Як видалити рядки з відсутніми значеннями в sas
Ви можете використовувати такий базовий синтаксис, щоб видалити рядки з відсутніми значеннями з набору даних у SAS:
data new_data;
set my_data;
if cmiss(of _all_) then delete;
run ;
У цьому прикладі створюється новий набір даних під назвою new_data , у якому видалено всі рядки з відсутніми значеннями у вихідному наборі даних під назвою my_data .
У наступному прикладі показано, як використовувати цей синтаксис на практиці.
Приклад: видаліть рядки з відсутніми значеннями в SAS
Припустімо, що в SAS є такий набір даних, який містить інформацію про різні баскетбольні команди:
/*create dataset*/
data my_data;
input team $points assists;
datalines ;
Mavs 113 22
Pacers 95.
Cavs. .
Lakers 114 20
Heat 123 39
Kings. 22
Raptors 105 11
Hawks 95 25
Magic 103 26
Spurs 119.
;
run ;
/*view dataset*/
proc print data =my_data;

Зауважте, що є кілька рядків із відсутніми значеннями.
Ми можемо використати наступний код, щоб створити новий набір даних, у якому ми видаляємо всі рядки з існуючого набору даних, які мають відсутні значення в стовпці:
/*create new dataset that removes rows with missing values from existing dataset*/
data new_data;
set my_data;
if cmiss(of _all_) then delete;
run ;
/*view new dataset*/
proc print data =new_data;
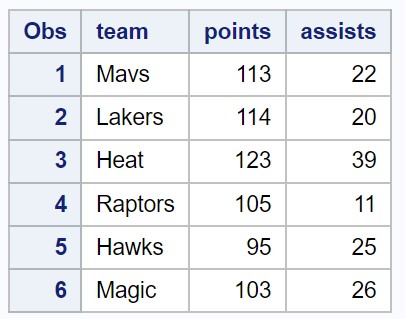
Ми бачимо, що всі рядки з відсутніми значеннями були видалені з набору даних.
Примітка №1 : аргумент _all_ у функції CMISS визначає, що SAS має шукати відсутні значення в усіх стовпцях кожного рядка.
Примітка №2 : ви можете знайти повну документацію функції CMISS тут .
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в SAS:
Як видалити дублікати в SAS
Як підрахувати відсутні значення в SAS
Як замінити пропущені значення на нуль в SAS
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше