Повний посібник із набору даних diamond у r
Набір даних Diamond — це набір даних, вбудований у пакет ggplot2 у R.
Він містить вимірювання 10 різних змінних (як-от ціна, колір, прозорість тощо) для 53 940 різних діамантів.
У цьому підручнику пояснюється, як досліджувати, узагальнювати та візуалізувати набір даних алмазів у R.
Завантажити набір даних діаманта
Оскільки набір даних diamond є вбудованим набором даних у ggplot2, нам спочатку потрібно встановити (якщо ще не встановлено) і завантажити пакет ggplot2:
#install ggplot2 if not already installed
install. packages (' ggplot2 ')
#load ggplot2
library (ggplot2)
Після того, як ми завантажили ggplot2, ми можемо використовувати функцію data() для завантаження набору даних алмазу :
data(diamonds)
Ми можемо поглянути на перші шість рядків набору даних за допомогою функції head() :
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price xyz
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
Узагальніть набір даних алмазів
Ми можемо використовувати функцію summary() , щоб швидко підсумувати кожну змінну в наборі даних:
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair: 1610 D: 6775 SI1:13065 Min. :43.00
1st Qu.:0.4000 Good: 4906 E: 9797 VS2:12258 1st Qu.:61.00
Median: 0.7000 Very Good: 12082 F: 9542 SI2: 9194 Median: 61.80
Mean: 0.7979 Premium: 13791 G: 11292 VS1: 8171 Mean: 61.75
3rd Qu.:1.0400 Ideal:21551 H:8304 VVS2:5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1: 3655 Max. :79.00
D: 2808 (Other): 2531
table price xyz Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median: 57.00 Median: 2401 Median: 5.700 Median: 5.710 Median: 3.530
Mean: 57.46 Mean: 3933 Mean: 5.731 Mean: 5.735 Mean: 3.539
3rd Qu.: 59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10,740 Max. :58,900 Max. :31,800
Для кожної з числових змінних ми можемо побачити таку інформацію:
- Min : мінімальне значення.
- 1st Qu : значення першого квартиля (25-й процентиль).
- Медіана : середнє значення.
- Середнє : середнє значення.
- 3rd Qu : значення третього квартиля (75-й процентиль).
- Max : максимальне значення.
Для категоріальних змінних у наборі даних (вирізання, колір і чіткість) ми бачимо кількість частот кожного значення.
Наприклад, для змінної cut :
- Задовільно : це значення з’являється 1610 разів.
- Добре : це значення з’являється 4906 разів.
- Дуже добре : це значення з’являється 12 082 рази.
- Premium : це значення з’являється 13 791 раз.
- Ідеальний : це значення з’являється 21 551 раз.
Ми можемо використовувати функцію dim() , щоб отримати розміри набору даних у термінах кількості рядків і стовпців:
#display rows and columns
dim(diamonds)
[1] 53940 10
Ми бачимо, що набір даних містить 53 940 рядків і 10 стовпців.
Ми також можемо використовувати функцію names() для відображення імен стовпців кадру даних:
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] “y” “z”
Візуалізуйте набір даних Diamonds
Ми також можемо створювати графіки для візуалізації значень набору даних.
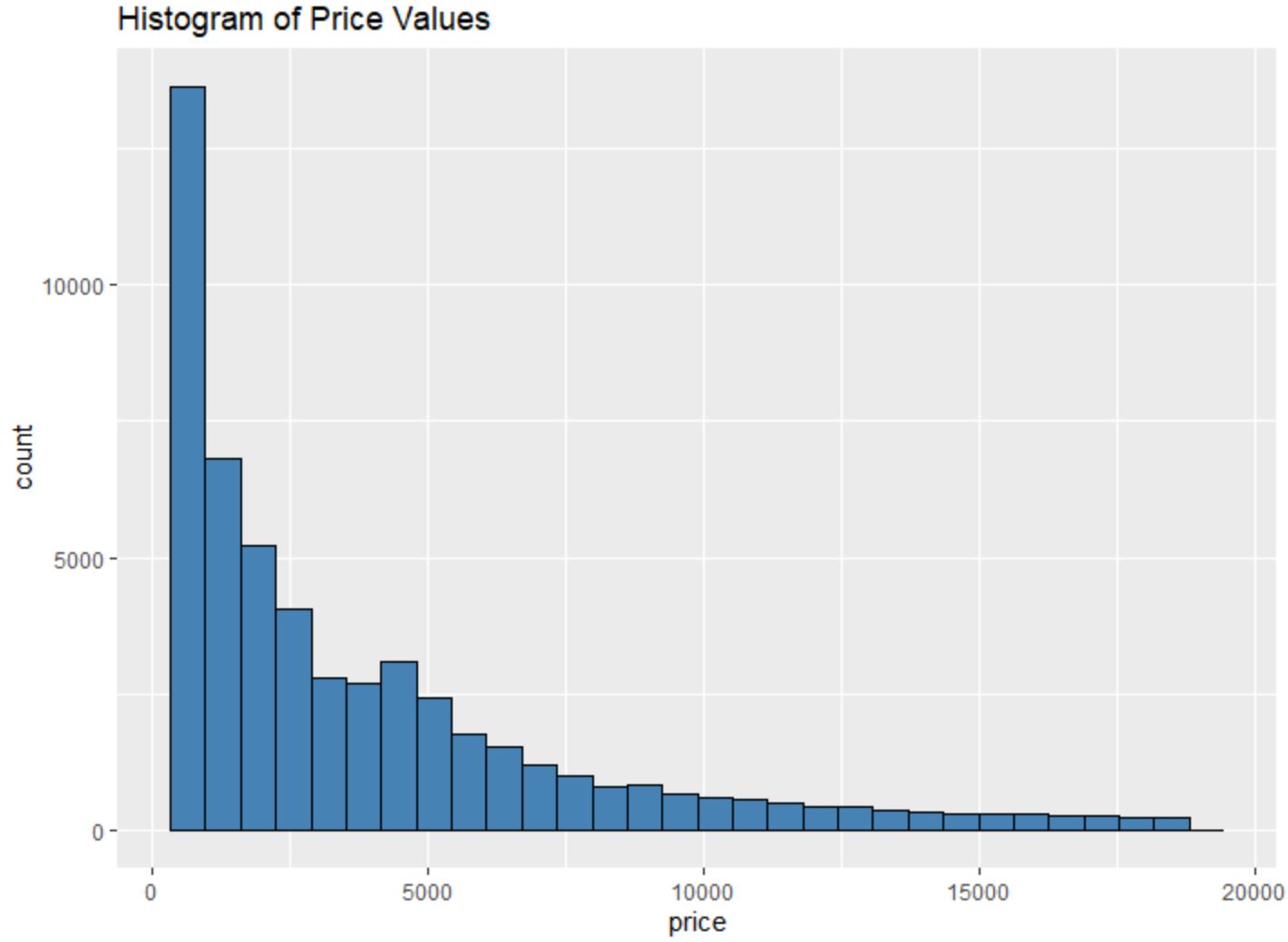
Наприклад, ми можемо використовувати функцію geom_histogram() , щоб створити гістограму значень певної змінної:
#create histogram of values for price
ggplot(data=diamonds, aes (x=price)) +
geom_histogram(fill=" steelblue ", color=" black ") +
ggtitle(" Histogram of Price Values ")
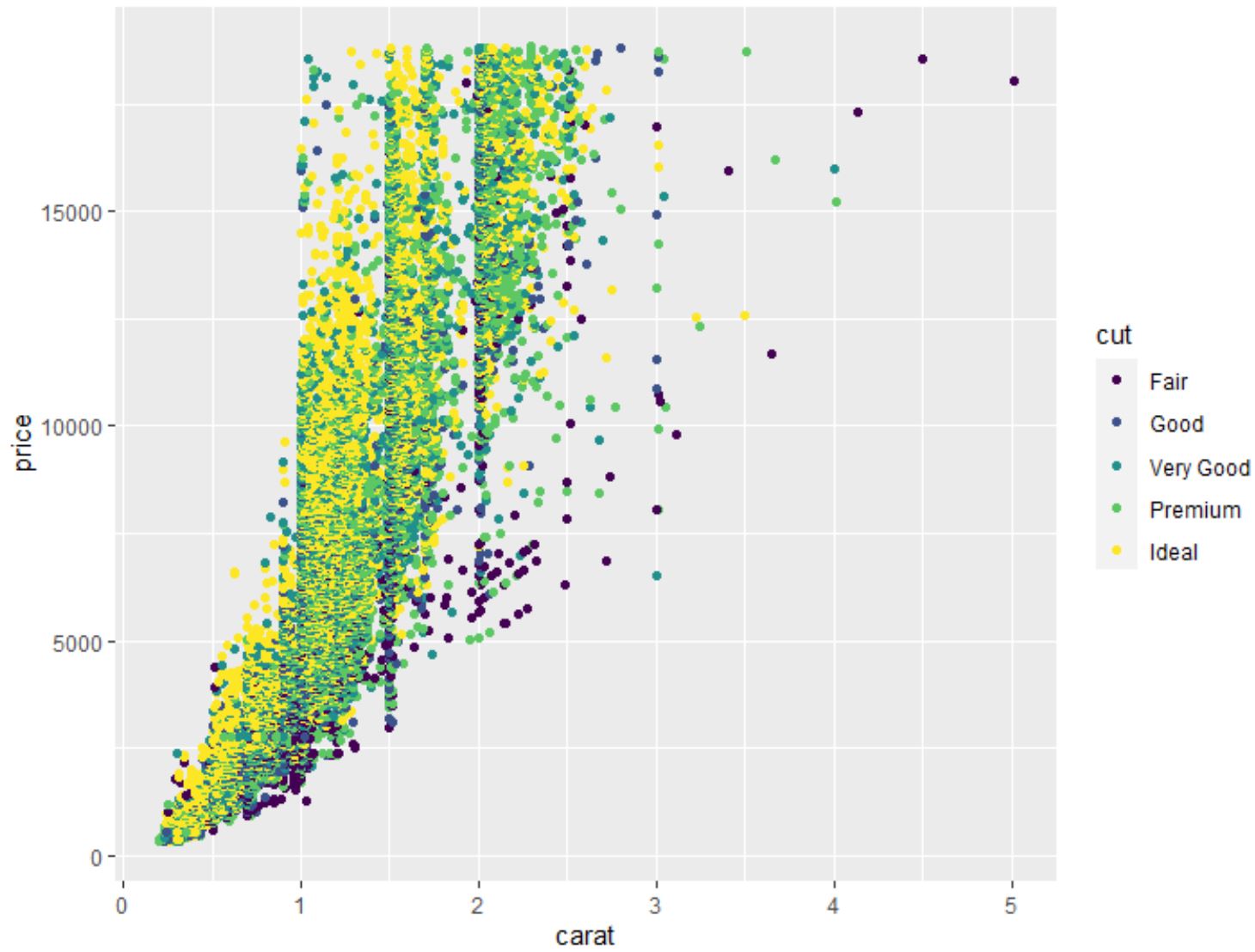
Ми також можемо використовувати функцію geom_point() , щоб створити хмару точок будь-якої попарної комбінації змінних:
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes (x=carat, y=price, color=cut)) +
geom_point()
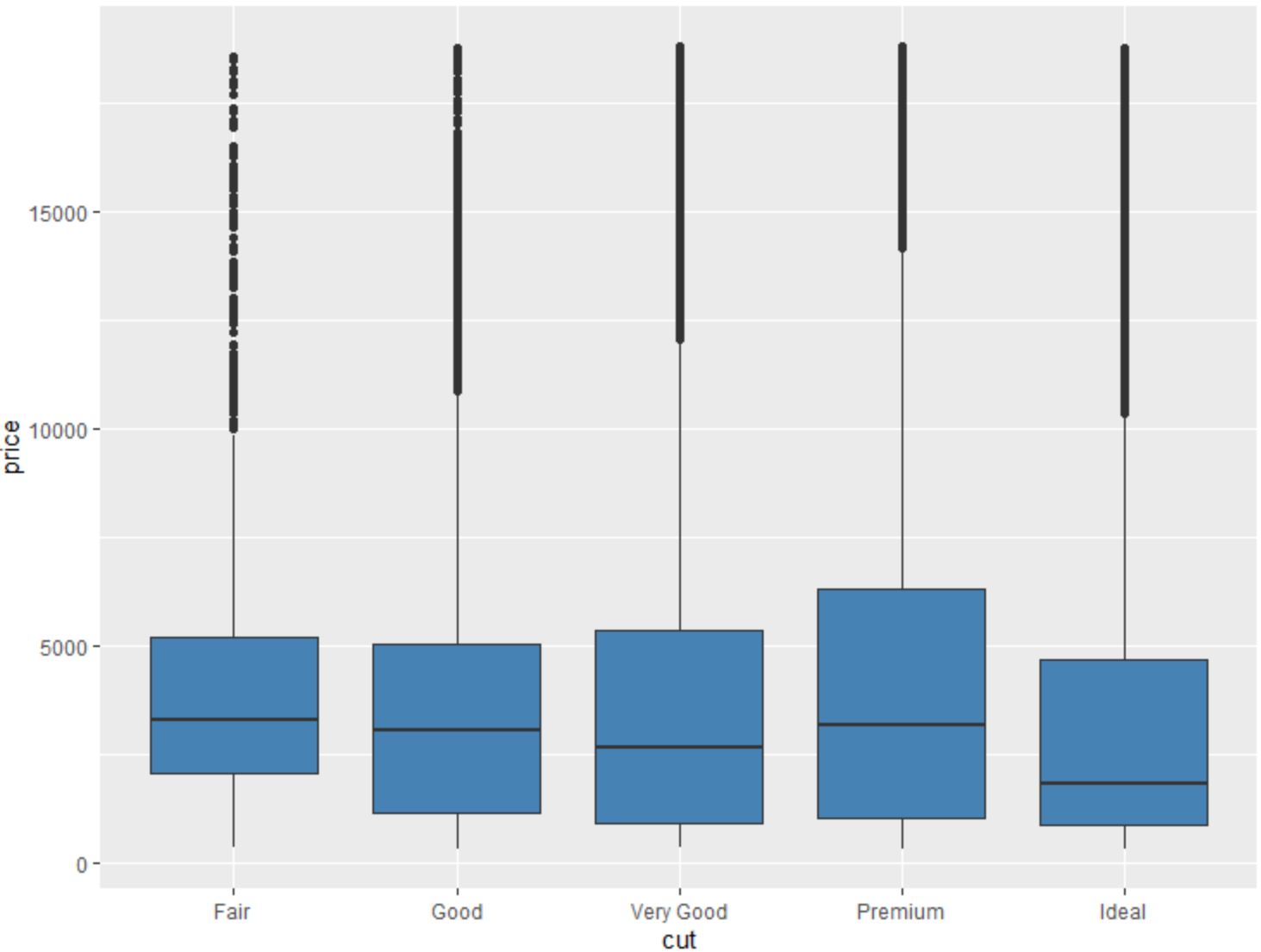
Ми також можемо використовувати функцію geom_boxplot() , щоб створити коробковий графік змінної, згрупованої за іншою змінною:
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes (x=cut, y=price)) +
geom_boxplot(fill=" steelblue ")
Використовуючи ці функції ggplot2, ми можемо багато чого дізнатися про змінні в наборі даних алмазів .
Додаткові ресурси
У наступних посібниках пояснюється, як досліджувати інші набори даних у R:
Повний посібник із набору даних Iris у R
Повний посібник із набору даних mtcars у R
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше