Як виконати внутрішнє об’єднання в sas (з прикладом)
Щоб виконати внутрішнє об’єднання з двома наборами даних у SAS, можна використати такий базовий синтаксис:
proc sql ;
create table final_table as
select * from data1 as x join data2 as y
on x.ID = y.ID;
quit ;
У наступному прикладі показано, як використовувати цей синтаксис на практиці.
Пов’язане: Як зробити об’єднання зліва в SAS
Приклад: внутрішнє об’єднання в SAS
Припустімо, що в SAS є такі два набори даних:
/*create datasets*/
data data1;
input team $points;
datalines ;
Mavs 99
Spurs 93
Rockets 88
Thunder 91
Warriors 104
Cavs 93
Nets 90
Hawks 91
;
run ;
data data2;
input team $rebounds;
datalines ;
Mavs 21
Spurs 18
Warriors 27
Hawks 29
Knicks 40
Raptors 30
;
run ;
/*view datasets*/
proc print data =data1;
proc print data =data2;

Зауважте, що обидва набори даних мають спільну змінну: team .
Ми використаємо такий синтаксис, щоб виконати внутрішнє об’єднання та створити новий набір даних, що містить лише ті рядки, де в обох наборах даних з’являється змінна team :
/*perform inner join*/
proc sql ;
create table final_table as
select * from data1 as x join data2 as y
on x.team = y.team;
quit ;
/*view results of inner join*/
proc print data =final_table;
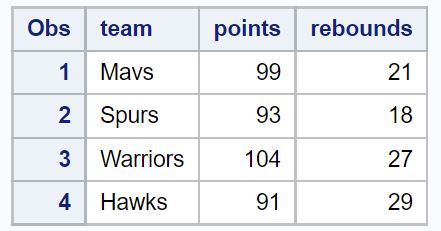
Отриманий набір даних містить лише ті рядки, у яких змінна команди відображається в обох наборах даних.
Якщо ви звернетесь до попередніх двох наборів даних, ви помітите, що в обох наборах даних є лише чотири команди: Mavs, Spurs, Warriors і Hawks.
Оскільки ми вирішили об’єднати два набори даних у змінній team , ці чотири команди також відображаються в остаточному наборі даних.
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в SAS:
Як нормалізувати дані в SAS
Як замінити символи в рядку в SAS
Як замінити пропущені значення на нуль в SAS
Як видалити дублікати в SAS
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше