Як виконати однооперативне кодування в python
Одночасне кодування використовується для перетворення категоріальних змінних у формат, який легко використовуватиметься алгоритмами машинного навчання .
Основна ідея одноразового кодування полягає у створенні нових змінних, які приймають значення 0 і 1 для представлення вихідних категоріальних значень.
Наприклад, на наведеному нижче зображенні показано, як ми будемо кодувати за допомогою одного кроку, щоб перетворити категоріальну змінну, що містить імена команд, на нові змінні, які містять лише значення 0 і 1:
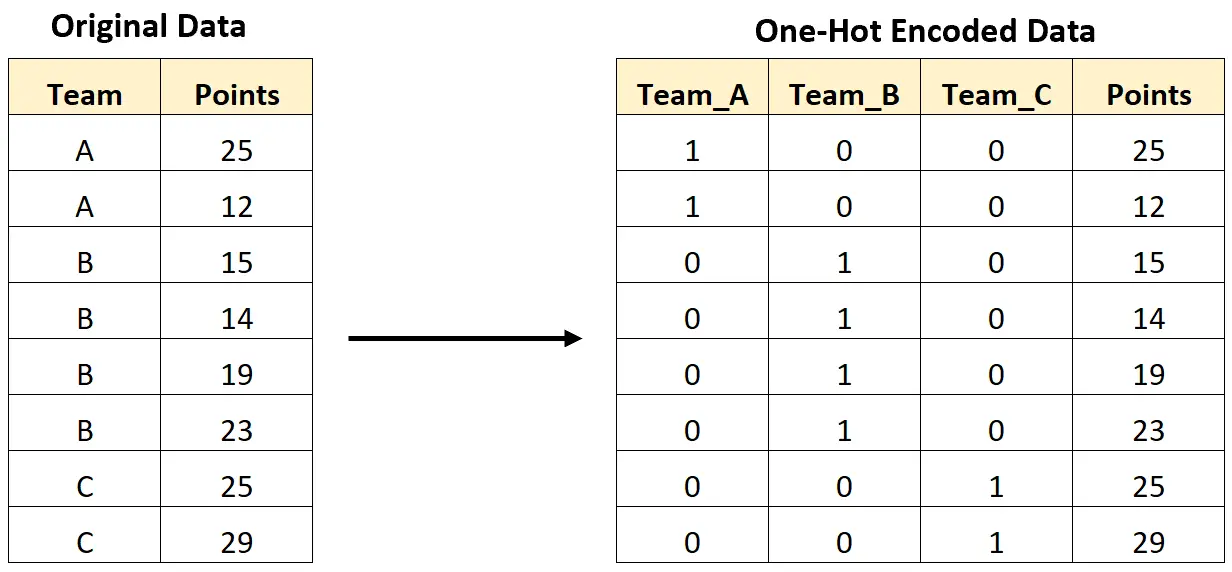
Наступний покроковий приклад показує, як виконати швидке кодування для цього точного набору даних у Python.
Крок 1: Створіть дані
Спочатку давайте створимо наступні pandas DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'], ' points ': [25, 12, 15, 14, 19, 23, 25, 29]}) #view DataFrame print (df) team points 0 to 25 1 to 12 2 B 15 3 B 14 4 B 19 5 B 23 6 C 25 7 C 29
Крок 2. Виконайте одноразове кодування
Далі давайте імпортуємо функцію OneHotEncoder() із бібліотеки sklearn і використаємо її для виконання гарячого кодування змінної ‘team’ у pandas DataFrame:
from sklearn. preprocessing import OneHotEncoder #creating instance of one-hot-encoder encoder = OneHotEncoder(handle_unknown=' ignore ') #perform one-hot encoding on 'team' column encoder_df = pd. DataFrame ( encoder.fit_transform (df[[' team ']]). toarray ()) #merge one-hot encoded columns back with original DataFrame final_df = df. join (encoder_df) #view final df print (final_df) team points 0 1 2 0 to 25 1.0 0.0 0.0 1 to 12 1.0 0.0 0.0 2 B 15 0.0 1.0 0.0 3 B 14 0.0 1.0 0.0 4 B 19 0.0 1.0 0.0 5 B 23 0.0 1.0 0.0 6 C 25 0.0 0.0 1.0 7 C 29 0.0 0.0 1.0
Зауважте, що до DataFrame було додано три нові стовпці, оскільки початковий стовпець «team» містив три унікальні значення.
Примітка . Ви можете знайти повну документацію для функції OneHotEncoder() тут .
Крок 3: видаліть вихідну категоріальну змінну
Нарешті, ми можемо видалити оригінальну змінну team з DataFrame, оскільки вона нам більше не потрібна:
#drop 'team' column final_df. drop (' team ', axis= 1 , inplace= True ) #view final df print (final_df) points 0 1 2 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
Пов’язане: Як видалити стовпці в Pandas (4 методи)
Ми також можемо перейменувати стовпці остаточного DataFrame, щоб полегшити їх читання:
#rename columns final_df. columns = ['points', 'teamA', 'teamB', 'teamC'] #view final df print (final_df) points teamA teamB teamC 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
Одночасне кодування завершено, і тепер ми можемо вставити цей pandas DataFrame у будь-який алгоритм машинного навчання, який забажаємо.
Додаткові ресурси
Як обчислити зрізане середнє в Python
Як виконати лінійну регресію в Python
Як виконати логістичну регресію в Python
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше