Як виконати багатовимірне масштабування в r (з прикладом)
У статистиці багатовимірне масштабування — це спосіб візуалізації подібності спостережень у наборі даних у абстрактному декартовому просторі (зазвичай 2D).
Найпростіший спосіб виконати багатовимірне масштабування в R — це використати вбудовану функцію cmdscale() , яка використовує такий базовий синтаксис:
cmdscale(d, eig = FALSE, k = 2, …)
золото:
- d : матриця відстані, яка зазвичай обчислюється функцією dist() .
- eig : повертати чи ні власні значення.
- k : кількість вимірів для перегляду даних. Типовим є 2 .
У наступному прикладі показано, як використовувати цю функцію на практиці.
Приклад: багатовимірне масштабування в R
Припустимо, у R є наступний кадр даних, який містить інформацію про різних баскетболістів:
#create data frame df <- data. frame (points=c(4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28), assists=c(3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11), blocks=c(7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1), rebounds=c(4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2)) #add row names row. names (df) <- LETTERS[1:11] #view data frame df points assists blocks rebounds A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Ми можемо використовувати наступний код для виконання багатовимірного масштабування за допомогою функції cmdscale() і візуалізації результатів у 2D-просторі:
#calculate distance matrix
d <- dist(df)
#perform multidimensional scaling
fit <- cmdscale(d, eig= TRUE , k= 2 )
#extract (x, y) coordinates of multidimensional scaling
x <- fit$points[,1]
y <- fit$points[,2]
#create scatterplot
plot(x, y, xlab=" Coordinate 1 ", ylab=" Coordinate 2 ",
main=" Multidimensional Scaling Results ", type=" n ")
#add row names of data frame as labels
text(x, y, labels=row. names (df))
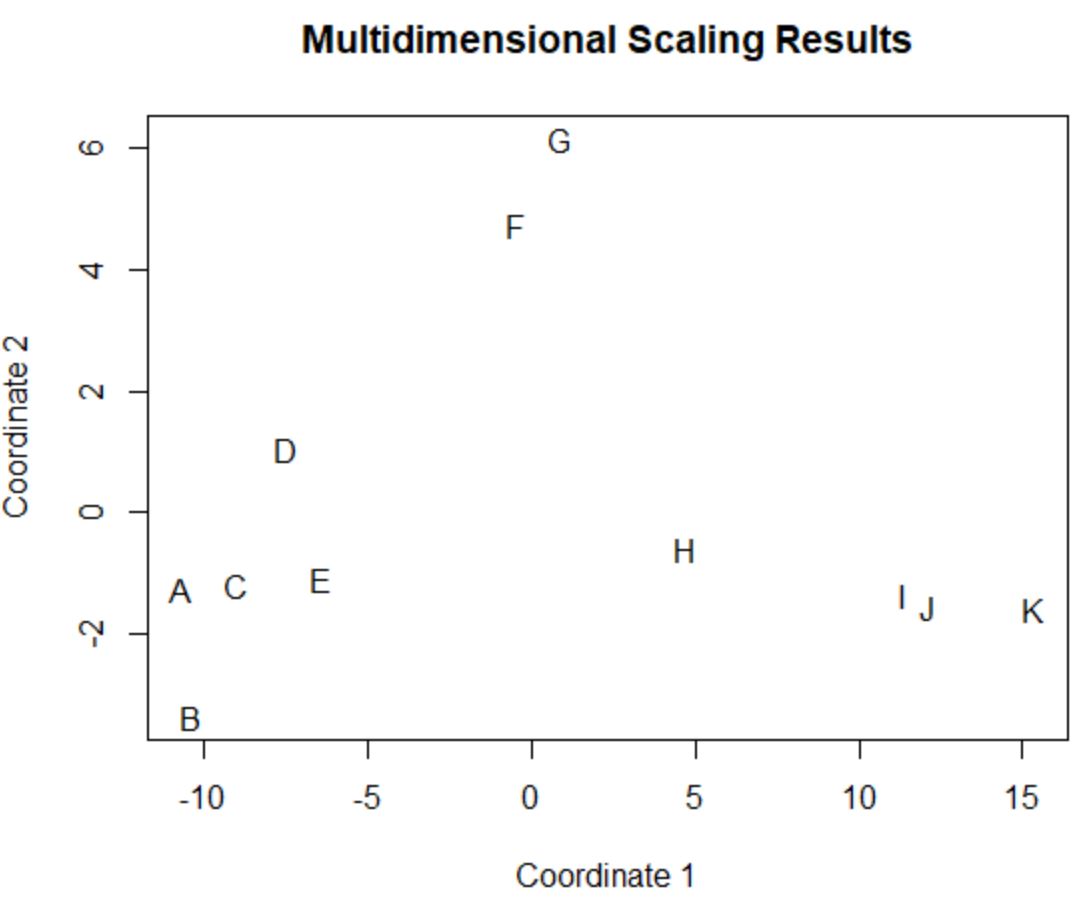
Гравці в оригінальному кадрі даних, які мають схожі значення в оригінальних чотирьох стовпцях (очки, передачі, блоки та підбирання), розташовані близько один до одного на сюжеті.
Наприклад, гравці А і С закриті один до одного. Ось їх значення з вихідного кадру даних:
#view data frame values for players A and C df[rownames(df) %in% c(' A ', ' C '), ] points assists blocks rebounds A 4 3 7 4 C 6 2 6 5
Їх значення для очок, передач, блоків і підбирань дуже схожі, що пояснює, чому вони так близькі один до одного на двовимірному графіку.
На противагу цьому розглянемо гравців B і K , які знаходяться далеко один від одного в сюжеті.
Якщо ми звернемося до їхніх значень у вихідних даних, то побачимо, що вони досить різні:
#view data frame values for players B and K df[rownames(df) %in% c(' B ', ' K '), ] points assists blocks rebounds B 4 2 3 5 K 28 11 1 2
Таким чином, двовимірний графік є хорошим способом візуалізації того, наскільки схожий кожен гравець за всіма змінними у кадрі даних.
Гравці зі схожою статистикою згруповані близько один до одного, тоді як гравці з дуже різною статистикою розташовані далі один від одного в сюжеті.
Зауважте, що ви також можете отримати точні координати (x, y) кожного гравця на графіку, ввівши fit , що є назвою змінної, у якій ми зберігаємо результати функції cmdscale() :
#view (x, y) coordinates of points in the plot
fit
[,1] [,2]
A -10.6617577 -1.2511291
B -10.3858237 -3.3450473
C -9.0330408 -1.1968116
D -7.4905743 1.0578445
E -6.4021114 -1.0743669
F -0.4618426 4.7392534
G 0.8850934 6.1460850
H 4.7352436 -0.6004609
I 11.3793381 -1.3563398
J 12.0844168 -1.5494108
K 15.3510585 -1.5696166
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в R:
Як нормалізувати дані в R
Як до центру обробки даних у R
Як видалити викиди в R
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше