Як використовувати оператор proc glmselect у sas
Ви можете використовувати інструкцію PROC GLMSELECT у SAS, щоб вибрати найкращу регресійну модель на основі списку потенційних змінних прогнозу.
У наступному прикладі показано, як використовувати цей оператор на практиці.
Приклад: як використовувати PROC GLMSELECT у SAS для вибору моделі
Припустімо, ми хочемо підібрати множинну лінійну регресійну модель, яка використовує (1) кількість годин, витрачених на навчання, (2) кількість складених підготовчих іспитів і (3) стать, щоб передбачити підсумковий іспит студентів.
Спочатку ми використаємо наступний код, щоб створити набір даних, що містить цю інформацію для 20 студентів:
/*create dataset*/ data exam_data; input hours prep_exams gender $score; datalines ; 1 1 0 76 2 3 1 78 2 3 0 85 4 5 0 88 2 2 0 72 1 2 1 69 5 1 1 94 4 1 0 94 2 0 1 88 4 3 0 92 4 4 1 90 3 3 1 75 6 2 1 96 5 4 0 90 3 4 0 82 4 4 1 85 6 5 1 99 2 1 0 83 1 0 1 62 2 1 0 76 ; run ; /*view dataset*/ proc print data =exam_data;
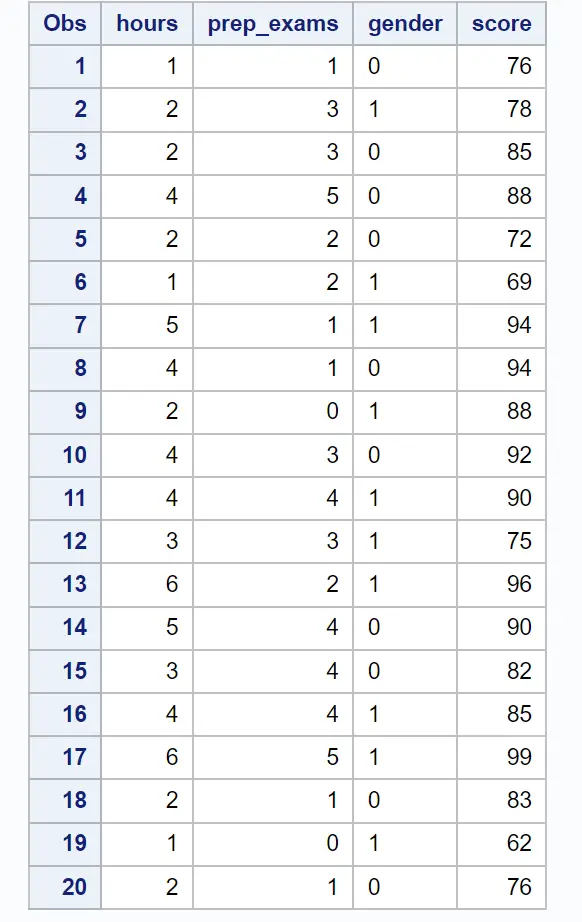
Далі ми використаємо інструкцію PROC GLMSELECT , щоб визначити підмножину змінних предикторів, які створюють найкращу модель регресії:
/*perform model selection*/
proc glmselect data =exam_data;
classgender ;
model score = hours prep_exams gender;
run ;
Примітка : ми включили стать у оператор класу , оскільки це категоріальна змінна.
Перша група таблиць у вихідних даних показує огляд процедури GLMSELECT:
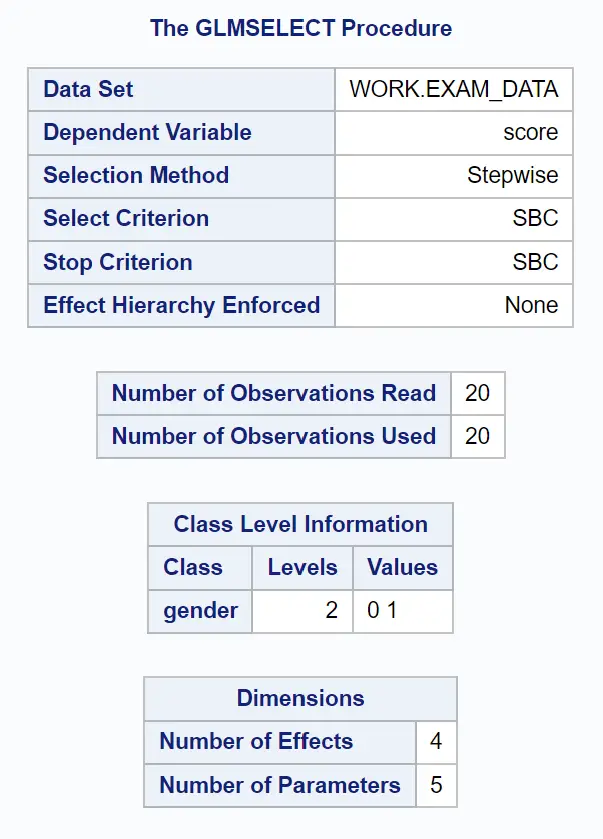
Ми бачимо, що критерієм, який використовувався для припинення додавання або видалення змінних із моделі, був SBC , який є інформаційним критерієм Шварца , який іноді називають байєсовським інформаційним критерієм .
По суті, оператор PROC GLMSELECT продовжує додавати або видаляти змінні з моделі, доки не знайде модель із найнижчим значенням SBC, яка вважається «найкращою» моделлю.
Наступна група таблиць показує, чим закінчився покроковий вибір:
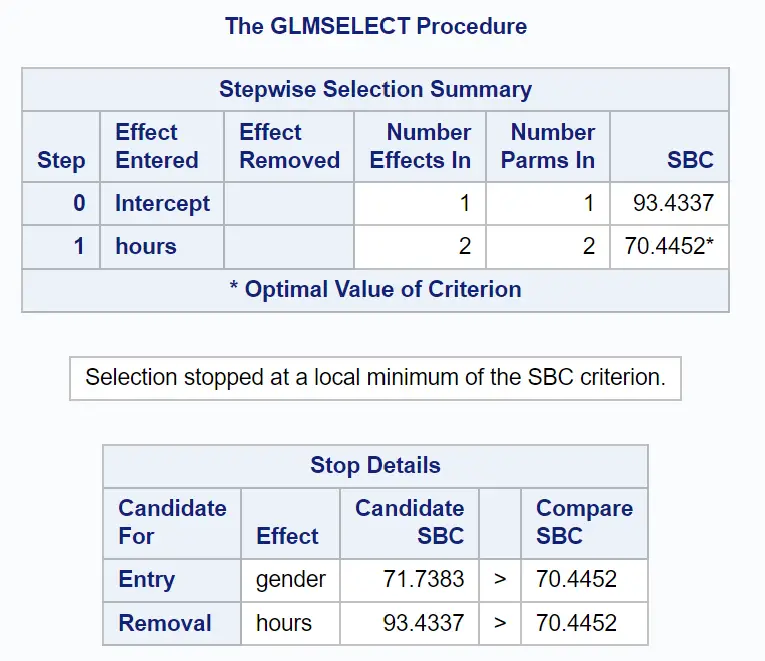
Ми бачимо, що модель лише з початковим терміном мала значення SBC 93,4337 .
Додавши години як змінну прогнозу в моделі, значення SBC впало до 70,4452 .
Найкращим способом удосконалити модель було додавання статі як змінної предиктора, але це фактично збільшило значення SBC до 71,7383.
Таким чином, остаточна модель включає лише термін перехоплення та досліджувані часи.
Остання частина результату показує підсумок цієї підігнаної моделі регресії:
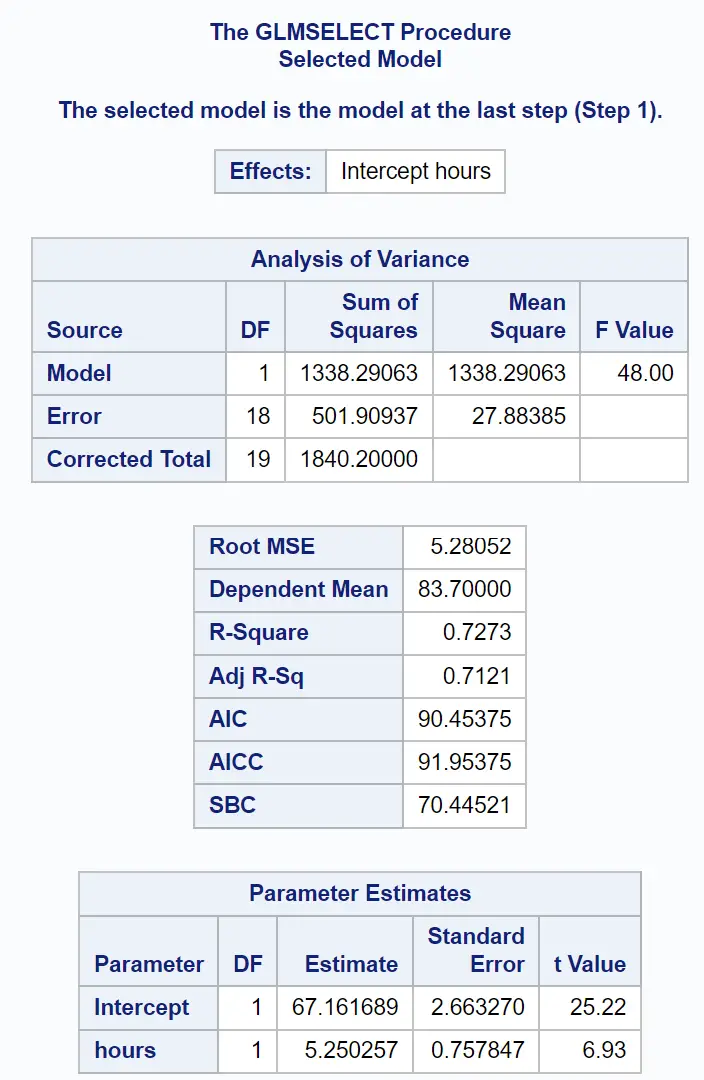
Ми можемо використовувати значення в таблиці оцінок параметрів , щоб написати підібрану регресійну модель:
Оцінка за іспит = 67,161689 + 5,250257 (вивчені години)
Ми також можемо бачити різні показники, які показують, наскільки добре ця модель відповідає даним:
Значення R-квадрат показує нам відсоток варіації оцінок іспитів, який можна пояснити кількістю вивчених годин і кількістю складених підготовчих іспитів.
У цьому випадку 72,73% варіації екзаменаційних балів можна пояснити кількістю вивчених годин і кількістю складених підготовчих іспитів.
Значення Root MSE також корисно знати. Це являє собою середню відстань між спостережуваними значеннями та лінією регресії.
У цій моделі регресії спостережувані значення відхиляються в середньому на 5,28052 одиниці від лінії регресії.
Примітка : зверніться до документації SAS , щоб отримати повний список потенційних аргументів, які можна використовувати з PROC GLMSELECT .
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в SAS:
Як виконати просту лінійну регресію в SAS
Як виконати множинну лінійну регресію в SAS
Як виконати поліноміальну регресію в SAS
Як виконати логістичну регресію в SAS
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше