Як виконати тест тьюкі в sas
Односторонній дисперсійний аналіз використовується для визначення того, чи існує статистично значуща різниця між середніми значеннями трьох або більше незалежних груп.
Якщо загальне p-значення таблиці ANOVA нижче певного рівня значущості, то ми маємо достатньо доказів, щоб стверджувати, що принаймні одне з групових середніх відрізняється від інших.
Однак це не говорить нам , які групи відрізняються одна від одної. Це просто говорить нам про те, що не всі середні групові показники однакові.
Для того, щоб точно знати, які групи відрізняються одна від одної, нам потрібно провести ретельний тест .
Одним із найбільш часто використовуваних репресивних тестів є тест Тьюкі , який дозволяє нам виконувати попарні порівняння між середніми значеннями кожної групи, контролюючи при цьому частоту помилок у групі .
У наступному прикладі показано, як виконати тест Тьюкі в R.
Приклад: тест Тьюкі в SAS
Припустімо, що дослідник набирає 30 студентів для участі в дослідженні. Для підготовки до іспиту студенти випадковим чином розподіляються для використання одного з трьох методів навчання.
Результати іспитів для кожного студента наведено нижче:
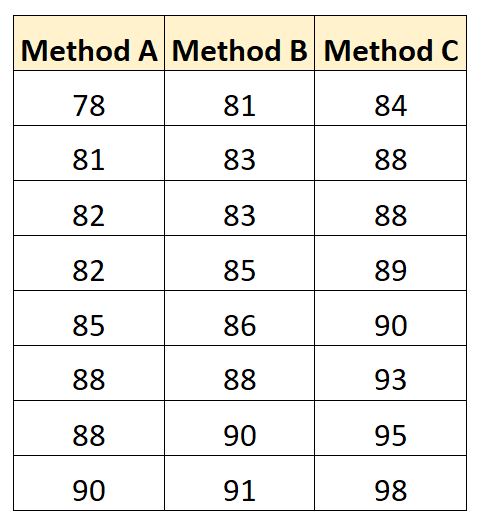
Ми можемо використати такий код, щоб створити цей набір даних у SAS:
/*create dataset*/
data my_data;
input Method $Score;
datalines ;
At 78
At 81
At 82
At 82
At 85
At 88
At 88
At 90
B 81
B 83
B 83
B85
B 86
B 88
B90
B91
C 84
C 88
C 88
C 89
C 90
C 93
C 95
C 98
;
run ;
Далі ми використаємо proc ANOVA для виконання одностороннього ANOVA:
/*perform one-way ANOVA*/
proc ANOVA data =my_data;
classMethod ;
modelScore = Method;
means Method / tukey cldiff ;
run ;
Примітка . Ми використали оператор середнього значення разом із опціями tukey та cldiff , щоб вказати, що слід виконувати тест Tukey post hoc (з довірчими інтервалами), якщо загальне значення p від одностороннього дисперсійного аналізу є статистично значущим. значний.
Спочатку ми проаналізуємо таблицю ANOVA в результаті:
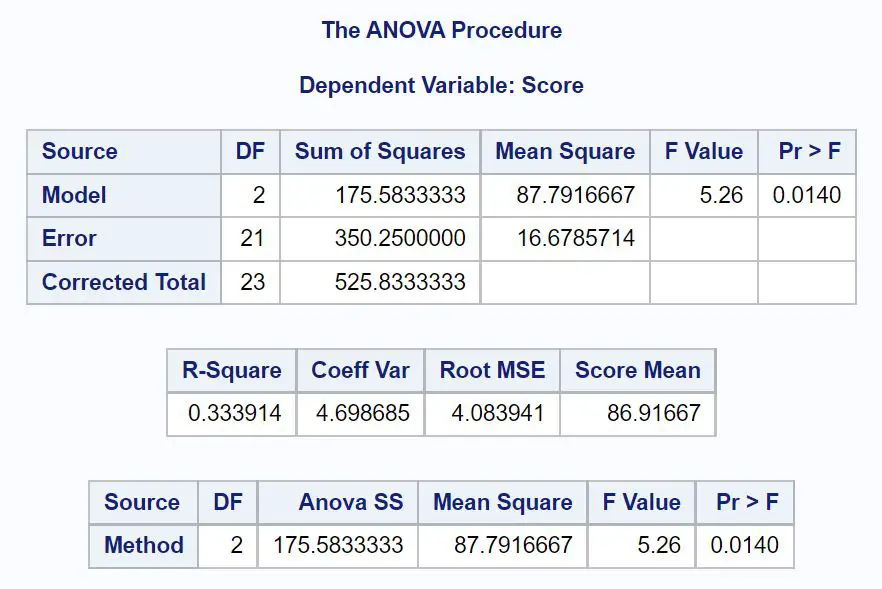
З цієї таблиці ми бачимо:
- Загальне F-значення: 5,26
- Відповідне p-значення: 0,0140
Нагадаємо, що односторонній дисперсійний аналіз використовує такі нульові та альтернативні гіпотези:
- H 0 : Усі групові середні рівні.
- H A : Принаймні одна середня група відрізняється відпочинок.
Оскільки p-значення таблиці ANOVA (0,0140) менше α = 0,05, ми відхиляємо нульову гіпотезу.
Це говорить нам про те, що середня оцінка іспиту не однакова для трьох методів навчання.
Пов’язане: Як інтерпретувати F-значення та P-значення в ANOVA
Щоб точно визначити, які групові середні відрізняються, нам потрібно звернутися до таблиці остаточних результатів, яка показує результати пост-хок тестів Тьюкі:
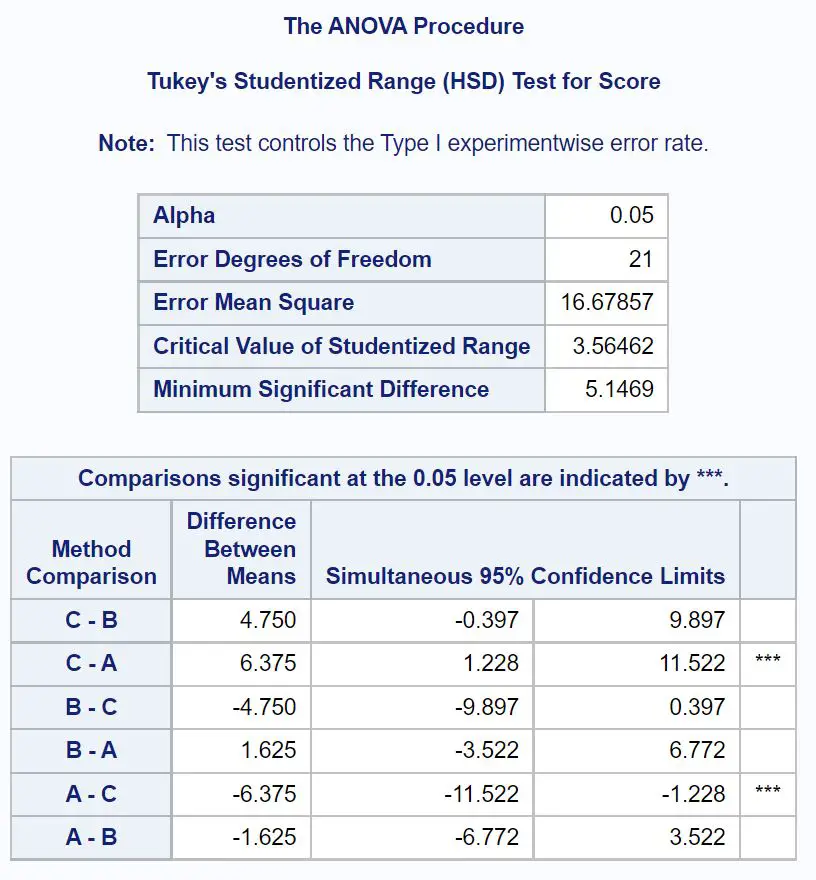
Щоб з’ясувати, які середні групи відрізняються, нам потрібно подивитися, які парні порівняння мають зірочки ( *** ).
З таблиці ми бачимо, що існує статистично значуща різниця в середніх іспитових балах між групою А та групою С.
Статистично значущих відмінностей між середніми показниками інших груп немає.
Додаткові ресурси
У наступних посібниках надається додаткова інформація про моделі ANOVA:
Посібник із використання пост-хок тестування з ANOVA
Як виконати односторонній дисперсійний аналіз у SAS
Як виконати двосторонній дисперсійний аналіз у SAS
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше