Pandas: імпорт csv з різною кількістю стовпців у рядку
Ви можете використовувати наступний базовий синтаксис, щоб імпортувати файл CSV у pandas, якщо кількість стовпців у рядку різна:
df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))
Значення всередині функції range() має бути кількістю стовпців у рядку з максимальною кількістю стовпців.
У наступному прикладі показано, як використовувати цей синтаксис на практиці.
Приклад: імпорт CSV у Pandas з різною кількістю стовпців у рядку
Скажімо, у нас є такий файл CSV під назвою uneven_data.csv :
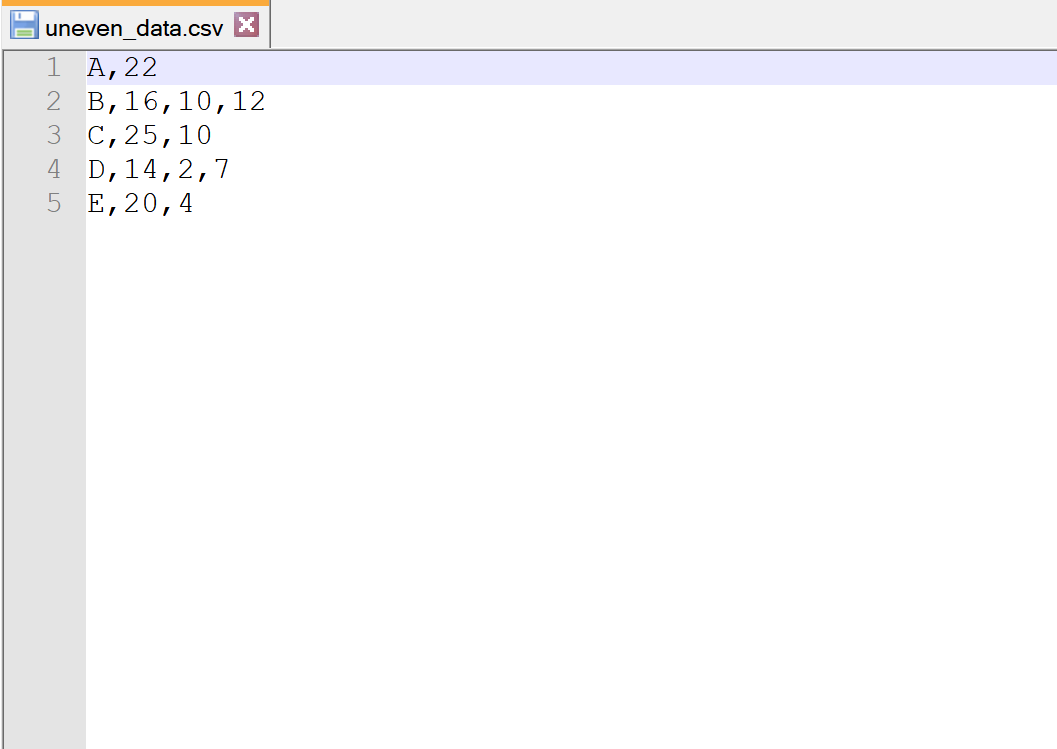
Зауважте, що кожен рядок не має однакової кількості стовпців.
Якщо ми спробуємо використати функцію read_csv() , щоб імпортувати цей файл CSV у pandas DataFrame, ми отримаємо помилку:
import pandas as pd #attempt to import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None ) ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 4
Ми отримуємо помилку ParserError , яка повідомляє нам, що pandas очікувала 2 поля (оскільки це була кількість стовпців у першому рядку), але побачила 4 .
Ця помилка повідомляє нам, що максимальна кількість стовпців у даному рядку становить 4 .
Отже, ми можемо імпортувати файл CSV і надати значення діапазону (4) для аргументу імен :
import pandas as pd #import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))) #view DataFrame print (df) 0 1 2 3 0 to 22 NaN NaN 1 B 16 10.0 12.0 2 C 25 10.0 NaN 3 D 14 2.0 7.0 4 E 20 4.0 NaN
Зверніть увагу, що ми можемо успішно імпортувати файл CSV у pandas DataFrame без будь-яких помилок, оскільки ми явно сказали pandas очікувати 4 стовпці.
За замовчуванням pandas заповнює всі відсутні значення в кожному рядку NaN.
Якщо ви хочете, щоб пропущені значення відображалися як нуль, ви можете використовувати функцію fillna() наступним чином:
#fill NaN values with zeros df_new = df. fillna ( 0 ) #view new DataFrame print (df_new) 0 1 2 3 0 to 22 0.0 0.0 1 B 16 10.0 12.0 2 C 25 10.0 0.0 3 D 14 2.0 7.0 4 E 20 4.0 0.0
Кожне значення NaN у DataFrame тепер замінено нулем.
Примітка : Ви можете знайти повну документацію функції pandas read_csv() тут .
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в Python:
Pandas: як пропускати рядки під час читання файлу CSV
Pandas: Як додати дані до наявного файлу CSV
Pandas: як указати типи під час імпортування файлу CSV
Pandas: установіть назви стовпців під час імпорту файлу CSV
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше