Як обчислити студентські залишки в python
Залишок студента – це просто залишок, поділений на його оцінене стандартне відхилення.
На практиці ми зазвичай кажемо, що будь-яке спостереження в наборі даних, залишкова оцінка якого перевищує абсолютне значення 3, є викидом.
Ми можемо швидко отримати студентизовані залишки регресійної моделі в Python за допомогою функції OLSResults.outlier_test() statsmodels, яка використовує такий синтаксис:
OLSResults.outlier_test()
де OLSResults — це назва лінійної моделі, підібраної за допомогою функції statsmodels ols() .
Приклад: обчислення студентизованих залишків у Python
Припустімо, ми створюємо таку просту модель лінійної регресії на Python:
#import necessary packages and functions import numpy as np import pandas as pd import statsmodels. api as sm from statsmodels. formula . api import ols #create dataset df = pd. DataFrame ({'rating': [90, 85, 82, 88, 94, 90, 76, 75, 87, 86], 'points': [25, 20, 14, 16, 27, 20, 12, 15, 14, 19]}) #fit simple linear regression model model = ols('rating ~ points', data=df). fit ()
Ми можемо використовувати функцію outlier_test() , щоб створити DataFrame, який містить студентські залишки для кожного спостереження в наборі даних:
#calculate studentized residuals stud_res = model. outlier_test () #display studentized residuals print(stud_res) student_resid unadj_p bonf(p) 0 -0.486471 0.641494 1.000000 1 -0.491937 0.637814 1.000000 2 0.172006 0.868300 1.000000 3 1.287711 0.238781 1.000000 4 0.106923 0.917850 1.000000 5 0.748842 0.478355 1.000000 6 -0.968124 0.365234 1.000000 7 -2.409911 0.046780 0.467801 8 1.688046 0.135258 1.000000 9 -0.014163 0.989095 1.000000
Цей DataFrame відображає такі значення для кожного спостереження в наборі даних:
- Студентований залишок
- Нескориговане p-значення залишку, підібраного студентом
- Виправлене за Бонферроні р-значення залишку Стьюдента
Ми бачимо, що стьюдентизований залишок для першого спостереження в наборі даних дорівнює -0,486471 , залишок для другого спостереження становить -0,491937 і так далі.
Ми також можемо створити швидкий графік значень змінних предикторів проти відповідних студентських залишків:
import matplotlib. pyplot as plt #define predictor variable values and studentized residuals x = df[' points '] y = stud_res[' student_resid '] #create scatterplot of predictor variable vs. studentized residuals plt. scatter (x,y) plt. axhline (y=0, color=' black ', linestyle=' -- ') plt. xlabel (' Points ') plt. ylabel (' Studentized Residuals ')
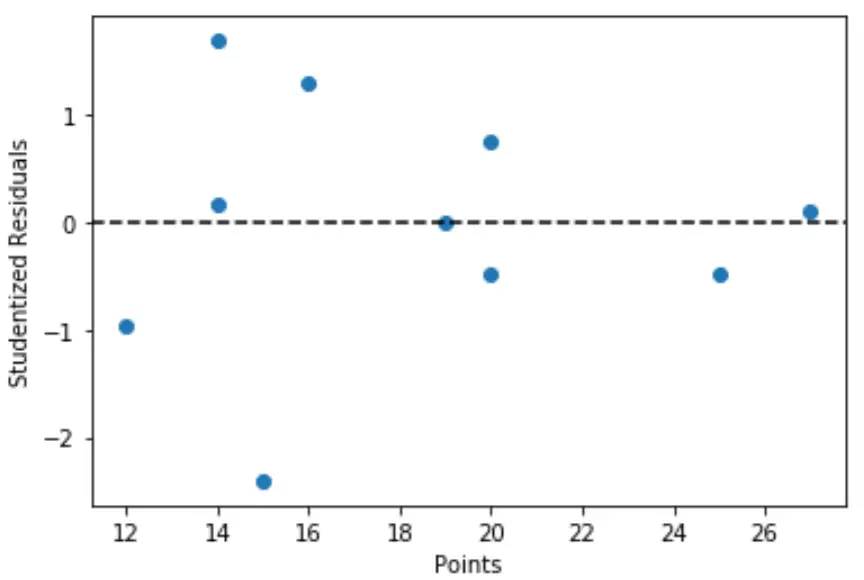
На графіку ми бачимо, що жодне зі спостережень не має залишку студента з абсолютним значенням більше 3, тому в наборі даних немає чітких викидів.
Додаткові ресурси
Як виконати просту лінійну регресію в Python
Як виконати множинну лінійну регресію в Python
Як створити залишковий графік у Python
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше