Як виконати вкладений дисперсійний аналіз у r (покроково)
Вкладений ANOVA – це тип ANOVA («дисперсійний аналіз»), у якому принаймні один фактор вкладено в інший фактор.
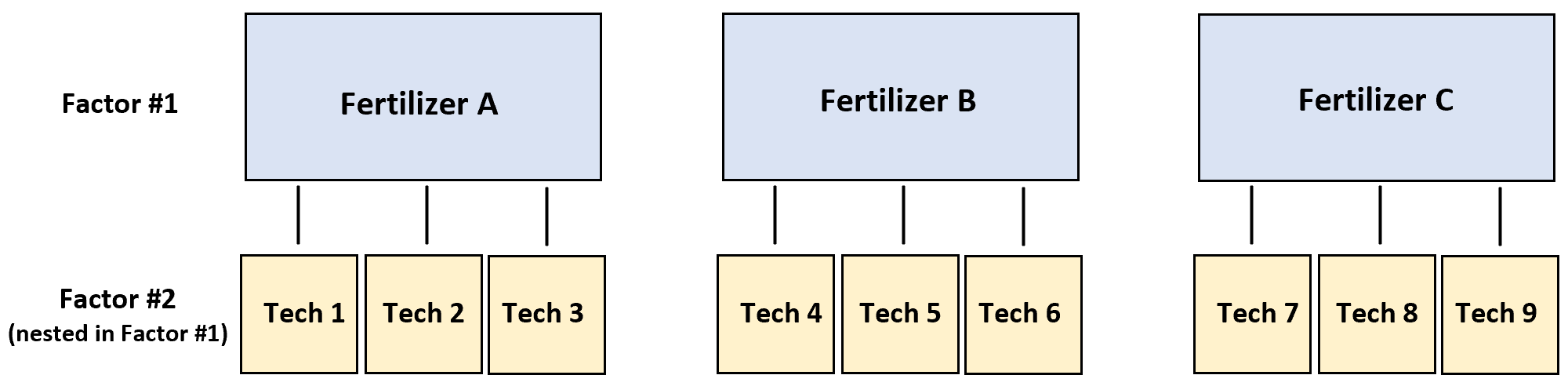
Наприклад, припустімо, що дослідник хоче знати, чи три різні добрива забезпечують різний рівень росту рослин.
Щоб перевірити це, три різних технічних спеціаліста посипають добривом A чотири рослини, три інших технічних спеціаліста посипають добривом B чотири рослини, а ще три технічні спеціалісти посипають добривом C чотири рослини.
У цьому сценарії змінною реакції є ріст рослин, а двома факторами є техніка та добриво. Виявляється, технік затиснувся на добриві:
Наступний покроковий приклад показує, як виконати цей вкладений дисперсійний аналіз у R.
Крок 1: Створіть дані
Спочатку давайте створимо фрейм даних для зберігання наших даних у R:
#create data df <- data. frame (growth=c(13, 16, 16, 12, 15, 16, 19, 16, 15, 15, 12, 15, 19, 19, 20, 22, 23, 18, 16, 18, 19, 20, 21, 21, 21, 23, 24, 22, 25, 20, 20, 22, 24, 22, 25, 26), fertilizer=c(rep(c(' A ', ' B ', ' C '), each= 12 )), tech=c(rep(1:9, each= 4 ))) #view first six rows of data head(df) growth fertilizer tech 1 13 A 1 2 16 A 1 3 16 A 1 4 12 A 1 5 15 A 2 6 16 A 2
Крок 2: Налаштуйте вкладений дисперсійний аналіз
Ми можемо використовувати наступний синтаксис, щоб підібрати вкладений ANOVA в R:
aov(відповідь ~ фактор A / фактор B)
золото:
- відповідь: змінна відповіді
- фактор А: перший фактор
- фактор B: другий фактор, вкладений у перший фактор
Наступний код показує, як підібрати вкладений ANOVA для нашого набору даних:
#fit nested ANOVA nest <- aov(df$growth ~ df$fertilizer / factor(df$tech)) #view summary of nested ANOVA summary(nest) Df Sum Sq Mean Sq F value Pr(>F) df$fertilizer 2 372.7 186.33 53.238 4.27e-10 *** df$fertilizer:factor(df$tech) 6 31.8 5.31 1.516 0.211 Residuals 27 94.5 3.50 --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Крок 3: Інтерпретація результату
Ми можемо подивитися на стовпець p-значення, щоб визначити, чи кожен фактор має статистично значущий вплив на ріст рослин.
З таблиці вище ми бачимо, що добриво має статистично значущий вплив на ріст рослин (p-value < 0,05), але технічне застосування ні (p-value = 0,211).
Це говорить нам про те, що якщо ми хочемо збільшити ріст рослин, нам потрібно зосередитися на добриві, яке використовується, а не на окремому техніку, який вносить добрива.
Крок 4: Візуалізуйте результати
Нарешті, ми можемо використовувати коробкові діаграми, щоб візуалізувати розподіл росту рослин за добривами та техніками:
#load ggplot2 data visualization package library (ggplot2) #create boxplots to visualize plant growth ggplot(df, aes (x=factor(tech), y=growth, fill=fertilizer)) + geom_boxplot()
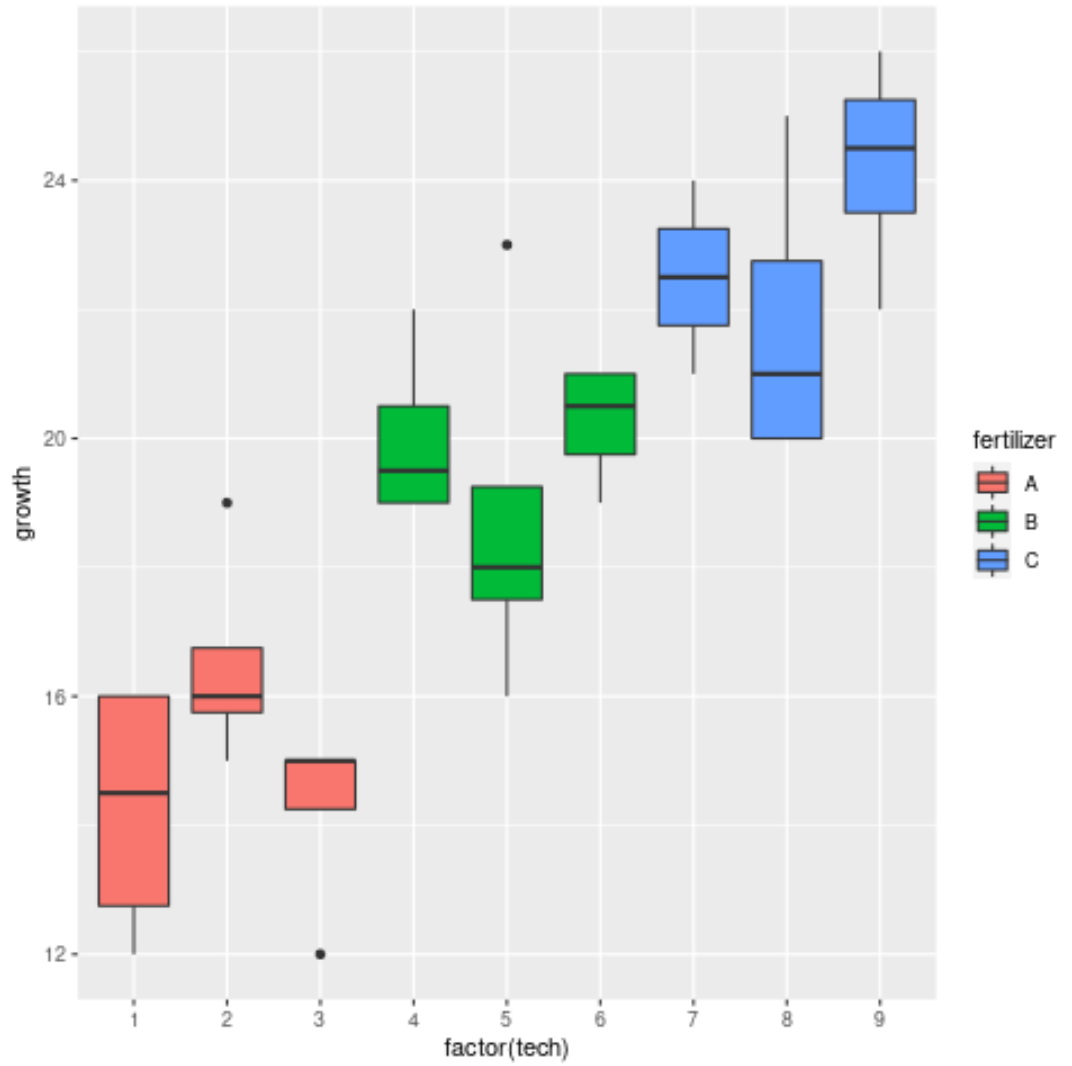
Графік показує, що існує значна різниця у зростанні між трьома різними добривами, але не така велика різниця між техніками в кожній групі добрив.
Це збігається з результатами вкладеного дисперсійного аналізу та підтверджує, що добрива мають значний вплив на ріст рослин, але окремі техніки цього не роблять.
Додаткові ресурси
Як виконати односторонній дисперсійний аналіз у R
Як виконати двосторонній дисперсійний аналіз у R
Як виконати повторний аналіз ANOVA у R
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше