Як виконати manova в stata
Односторонній дисперсійний аналіз використовується для визначення того, чи призводять різні рівні пояснювальної змінної до статистично різних результатів у певних змінних відповіді.
Наприклад, нам може бути цікаво зрозуміти, чи призводять три рівні освіти (ступінь молодшого спеціаліста, ступінь бакалавра, ступінь магістра) до статистично різних річних доходів. У цьому випадку ми маємо пояснювальну змінну та змінну відповіді.
- Пояснювальна змінна: рівень освіти
- Змінна відповіді: річний дохід
MANOVA — це розширення одностороннього дисперсійного аналізу, в якому є більше однієї змінної відповіді. Наприклад, нам може бути цікаво зрозуміти, чи призводить рівень освіти до різних річних доходів і різних сум студентського боргу. У цьому випадку ми маємо одну пояснювальну змінну та дві змінні відповіді:
- Пояснювальна змінна: рівень освіти
- Змінні відповіді: річний дохід, студентська заборгованість
Оскільки ми маємо більше однієї змінної відповіді, у цьому випадку було б доцільно використовувати MANOVA.
Далі ми пояснимо, як виконати MANOVA в Stata.
Приклад: MANOVA в Stata
Щоб проілюструвати, як виконати MANOVA у Stata, ми використаємо наступний набір даних, який містить наступні три змінні для 24 людей:
- educ: рівень навчання (0 = доцент, 1 = бакалавр, 2 = магістр)
- дохід: річний дохід
- борг: загальна заборгованість по студентській позиці
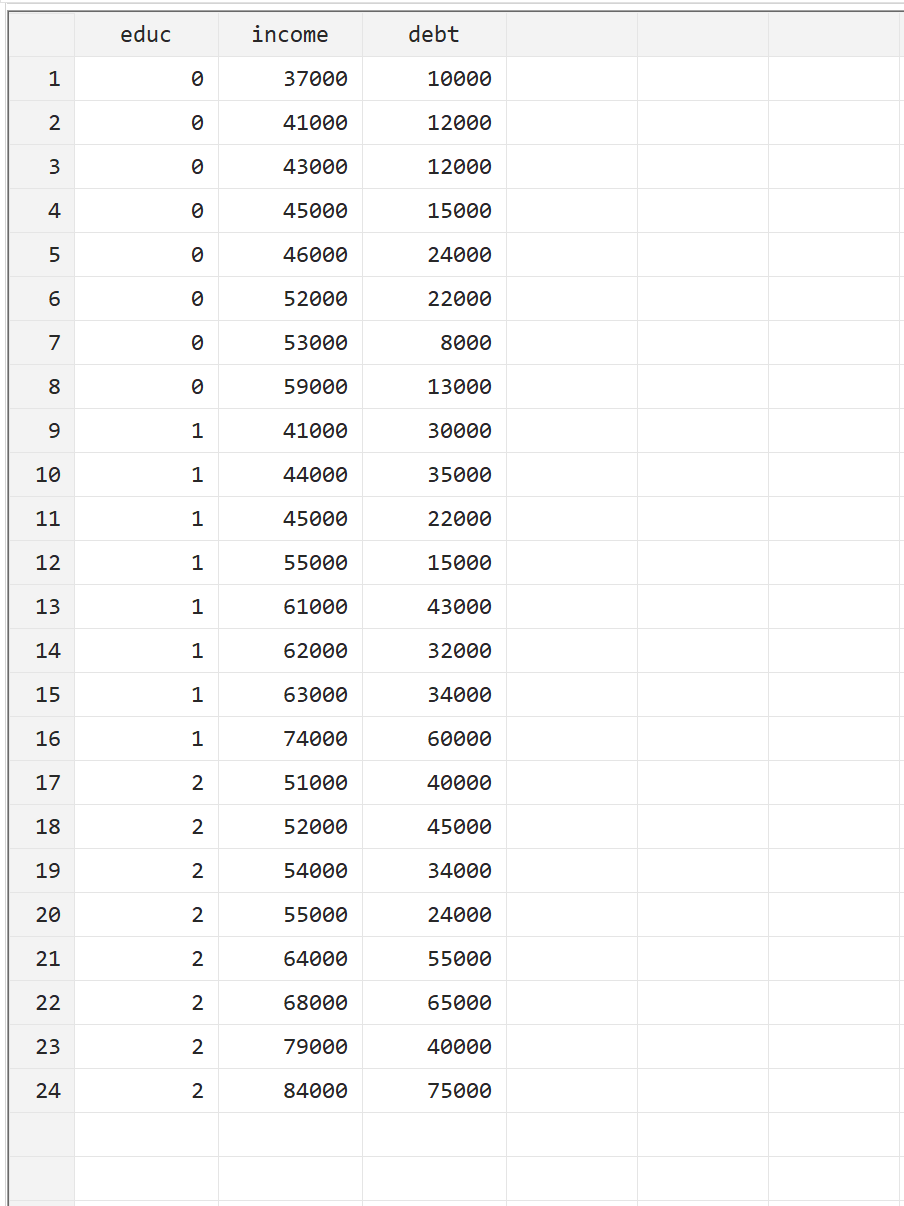
Ви можете відтворити цей приклад, самостійно ввівши дані вручну, перейшовши до «Дані» > «Редактор даних» > «Редактор даних (редагування)» у верхній панелі меню.
Щоб виконати MANOVA з використанням освіти як пояснювальної змінної та доходу та боргу як змінних відповіді, ми можемо використати таку команду:
прибуток борг манова = осв

Stata створює чотири унікальні статистичні дані разом із відповідними значеннями p:
Лямбда Вілкса: F-статистика = 5,02, значення P = 0,0023.
Крива Піллаї: F-статистика = 4,07, значення P = 0,0071.
Крива Лоулі-Хотеллінга: F-статистика = 5,94, значення P = 0,0008.
Найбільший корінь Роя: F-статистика = 13,10, P-значення = 0,0002.
Щоб отримати детальне пояснення того, як обчислюється кожна статистика тесту, зверніться до цієї статті від Наукового коледжу Пенсільванія Еберлі.
P-значення для кожної тестової статистики менше 0,05, тому нульову гіпотезу буде відхилено незалежно від того, яку з них ви використовуєте. Це означає, що ми маємо достатньо доказів, щоб стверджувати, що рівень освіти викликає статистично значущі відмінності в річному доході та загальній заборгованості студентів.
Примітка щодо p-значень: літера поруч із p-значенням у вихідній таблиці вказує, як було обчислено статистику F (e = точний розрахунок, a = приблизний розрахунок, u = верхня межа).
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше