Excel: як видалити повторювані рядки на основі стовпця
Часто вам може знадобитися видалити повторювані рядки на основі стовпця в Excel.
На щастя, це легко зробити за допомогою функції «Видалити дублікати» на вкладці «Дані» .
У наступному прикладі показано, як використовувати цю функцію на практиці.
Приклад: видалення дублікатів на основі стовпця в Excel
Припустімо, у нас є такий набір даних у Excel, який містить інформацію про різних баскетболістів:
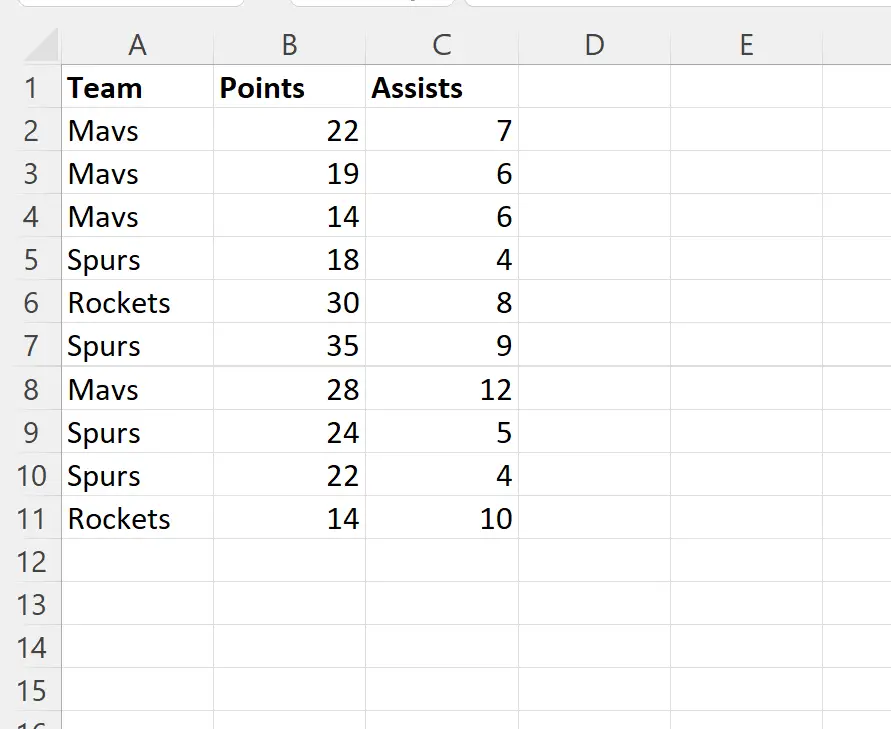
Зверніть увагу, що в стовпці Команда є кілька повторюваних значень.
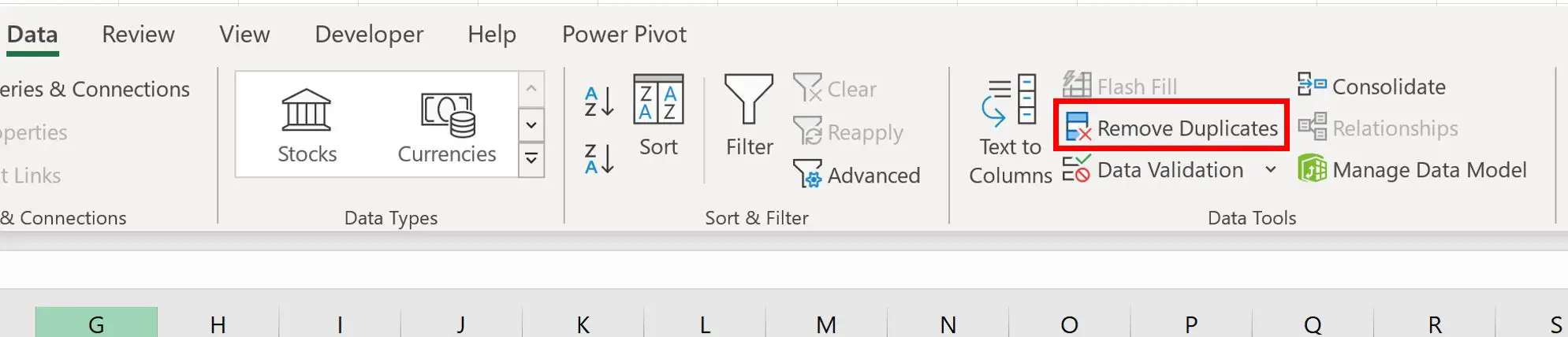
Щоб видалити рядки з повторюваними значеннями в стовпці «Команда» , виділіть діапазон клітинок A1:C11 , потім клацніть вкладку «Дані» на верхній стрічці, а потім клацніть «Видалити дублікати» :
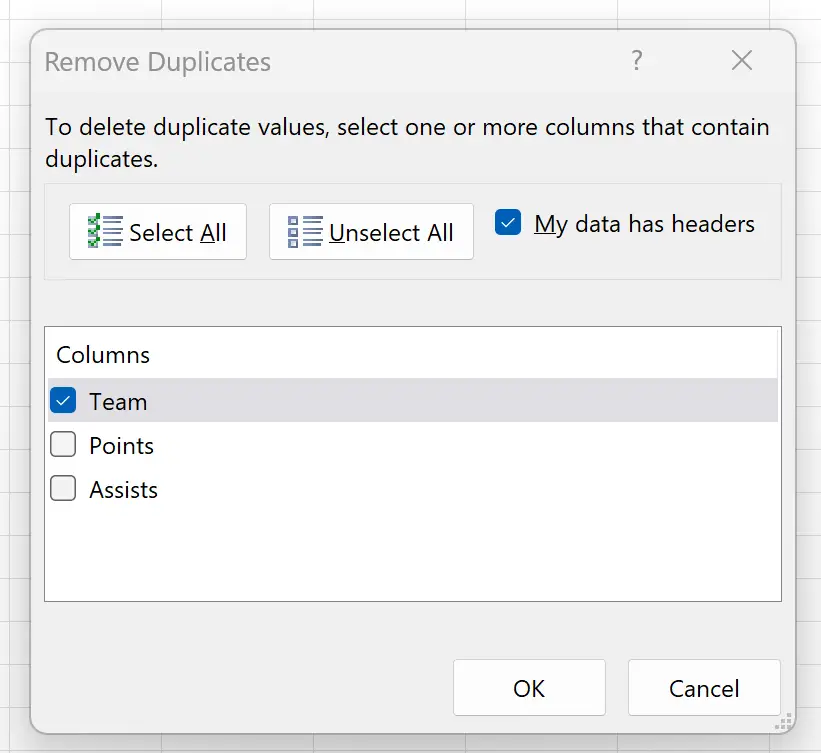
У новому вікні, яке з’явиться, переконайтеся, що встановлено прапорець біля пункту Мої дані мають заголовки та переконайтеся, що позначено лише поле біля пункту Команда :
Після натискання кнопки OK рядки з повторюваними значеннями в стовпці Команда будуть автоматично видалені:
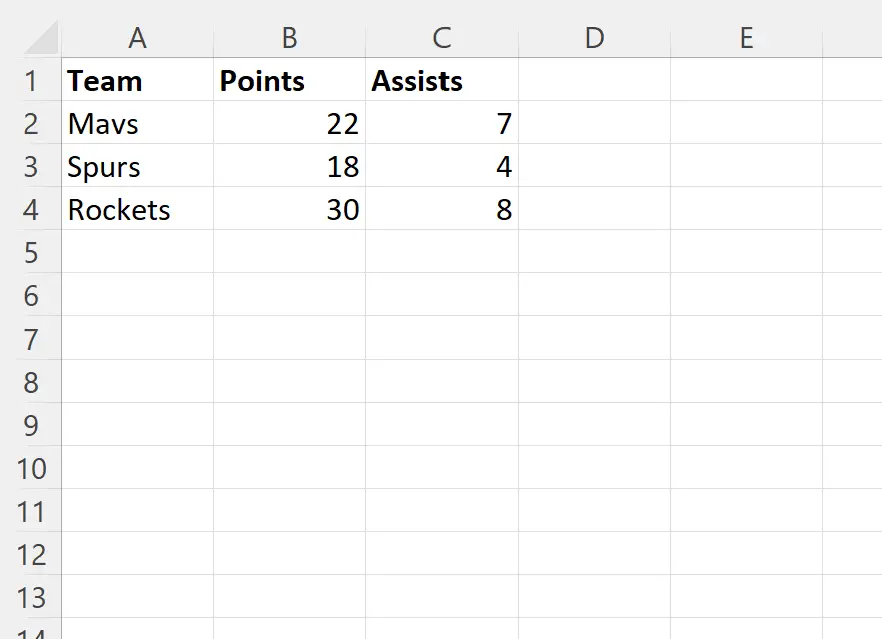
Excel повідомляє нам, що 7 повторюваних рядків було знайдено та видалено, а 3 унікальні рядки залишилися.
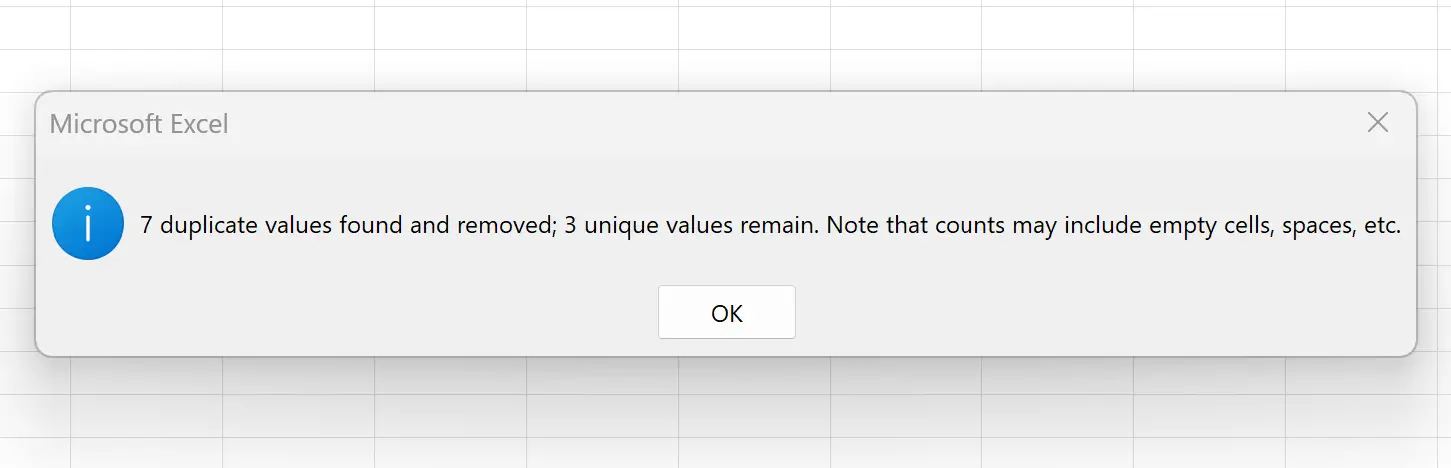
Зверніть увагу, що жоден із решти рядків не має повторюваних значень у стовпці Команда .
Також зауважте, що рядок, який містить перше повторення кожної унікальної назви команди, зберігається.
Наприклад:
- Рядок із «Мавс», 22 очками та 7 передачами — це перший рядок у наборі даних із «Мавс» у стовпці «Команда» .
- Рядок із «Шпорами», 18 очками та 4 передачами — це перший рядок у наборі даних із «Шпорами» у стовпці «Команда ».
І так далі.
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові операції в Excel:
Excel: як видалити рядки з певним текстом
Excel: як ігнорувати порожні клітинки під час використання формул
Розширений фільтр Excel: показує рядки з непорожніми значеннями
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше