Кластеризація k-means у python: покроковий приклад
Один із найпоширеніших алгоритмів кластеризації в машинному навчанні відомий як кластеризація k-середніх .
Кластеризація K-означає – це техніка, за якої ми поміщаємо кожне спостереження з набору даних в один із K кластерів.
Кінцева мета полягає в тому, щоб мати K кластерів, у яких спостереження в кожному кластері досить подібні одне до одного, тоді як спостереження в різних кластерах досить відрізняються одне від одного.
На практиці ми використовуємо такі кроки для кластеризації K-середніх:
1. Виберіть значення для K.
- По-перше, нам потрібно вирішити, скільки кластерів ми хочемо визначити в даних. Часто нам просто потрібно перевірити кілька різних значень K і проаналізувати результати, щоб побачити, яка кількість кластерів є найбільш доцільною для даної проблеми.
2. Випадково призначте кожне спостереження початковому кластеру від 1 до K.
3. Виконуйте наступну процедуру, доки призначення кластера не перестануть змінюватися.
- Для кожного з K кластерів обчисліть центр тяжіння кластера. Це просто вектор p- середніх ознак для спостережень k-го кластера.
- Призначте кожне спостереження кластеру з найближчим центроїдом. Тут найближче визначається за допомогою евклідової відстані .
Наступний покроковий приклад показує, як виконати кластеризацію k-means у Python за допомогою функції KMeans із модуля sklearn .
Крок 1: Імпортуйте необхідні модулі
Спочатку ми імпортуємо всі модулі, які нам знадобляться для кластеризації k-середніх:
import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
from sklearn. cluster import KMeans
from sklearn. preprocessing import StandardScaler
Крок 2: Створіть DataFrame
Далі ми створимо DataFrame, що містить наступні три змінні для 20 різних баскетболістів:
- балів
- допомогти
- підстрибує
Наступний код показує, як створити цей pandas DataFrame:
#createDataFrame
df = pd. DataFrame ({' points ': [18, np.nan, 19, 14, 14, 11, 20, 28, 30, 31,
35, 33, 29, 25, 25, 27, 29, 30, 19, 23],
' assists ': [3, 3, 4, 5, 4, 7, 8, 7, 6, 9, 12, 14,
np.nan, 9, 4, 3, 4, 12, 15, 11],
' rebounds ': [15, 14, 14, 10, 8, 14, 13, 9, 5, 4,
11, 6, 5, 5, 3, 8, 12, 7, 6, 5]})
#view first five rows of DataFrame
print ( df.head ())
points assists rebounds
0 18.0 3.0 15
1 NaN 3.0 14
2 19.0 4.0 14
3 14.0 5.0 10
4 14.0 4.0 8
Ми використаємо кластеризацію k-середніх, щоб згрупувати подібних акторів на основі цих трьох показників.
Крок 3: Очистіть і підготуйте DataFrame
Потім ми виконаємо наступні кроки:
- Використовуйте dropna() , щоб видалити рядки зі значеннями NaN у будь-якому стовпці
- Використовуйте StandardScaler() , щоб масштабувати кожну змінну, щоб мати середнє значення 0 і стандартне відхилення 1.
Наступний код показує, як це зробити:
#drop rows with NA values in any columns df = df. dropna () #create scaled DataFrame where each variable has mean of 0 and standard dev of 1 scaled_df = StandardScaler(). fit_transform (df) #view first five rows of scaled DataFrame print (scaled_df[:5]) [[-0.86660275 -1.22683918 1.72722524] [-0.72081911 -0.96077767 1.45687694] [-1.44973731 -0.69471616 0.37548375] [-1.44973731 -0.96077767 -0.16521285] [-1.88708823 -0.16259314 1.45687694]]
Примітка . Ми використовуємо масштабування, щоб кожна змінна мала однакову важливість під час підгонки алгоритму k-середніх. Інакше змінні з найширшим діапазоном мали б занадто великий вплив.
Крок 4: Знайдіть оптимальну кількість кластерів
Щоб виконати кластеризацію k-means у Python, ми можемо використати функцію KMeans із модуля sklearn .
Ця функція використовує такий базовий синтаксис:
KMeans(init=’random’, n_clusters=8, n_init=10, random_state=None)
золото:
- init : керує технікою ініціалізації.
- n_clusters : кількість кластерів, у які слід помістити спостереження.
- n_init : кількість ініціалізацій для виконання. За замовчуванням алгоритм k-середніх виконується 10 разів і повертає той із найнижчим SSE.
- random_state : ціле число, яке ви можете вибрати, щоб зробити результати алгоритму відтворюваними.
Найважливішим аргументом цієї функції є n_clusters, який визначає, у скільки кластерів слід помістити спостереження.
Однак ми не знаємо заздалегідь, яка кількість кластерів є оптимальною, тому нам потрібно створити графік, який відображає кількість кластерів, а також SSE (суму квадратів помилок) моделі.
Як правило, коли ми створюємо такий тип графіка, ми шукаємо «коліно», де сума квадратів починає «згинатися» або вирівнюватися. Загалом це оптимальна кількість кластерів.
Наступний код показує, як створити цей тип діаграми, яка відображає кількість кластерів на осі X і SSE на осі Y:
#initialize kmeans parameters kmeans_kwargs = { " init ": " random ", " n_init ": 10, " random_state ": 1, } #create list to hold SSE values for each k sse = [] for k in range(1, 11): kmeans = KMeans(n_clusters=k, ** kmeans_kwargs) kmeans. fit (scaled_df) sse. append (kmeans.inertia_) #visualize results plt. plot (range(1, 11), sse) plt. xticks (range(1, 11)) plt. xlabel (" Number of Clusters ") plt. ylabel (“ SSE ”) plt. show ()
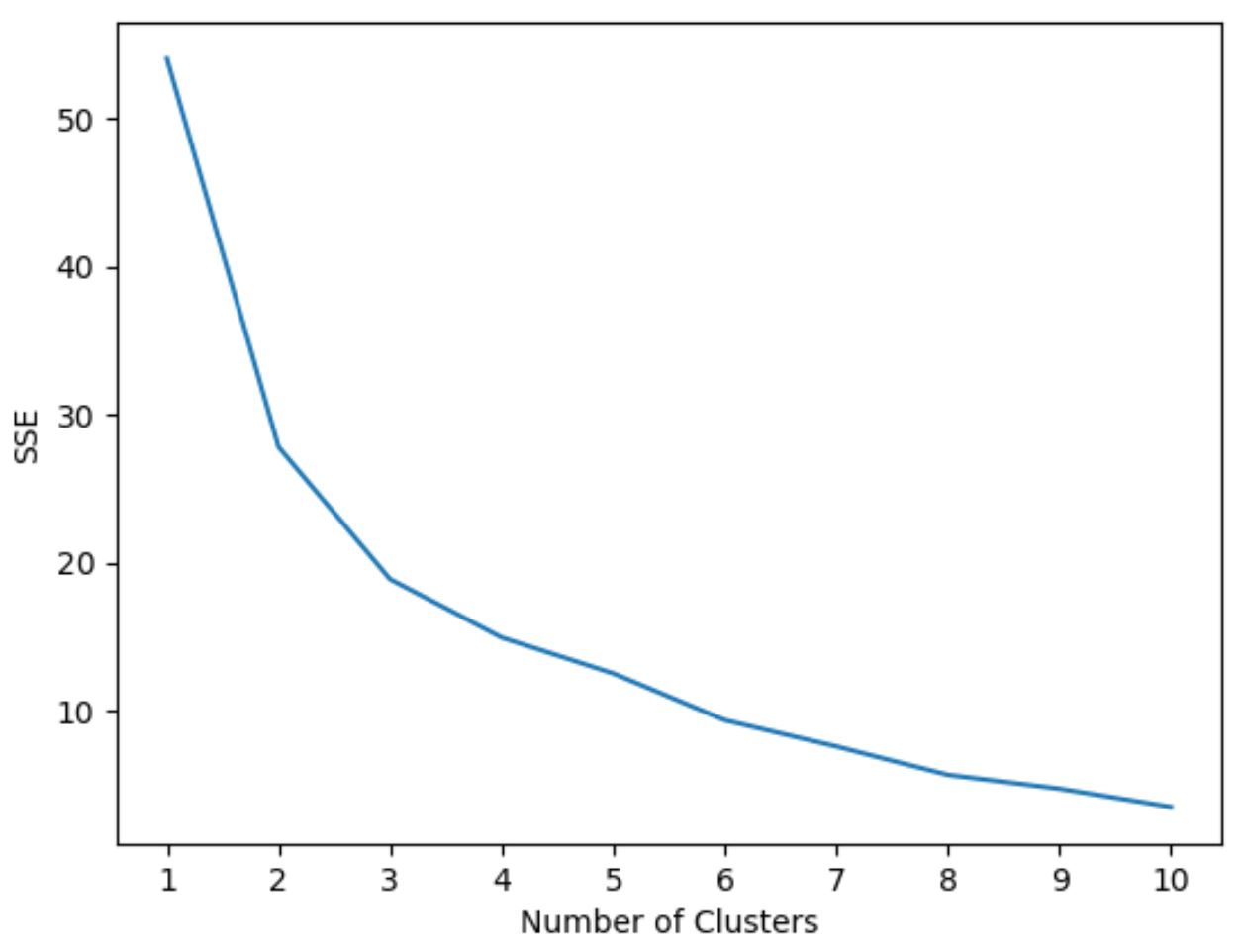
На цьому графіку видно, що є згин або «коліно» при k = 3 кластерах .
Отже, ми будемо використовувати 3 кластери під час адаптації нашої моделі кластеризації k-середніх на наступному кроці.
Примітка : у реальному світі рекомендується використовувати комбінацію цього сюжету та досвіду домену, щоб вибрати кількість кластерів для використання.
Крок 5: Виконайте кластеризацію K-середніх із оптимальним K
У наведеному нижче коді показано, як виконати кластеризацію k-середніх для набору даних, використовуючи оптимальне значення для k , рівне 3:
#instantiate the k-means class, using optimal number of clusters
kmeans = KMeans(init=" random ", n_clusters= 3 , n_init= 10 , random_state= 1 )
#fit k-means algorithm to data
kmeans. fit (scaled_df)
#view cluster assignments for each observation
kmeans. labels_
array([1, 1, 1, 1, 1, 1, 2, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0])
Отримана таблиця показує призначення кластерів для кожного спостереження в DataFrame.
Щоб полегшити інтерпретацію цих результатів, ми можемо додати стовпець до DataFrame, який показує кластерне призначення кожного гравця:
#append cluster assingments to original DataFrame
df[' cluster '] = kmeans. labels_
#view updated DataFrame
print (df)
points assists rebounds cluster
0 18.0 3.0 15 1
2 19.0 4.0 14 1
3 14.0 5.0 10 1
4 14.0 4.0 8 1
5 11.0 7.0 14 1
6 20.0 8.0 13 1
7 28.0 7.0 9 2
8 30.0 6.0 5 2
9 31.0 9.0 4 0
10 35.0 12.0 11 0
11 33.0 14.0 6 0
13 25.0 9.0 5 0
14 25.0 4.0 3 2
15 27.0 3.0 8 2
16 29.0 4.0 12 2
17 30.0 12.0 7 0
18 19.0 15.0 6 0
19 23.0 11.0 5 0
Стовпець кластера містить номер кластера (0, 1 або 2), до якого було призначено кожного гравця.
Гравці, що належать до одного кластеру, мають приблизно однакові значення для стовпців очок , передач і підбирань .
Примітка : повну документацію щодо функції KMeans sklearn можна знайти тут .
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в Python:
Як виконати лінійну регресію в Python
Як виконати логістичну регресію в Python
Як виконати перехресну перевірку K-Fold у Python
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше