Як читати певні рядки з файлу csv у r
Ви можете використовувати такі методи, щоб прочитати певні рядки з файлу CSV у R:
Спосіб 1. Імпортуйте файл CSV із певного рядка
df <- read. csv (" my_data.csv ", skip= 2 )
У цьому конкретному прикладі буде пропущено перші два рядки файлу CSV та імпортовано всі інші рядки файлу, починаючи з третього рядка.
Спосіб 2. Імпортуйте файл CSV, у якому рядки відповідають умові
library (sqldf) df <- read. csv . sql (" my_data.csv ", sql = " select * from file where `points` > 90 ", eol = " \n ")
У цьому конкретному прикладі буде імпортовано лише рядки з файлу CSV, значення яких у стовпці «points» перевищує 90.
У наведених нижче прикладах показано, як використовувати кожен із цих методів на практиці з таким файлом CSV під назвою my_data.csv :
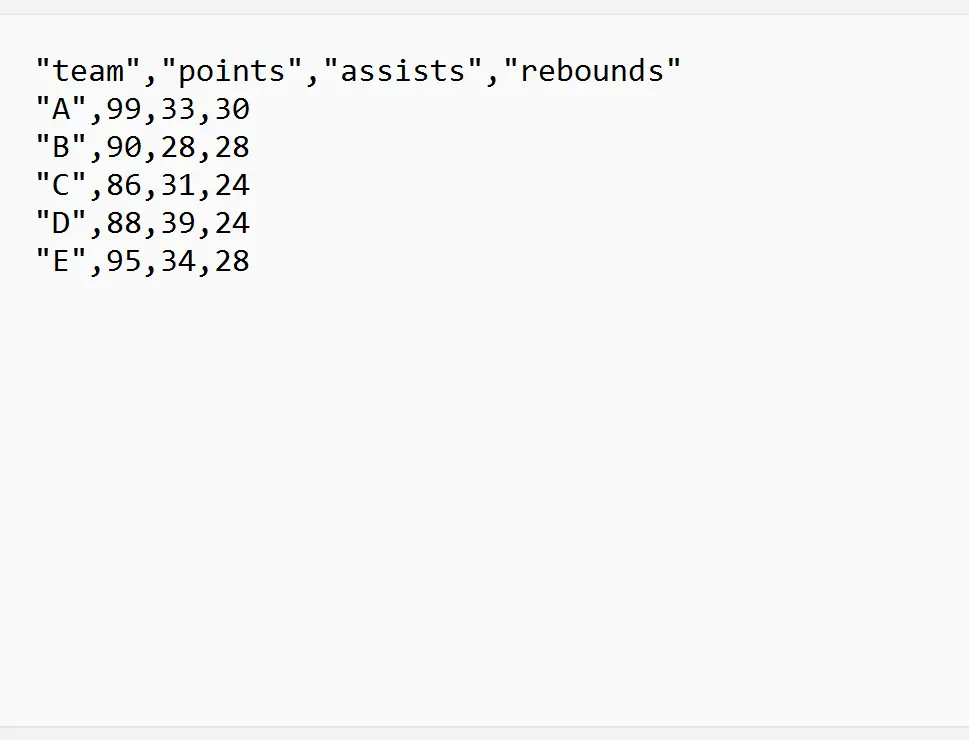
Приклад 1. Імпортуйте файл CSV із певного рядка
Наступний код показує, як імпортувати файл CSV і ігнорувати перші два рядки файлу:
#import data frame and skip first two rows
df <- read. csv (' my_data.csv ', skip= 2 )
#view data frame
df
B X90 X28 X28.1
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Зауважте, що перші два рядки (з командами A та B) були проігноровані під час імпортування файлу CSV.
За замовчуванням R намагається використовувати значення наступного доступного рядка як імена стовпців.
Щоб перейменувати стовпці, ви можете використовувати функцію names() наступним чином:
#rename columns
names(df) <- c(' team ', ' points ', ' assists ', ' rebounds ')
#view updated data frame
df
team points assists rebounds
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Приклад 2. Імпортуйте файл CSV, у якому рядки відповідають умові
Припустімо, ми хочемо імпортувати лише ті рядки з файлу CSV, значення яких у стовпці балів перевищує 90.
Для цього можна використати функцію read.csv.sql із пакета sqldf :
library (sqldf)
#only import rows where points > 90
df <- read. csv . sql (" my_data.csv ",
sql = " select * from file where `points` > 90 ", eol = " \n ")
#view data frame
df
team points assists rebounds
1 “A” 99 33 30
2 “E” 95 34 28
Зауважте, що було імпортовано лише два рядки файлу CSV, значення яких у стовпці «points» перевищує 90.
Примітка №1 : у цьому прикладі ми використали аргумент eol , щоб вказати, що «кінець рядка» у файлі позначається символом \n , який представляє новий рядок.
Примітка №2: у цьому прикладі ми використали простий запит SQL, але ви можете написати складніші запити, щоб фільтрувати рядки за ще більшою кількістю умов.
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в R:
Як читати CSV з URL-адреси в R
Як об’єднати декілька файлів CSV у R
Як експортувати фрейм даних у файл CSV у R
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше