Як намалювати roc-криву в python (крок за кроком)
Логістична регресія – це статистичний метод, який ми використовуємо для підгонки регресійної моделі, коли змінна відповіді є двійковою. Щоб оцінити, наскільки модель логістичної регресії відповідає набору даних, ми можемо розглянути такі два показники:
- Чутливість: ймовірність того, що модель передбачає позитивний результат для спостереження, коли результат насправді позитивний. Це також називається «справжній позитивний показник».
- Специфічність: ймовірність того, що модель передбачає негативний результат для спостереження, коли результат насправді негативний. Це також називається «справжній негативний показник».
Одним із способів візуалізації цих двох вимірювань є створення кривої ROC , що означає криву «робоча характеристика приймача». Це графік, який відображає чутливість і специфічність моделі логістичної регресії.
Наступний покроковий приклад показує, як створити та інтерпретувати криву ROC у Python.
Крок 1. Імпортуйте необхідні пакети
Спочатку ми імпортуємо необхідні пакети для виконання логістичної регресії в Python:
import pandas as pd import numpy as np from sklearn. model_selection import train_test_split from sklearn. linear_model import LogisticRegression from sklearn import metrics import matplotlib. pyplot as plt
Крок 2: Підгонка моделі логістичної регресії
Далі ми імпортуємо набір даних і підберемо до нього модель логістичної регресії:
#import dataset from CSV file on Github
url = "https://raw.githubusercontent.com/Statology/Python-Guides/main/default.csv"
data = pd. read_csv (url)
#define the predictor variables and the response variable
X = data[[' student ',' balance ',' income ']]
y = data[' default ']
#split the dataset into training (70%) and testing (30%) sets
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
#instantiate the model
log_regression = LogisticRegression()
#fit the model using the training data
log_regression. fit (X_train,y_train)
Крок 3: Намалюйте криву ROC
Далі ми розрахуємо істинний і хибно-позитивний рівень і створимо ROC-криву за допомогою пакета візуалізації даних Matplotlib:
#define metrics
y_pred_proba = log_regression. predict_proba (X_test)[::,1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred_proba)
#create ROC curve
plt. plot (fpr,tpr)
plt. ylabel (' True Positive Rate ')
plt. xlabel (' False Positive Rate ')
plt. show ()
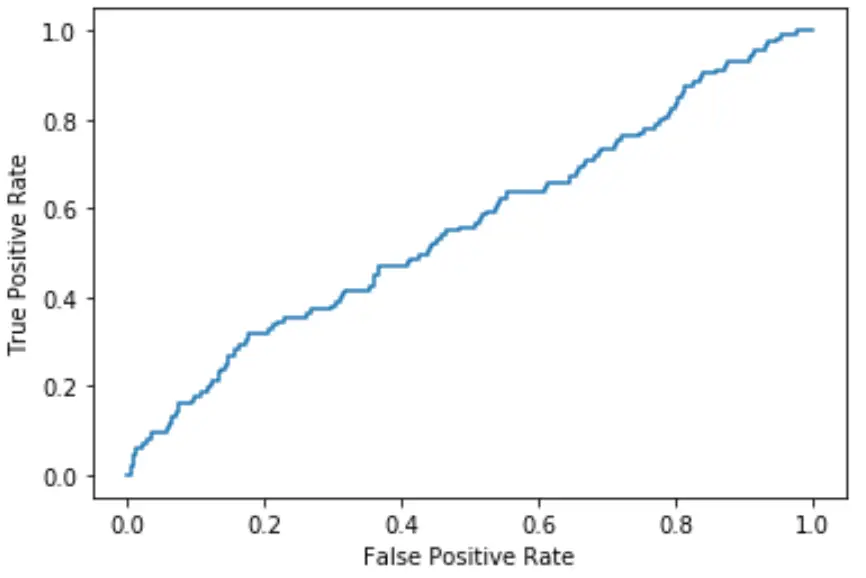
Чим ближче крива підходить до верхнього лівого кута графіка, тим краще модель може класифікувати дані за категоріями.
Як ми бачимо з графіка вище, ця модель логістичної регресії досить погано справляється з сортуванням даних за категоріями.
Щоб визначити це кількісно, ми можемо обчислити AUC – площу під кривою – яка повідомляє нам, яка частина ділянки знаходиться під кривою.
Чим ближче AUC до 1, тим краща модель. Модель з AUC, що дорівнює 0,5, не краща за модель, яка виконує випадкову класифікацію.
Крок 4: Обчисліть AUC
Ми можемо використати наступний код, щоб обчислити AUC моделі та відобразити його в нижньому правому куті графіка ROC:
#define metrics
y_pred_proba = log_regression. predict_proba (X_test)[::,1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred_proba)
auc = metrics. roc_auc_score (y_test, y_pred_proba)
#create ROC curve
plt. plot (fpr,tpr,label=" AUC= "+str(auc))
plt. ylabel (' True Positive Rate ')
plt. xlabel (' False Positive Rate ')
plt. legend (loc=4)
plt. show ()
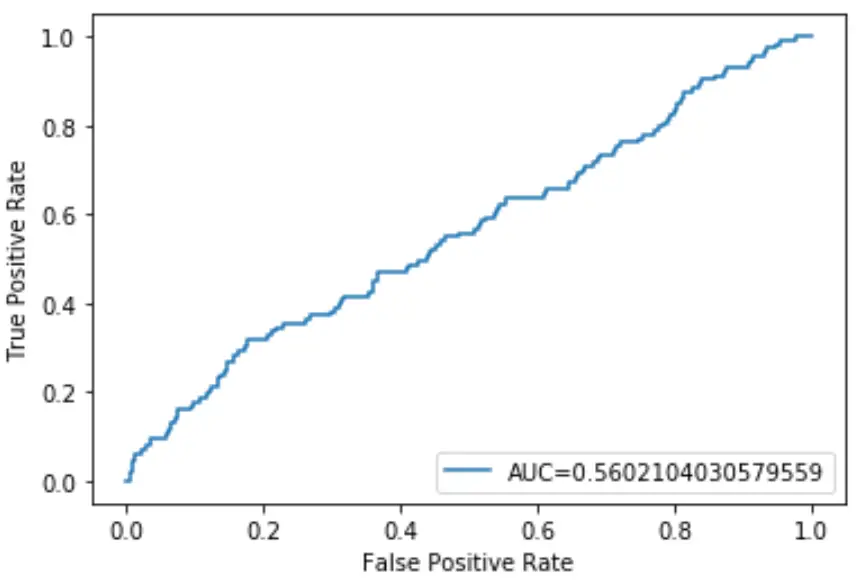
AUC цієї моделі логістичної регресії дорівнює 0,5602 . Оскільки цей показник близький до 0,5, це підтверджує, що модель погано класифікує дані.
Пов’язане: Як побудувати кілька кривих ROC у Python
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше