Як розрахувати описову статистику в google таблицях
Описова статистика – це значення, які описують набір даних. Вони допомагають нам зрозуміти, де знаходиться центр набору даних, а також розподіл значень у наборі даних.
У наведеному нижче прикладі показано, як обчислити таку описову статистику для набору даних у Google Таблицях:
- Середнє (середнє значення)
- Медіана (середнє значення)
- Fashion (найчастіше значення)
- Діапазон (різниця між мінімальним і максимальним значенням)
- Стандартне відхилення (розподіл значень)
- Розмір вибірки (загальна кількість спостережень)
Приклад: обчислення описової статистики в Google Таблицях
Припустімо, у Google Таблицях є такий набір даних із 20 значеннями:
На наступному знімку екрана показано, як обчислити різні описові статистичні дані для цього набору даних, включаючи використані формули:
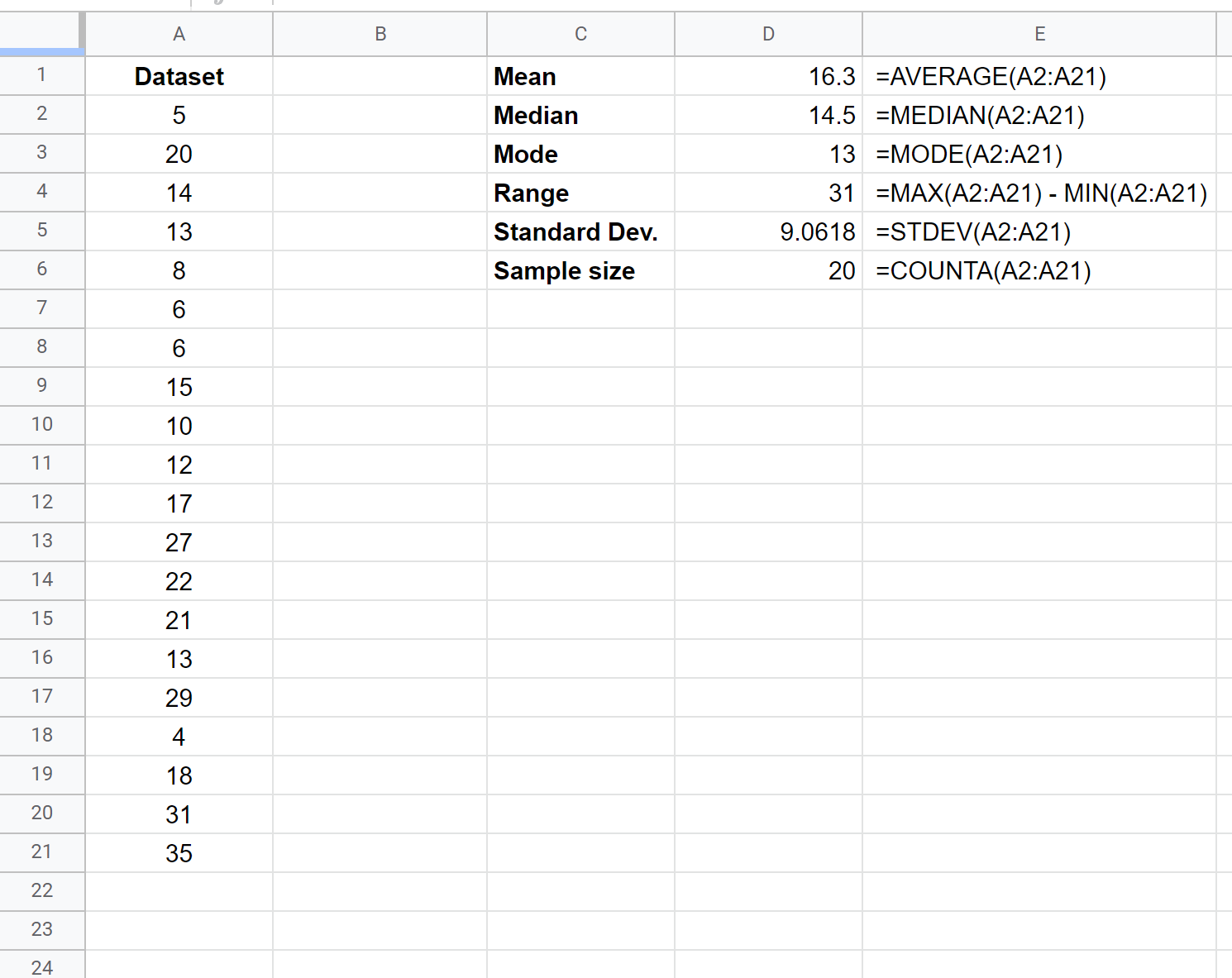
Ми можемо використовувати наступну описову статистику, щоб отримати уявлення про те, де знаходиться центр набору даних:
- Середній: 16,3
- Медіана: 14,5
- Режим: 13
Ми можемо використовувати наступну описову статистику, щоб отримати уявлення про розподіл значень у наборі даних:
- Діапазон: 31
- Стандартне відхилення: 9,0618
Нарешті, ми можемо використовувати наступну описову статистику, щоб зрозуміти загальну кількість спостережень у наборі даних:
- Розмір вибірки: 20
Використовуючи ці шість описових статистичних даних, ми можемо отримати досить добре розуміння розподілу значень у цьому наборі даних.
Додаткові ресурси
Описова чи інференційна статистика: у чому різниця?
Діапазон проти Стандартне відхилення: коли використовувати кожне
Середнє проти медіани: коли використовувати кожне
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше