Вибірковий розподіл різниці в пропорціях
У цій статті пояснюється, у чому полягає різниця в пропорційному розподілі вибірки та для чого вона використовується в статистиці. Також подано формулу розподілу вибірки різниці в пропорціях та покрокову розв’язану вправу.
Який вибірковий розподіл різниці в пропорціях?
Розподіл вибірки за різницею пропорцій — це розподіл, який є результатом обчислення відмінностей між пропорціями вибірки всіх можливих вибірок із двох різних сукупностей.
Тобто процес отримання вибіркового розподілу різниці в пропорціях полягає, по-перше, у виділенні всіх можливих вибірок із двох різних генеральних сукупностей, по-друге, у визначенні частки кожної вилученої вибірки та, нарешті, у визначенні різниці між усіма пропорції різниця пропорцій. дві популяції. Таким чином, сукупність результатів, отриманих після виконання цих операцій, формує вибірковий розподіл різниці в пропорціях.

У статистиці різниця в розподілі вибірки пропорцій використовується для обчислення ймовірності того, що різниця між пропорціями вибірки двох випадково відібраних вибірок близька до різниці в пропорціях сукупності.
Формула для вибіркового розподілу різниці пропорцій
Вибірки, відібрані для різниці в розподілі вибірки пропорцій, визначаються біноміальними розподілами , оскільки для практичних цілей пропорція є відношенням успішних випадків до загальної кількості спостережень.
Тим не менш, завдяки центральній граничній теоремі біноміальні розподіли можна наблизити до нормальних розподілів ймовірностей . Таким чином, вибірковий розподіл різниці в пропорціях можна наблизити до нормального розподілу з такими характеристиками:
![\begin{array}{c}\displaystyle\mu_{\widehat{p_1}-\widehat{p_2}}=p_1-p_2 \qquad \sigma_{\widehat{p_1}-\widehat{p_2}}=\sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\\[6ex]\displaystyle N_{p}\left(p_1-p_2, \sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-a1ce359b5dd6d80f8d27b0b9a1034bed_l3.png "Rendered by QuickLaTeX.com")
Примітка. Вибірковий розподіл різниці в пропорціях можна наблизити до нормального розподілу, лише якщо

,

,

,

,

І

.
Отже, оскільки вибірковий розподіл різниці в пропорціях можна наблизити до нормального розподілу, формула для розрахунку статистики вибіркового розподілу різниці в пропорціях виглядає наступним чином:

золото:
-

є пропорцією зразка i.
-

це частка населення i.
-

ймовірність відмови популяції i,

.
-

це розмір вибірки i.
-

є змінною, визначеною стандартним нормальним розподілом N(0,1).
Ця формула подібна до формули перевірки гіпотез для різниці в пропорціях.
Конкретний приклад вибіркового розподілу різниці пропорцій
Ознайомившись із визначенням різниці пропорцій вибіркового розподілу та його формулою, ви можете переглянути нижче розв’язаний приклад крок за кроком, щоб остаточно зрозуміти концепцію.
- Ви хочете проаналізувати точність двох виробничих установок, одна фабрика виробляє таким чином, що лише 5% вироблених деталей мають дефекти, тоді як відсоток дефектних деталей іншої фабрики становить 8%. Якщо ми візьмемо зразок з 200 деталей з першої фабрики та ще один зразок з 280 деталей з другої фабрики, яка ймовірність того, що відсоток дефектів на першому заводі буде більшим, ніж відсоток дефектів на другому заводі? виробництво?
Щоб остаточно дізнатися всі дані задачі, ми спочатку обчислимо частку добре вироблених частин кожної рослини:
![\begin{array}{c}q_1=1-p_1=1-0,05=0,95\\[2ex]q_2=1-p_2=1-0,08=0,92\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-7c02732cc5fb319bfa5bf7b8ed8d03db_l3.png "Rendered by QuickLaTeX.com")
Якщо рівень браку на першій фабриці був більшим, ніж рівень браку на другій фабриці, це означає, що наступне рівняння буде вірним:
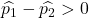

Таким чином, ймовірність того, що рівень дефектів першої фабрики більший, ніж рівень дефектів другої фабрики, еквівалентна ймовірності того, що змінна Z перевищує 1,34:
![P[(\widehat{p_1}-\widehat{p_2})>0]=P[Z>1,34]” title=”Rendered by QuickLaTeX.com” height=”19″ width=”242″ style=”vertical-align: -5px;”></p>
</p>
<p> Нарешті, нам просто потрібно знайти відповідну ймовірність у <a href=](https://statorials.org/wp-content/ql-cache/quicklatex.com-41dd897cdff473ff488cde0e3cc140b0_l3.png) таблиці нормального розподілу , і ми вже розв’яжемо задачу:
таблиці нормального розподілу , і ми вже розв’яжемо задачу:
![P[(\widehat{p_1}-\widehat{p_2})>0]=P[Z>1,34]=0,0901″ title=”Rendered by QuickLaTeX.com” height=”19″ width=”319″ style=”vertical-align: -5px;”></p>
</p>
<p> Коротше кажучи, ймовірність того, що частка дефектів на першій фабриці більша, ніж частка дефектів на другій фабриці, становить 9,01%. </p>
<div style=](https://statorials.org/wp-content/ql-cache/quicklatex.com-8d6e503a2089d30be8fd68bbc722bb44_l3.png)
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше