Як виконати двовимірний аналіз у r (з прикладами)
Термін двовимірний аналіз стосується аналізу двох змінних. Ви можете запам’ятати це, тому що префікс “бі” означає “два”.
Метою двофакторного аналізу є розуміння зв’язку між двома змінними
Існує три поширених способи виконання двовимірного аналізу:
1. Хмари точок
2. Коефіцієнти кореляції
3. Проста лінійна регресія
У наведеному нижче прикладі показано, як виконати кожен із цих типів двовимірного аналізу, використовуючи такий набір даних, який містить інформацію про дві змінні: (1) години, витрачені на навчання, і (2) результати тестів, отримані 20 різними студентами:
#create data frame df <- data. frame (hours=c(1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 5, 5, 6, 6, 6, 7, 8), score=c(75, 66, 68, 74, 78, 72, 85, 82, 90, 82, 80, 88, 85, 90, 92, 94, 94, 88, 91, 96)) #view first six rows of data frame head(df) hours score 1 1 75 2 1 66 3 1 68 4 2 74 5 2 78 6 2 72
1. Хмари точок
Ми можемо використати наступний синтаксис, щоб створити діаграму розсіювання вивчених годин і оцінок іспиту в R:
#create scatterplot of hours studied vs. exam score plot(df$hours, df$score, pch= 16 , col=' steelblue ', main=' Hours Studied vs. Exam Score ', xlab=' Hours Studied ', ylab=' Exam Score ')
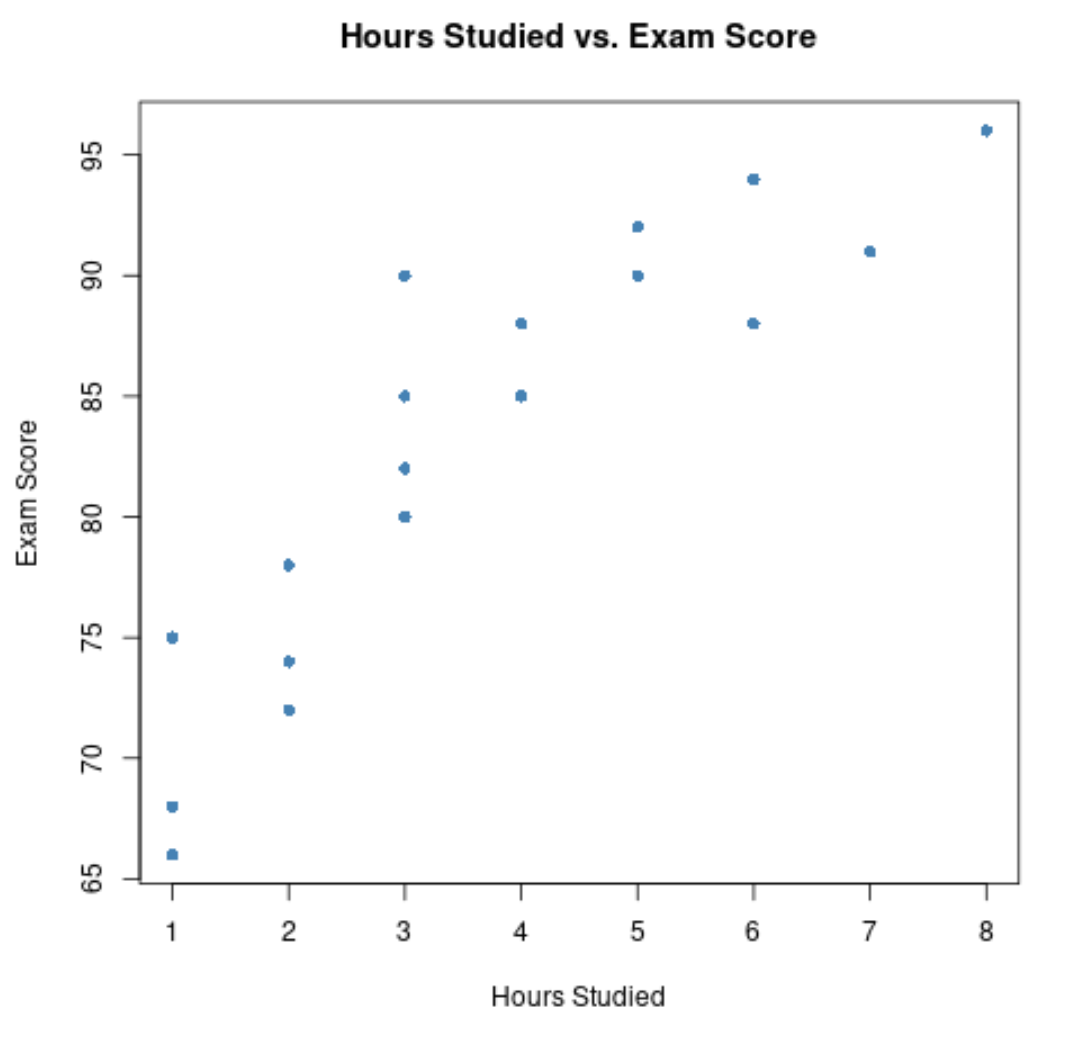
На осі абсцис відкладено кількість годин, а на осі у – оцінка, отримана на іспиті.
На графіку видно, що існує позитивний зв’язок між двома змінними: зі збільшенням кількості годин навчання результати іспитів також мають тенденцію до зростання.
2. Коефіцієнти кореляції
Коефіцієнт кореляції Пірсона — це спосіб кількісного визначення лінійного зв’язку між двома змінними.
Ми можемо використовувати функцію cor() у R, щоб обчислити коефіцієнт кореляції Пірсона між двома змінними:
#calculate correlation between hours studied and exam score received
cor(df$hours, df$score)
[1] 0.891306
Коефіцієнт кореляції виявляється рівним 0,891 .
Це значення близьке до 1, що вказує на сильну позитивну кореляцію між вивченими годинами та оцінкою іспиту.
3. Проста лінійна регресія
Проста лінійна регресія — це статистичний метод, який ми можемо використати, щоб знайти рівняння лінії, яка найкраще «відповідає» набору даних, за допомогою якого ми потім можемо зрозуміти точний зв’язок між двома змінними.
Ми можемо використати функцію lm() у R, щоб підібрати просту модель лінійної регресії для вивчених годин і отриманих результатів іспитів:
#fit simple linear regression model fit <- lm(score ~ hours, data=df) #view summary of model summary(fit) Call: lm(formula = score ~ hours, data = df) Residuals: Min 1Q Median 3Q Max -6,920 -3,927 1,309 1,903 9,385 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 69.0734 1.9651 35.15 < 2nd-16 *** hours 3.8471 0.4613 8.34 1.35e-07 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 4.171 on 18 degrees of freedom Multiple R-squared: 0.7944, Adjusted R-squared: 0.783 F-statistic: 69.56 on 1 and 18 DF, p-value: 1.347e-07
Підігнане рівняння регресії виявляється таким:
Оцінка за іспит = 69,0734 + 3,8471*(вивчені години)
Це говорить нам про те, що кожна додаткова вивчена година пов’язана із середнім збільшенням оцінки за іспит на 3,8471 .
Ми також можемо використати підігнане рівняння регресії, щоб передбачити бал, який отримає студент на основі загальної кількості вивчених годин.
Наприклад, студент, який навчається 3 години, повинен отримати 81,6147 :
- Оцінка за іспит = 69,0734 + 3,8471*(вивчені години)
- Оцінка за іспит = 69,0734 + 3,8471*(3)
- Результат іспиту = 81,6147
Додаткові ресурси
У наступних посібниках надається додаткова інформація про двовимірний аналіз:
Вступ до двовимірного аналізу
5 прикладів двовимірних даних у реальному житті
Вступ до простої лінійної регресії
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше