Як створити нормальний розподіл у r (з прикладами)
Ви можете швидко створити нормальний розподіл у R за допомогою функції rnorm() , яка використовує такий синтаксис:
rnorm(n, mean=0, sd=1)
золото:
- n: кількість спостережень.
- середнє: середнє значення нормального розподілу. Значення за замовчуванням 0.
- sd: стандартне відхилення нормального розподілу. Значення за умовчанням — 1.
У цьому підручнику показано приклад використання цієї функції для створення нормального розподілу в R.
Пов’язане: посібник із dnorm, pnorm, qnorm і rnorm у R
Приклад: створення нормального розподілу в R
Наступний код показує, як створити нормальний розподіл у R:
#make this example reproducible set.seed(1) #generate sample of 200 obs. that follows normal dist. with mean=10 and sd=3 data <- rnorm(200, mean=10, sd=3) #view first 6 observations in sample head(data) [1] 8.120639 10.550930 7.493114 14.785842 10.988523 7.538595
Ми можемо швидко знайти середнє значення та стандартне відхилення цього розподілу:
#find mean of sample
mean(data)
[1] 10.10662
#find standard deviation of sample
sd(data)
[1] 2.787292
Ми також можемо створити швидку гістограму для візуалізації розподілу значень даних:
hist(data, col=' steelblue ')
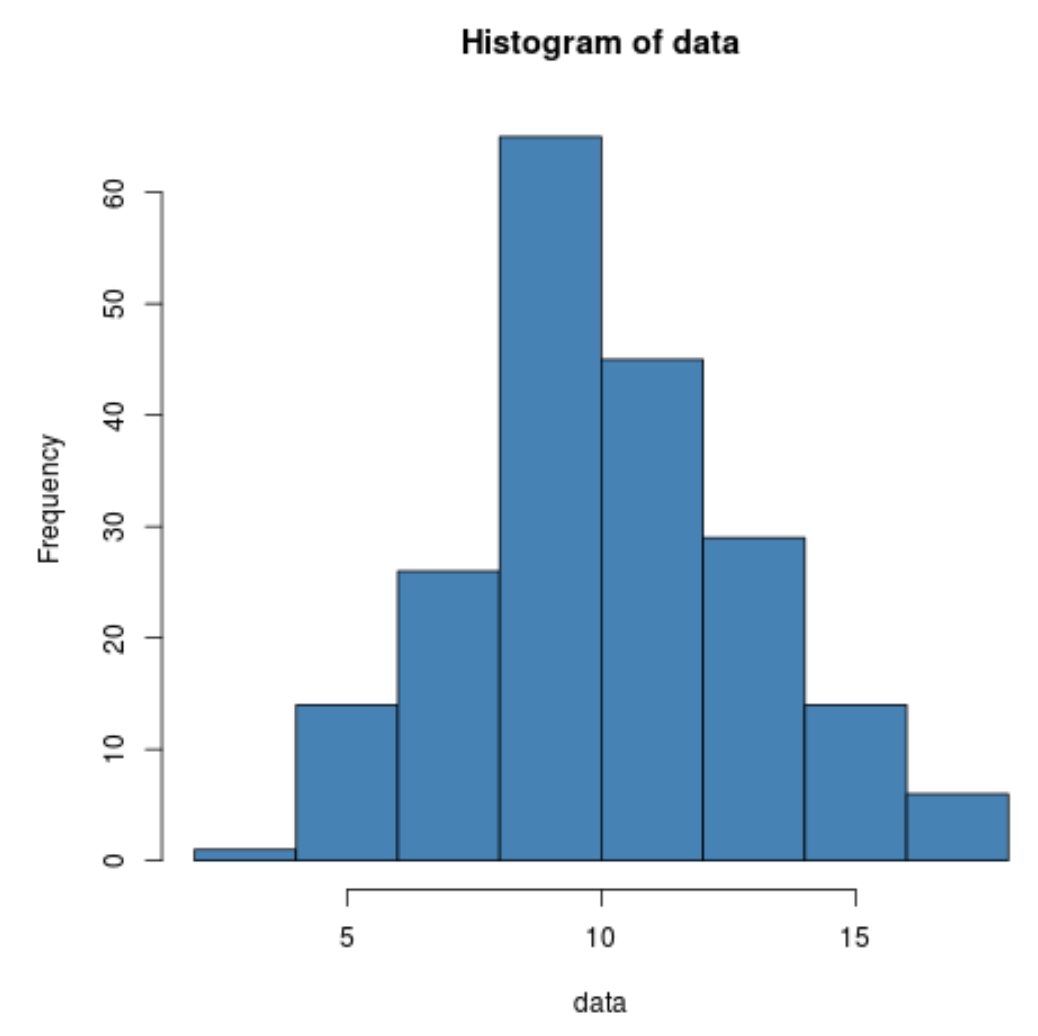
Ми навіть можемо виконати тест Шапіро-Вілка, щоб перевірити, чи походить набір даних із нормальної популяції:
shapiro.test(data)
Shapiro-Wilk normality test
data:data
W = 0.99274, p-value = 0.4272
P-значення тесту виявляється рівним 0,4272 . Оскільки це значення не менше 0,05, ми можемо припустити, що дані вибірки надходять із нормально розподіленої сукупності.
Цей результат не повинен дивувати, оскільки ми генерували дані за допомогою функції rnorm() , яка природним чином генерує випадкову вибірку даних зі звичайного розподілу.
Додаткові ресурси
Як побудувати графік нормального розподілу в R
Посібник із dnorm, pnorm, qnorm і rnorm у R
Як виконати тест Шапіро-Вілка на нормальність у R
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше