Що таке відкритий розподіл?
У статистиці відкритий розподіл — це частотний розподіл, у якому відкритий один або кілька класів (або «бінів»).
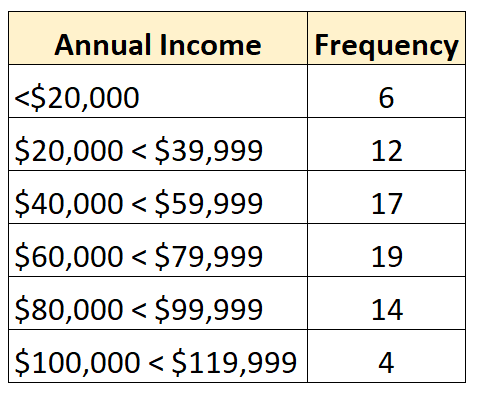
Наприклад, наступний розподіл частот представляє відкритий розподіл, у якому відкритий найменший клас:
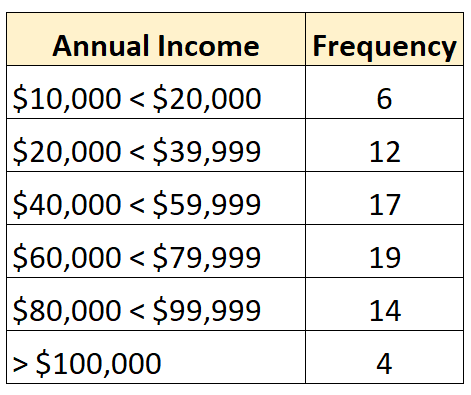
А наступний розподіл частот показує відкритий розподіл, у якому відкритий найбільший клас:
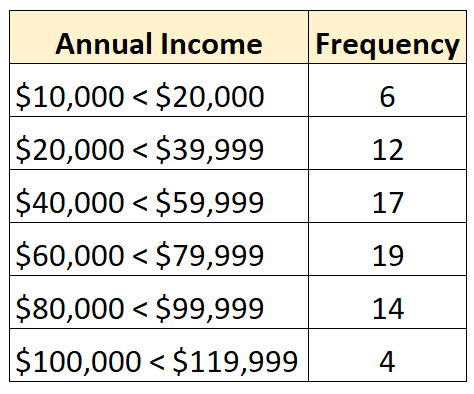
І навпаки, закритий розподіл – це такий, у якому кожен клас частотного розподілу має верхню та нижню межі, як-от:
Що викликає відкриті розподіли?
Відкриті розподіли часто є результатом того, що дослідники вирішують збирати дані таким чином, що один із класів виявляється відкритим.
Наприклад, припустимо, що дослідник опитує жителів певного міста та запитує їх про річний дохід домогосподарства.
Дослідник може дати найширшу можливу відповідь «>100 000 доларів», оскільки він знає, що жителям із високим рівнем доходу може бути незручно ділитися сумою, яку вони заробляють, якщо вона значно перевищує 100 000 доларів.
І навпаки, дослідник може вирішити дати найкоротшу відповідь, тому що він або вона знає, що мешканцям, які заробляють дуже мало, також буде незручно ділитися тим невеликим, що вони заробляють.
Коротше кажучи, дослідники часто включають відкриті курси у свої опитування, оскільки хочуть максимізувати кількість людей, яким буде комфортно відповідати на запитання опитування.
Проблема з відкритими дистрибутивами
Проблема з відкритими дистрибутивами полягає в тому, що реальні дані піддаються цензурі . Іншими словами, ми можемо знати кількість людей, які заробляють понад 100 000 доларів США в певному місті, але насправді ми не знаємо їхніх точних річних доходів.
Цілком можливо, що деякі люди заробляють $150 000, $250 000, $500 000 або навіть більше, але ми не маємо уявлення, оскільки кожен із цих людей не може вказати, що вони заробляють «>$100 000» у «розслідуванні».
Оскільки дані піддаються цензурі у відкритих розподілах, ми також не можемо обчислити точне середнє значення та стандартне відхилення значень у наборі даних, оскільки ми не маємо доступу до всіх значень у необроблених даних.
Як аналізувати відкритий розподіл
Оскільки ми не можемо обчислити точне середнє значення відкритого розподілу, ми часто використовуємо медіану як міру «центру» набору даних.
Пам’ятайте, що медіана представляє середнє значення набору даних.
Працюючи з відкритими розподілами, ми можемо використовувати таку формулу, щоб знайти найкращу оцінку медіани:
Найкраща оцінка медіани: L + ((n/2 – F) / f) * w
золото:
- Л: Нижня межа середньої групи
- n: Загальна кількість спостережень
- F: Кумулятивна частота до середньої групи
- f: Частота середньої групи
- w: Ширина середньої групи
Наприклад, припустимо, що ми маємо такий відкритий розподіл:
Всього в наборі даних 72 значення. Отже, ми знаємо, що середнє значення буде між 36-м і 37-м найбільшими значеннями в наборі даних. Кожне з цих значень належить до класу «$60 000 – $79 999», тому ми знаємо, що середній дохід знаходиться в цьому діапазоні.
Наша найкраща оцінка медіани буде:
Медіана: 60 000 + ((72/2 – 25) / 19) * 19 999 = 71 578 доларів США
Це значення представляє нашу найкращу оцінку середнього річного доходу осіб у цьому наборі даних.
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше