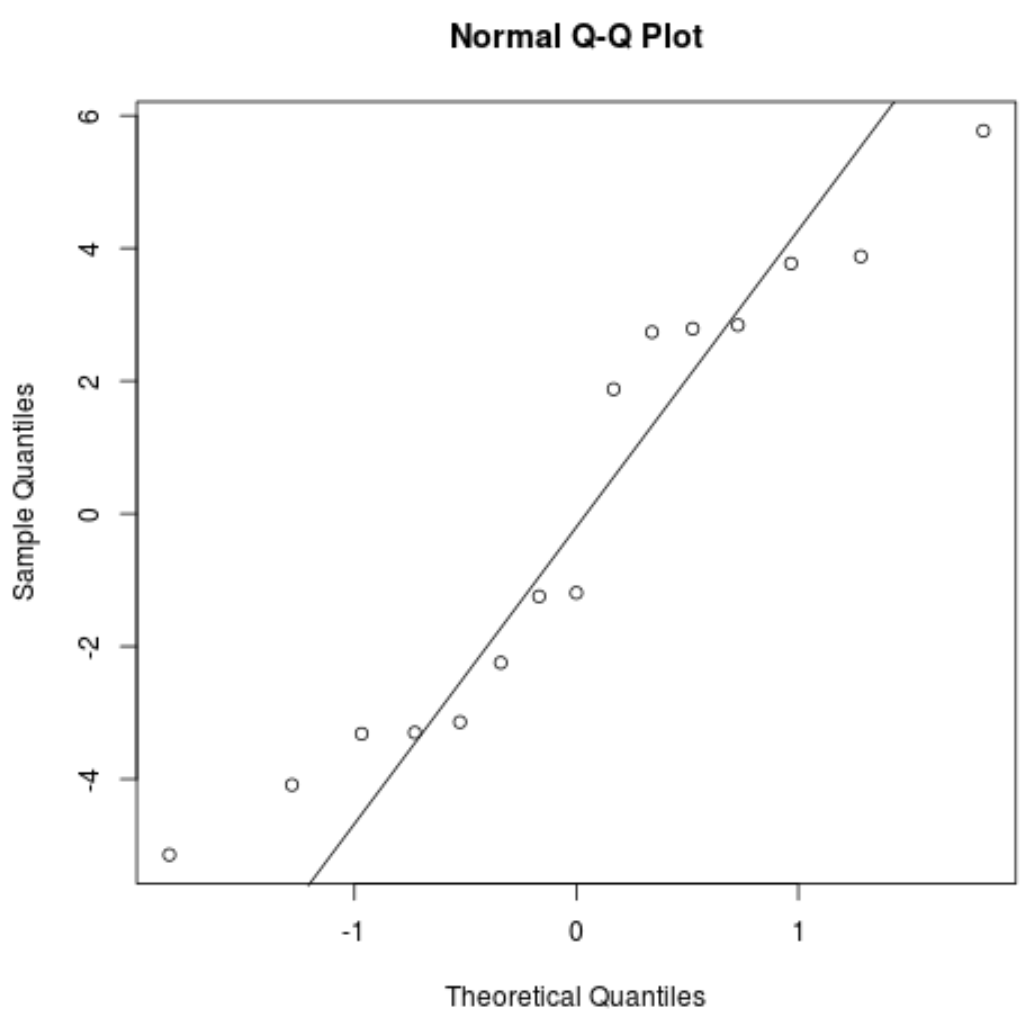
Залишки трохи відхиляються від лінії 45 градусів, але недостатньо, щоб викликати серйозне занепокоєння. Ми можемо припустити, що припущення нормальності виконується.
Оскільки залишки є нормально розподіленими та гомоскедастичними, ми перевірили, чи виконуються припущення моделі простої лінійної регресії. Таким чином, вихід нашої моделі надійний.
Повний код R, використаний у цьому посібнику, можна знайти тут .
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше