Дерево рішень проти випадкових лісів: у чому різниця?
Дерево рішень — це тип моделі машинного навчання, який використовується, коли зв’язок між набором змінних предикторів і змінною відповіді є нелінійним.
Основна ідея дерева рішень полягає в тому, щоб побудувати «дерево» за допомогою набору змінних-прогнозів, яке передбачає значення змінної відповіді за допомогою правил прийняття рішень.
Наприклад, ми могли б використати змінні прогнозу «зіграні роки» та «середня кількість хоум-ранів», щоб передбачити річну зарплату професійних бейсболістів.
Використовуючи цей набір даних, ось як може виглядати модель дерева рішень:
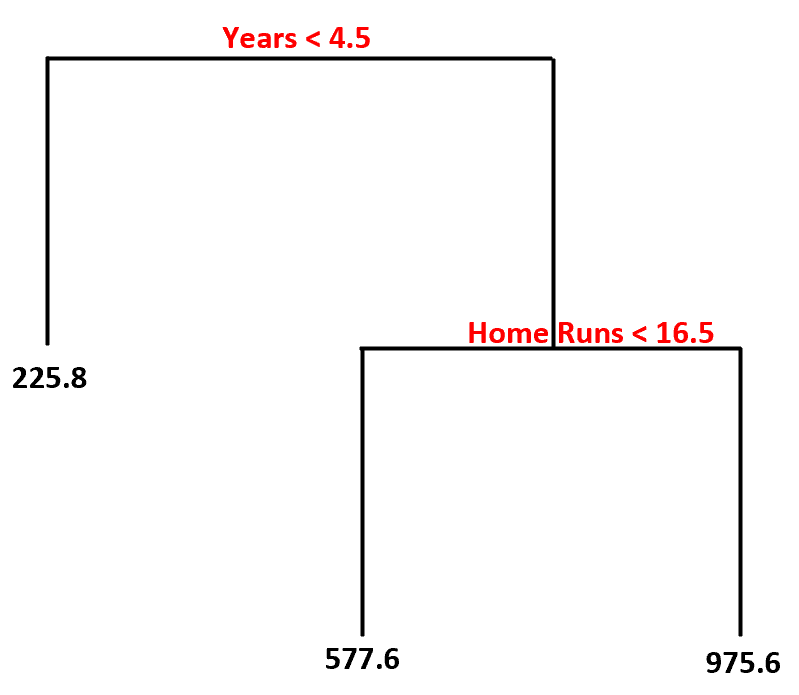
Ось як ми будемо інтерпретувати це дерево рішень:
- Гравці, які грали менше 4,5 років, мають прогнозовану зарплату в розмірі $225,8 тис .
- Гравці, які грали більше 4,5 років або більше і менше 16,5 хоум-ранів у середньому, мають прогнозовану зарплату $577,6K .
- Гравці з 4,5 роками або більше стажу і в середньому 16,5 або більше хоум-ранів мають очікувану зарплату в розмірі $975,6K .
Основна перевага дерева рішень полягає в тому, що його можна швидко адаптувати до набору даних, а остаточну модель можна чітко візуалізувати та інтерпретувати за допомогою діаграми «дерева», подібної до наведеної вище.
Основний недолік полягає в тому, що дерево рішень має тенденцію переповнювати навчальний набір даних, тобто воно, ймовірно, буде погано працювати з невидимими даними. На це також можуть сильно вплинути викиди в наборі даних.
Розширенням дерева рішень є модель, відома як випадковий ліс , яка, по суті, є набором дерев рішень.
Ось кроки, які ми використовуємо для створення моделі випадкового лісу:
1. Візьміть початкові зразки з вихідного набору даних.
2. Для кожного початкового зразка створіть дерево рішень, використовуючи випадкову підмножину змінних предиктора.
3. Усередніть прогнози з кожного дерева, щоб отримати остаточну модель.
Перевага випадкових лісів полягає в тому, що вони, як правило, працюють набагато краще, ніж дерева рішень на невидимих даних, і менш схильні до викидів.
Недоліком випадкових лісів є те, що немає можливості візуалізувати остаточну модель, і їх створення може зайняти багато часу, якщо у вас недостатньо обчислювальної потужності або набір даних, з яким ви працюєте, є надзвичайно об’ємним.
Переваги та недоліки: дерева рішень проти. Випадкові ліси
У наведеній нижче таблиці підсумовано переваги та недоліки дерев рішень порівняно з випадковими лісами:
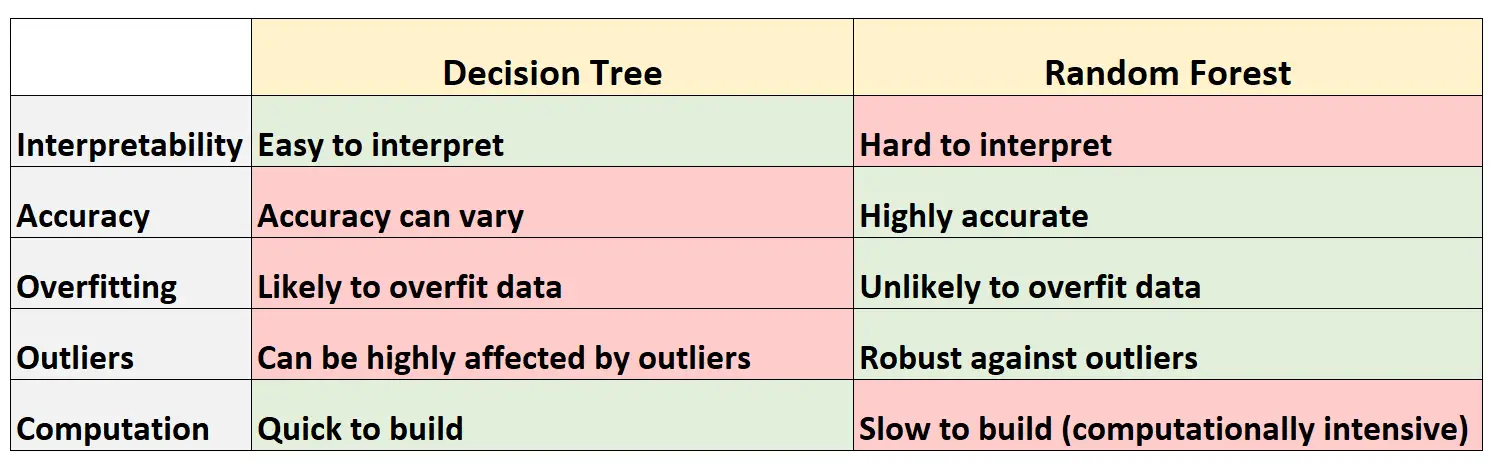
Ось коротке пояснення кожного рядка в таблиці:
1. Інтерпретованість
Дерева рішень легко інтерпретувати, оскільки ми можемо створити діаграму дерева, щоб візуалізувати та зрозуміти остаточну модель.
І навпаки, ми не можемо візуалізувати випадковий ліс, і часто буває важко зрозуміти, як остаточна модель випадкового лісу приймає рішення.
2. Точність
Оскільки дерева рішень, ймовірно, переповнять навчальний набір даних, вони, як правило, гірше працюють на невидимих наборах даних.
Навпаки, випадкові ліси мають тенденцію бути дуже точними на невидимих наборах даних, оскільки вони уникають переобладнання навчальних наборів даних.
3. Переобладнання
Як згадувалося раніше, дерева рішень часто переповнюють навчальні дані: це означає, що вони, швидше за все, адаптуються до «шуму» набору даних, на відміну від справжньої базової моделі.
І навпаки, оскільки випадкові ліси використовують лише певні змінні предикторів для побудови кожного окремого дерева рішень, остаточні дерева мають тенденцію бути прикрашеними, що означає, що моделі випадкових лісів навряд чи переповнять набори даних.
4. Викиди
Дерева рішень дуже чутливі до впливу викидів.
І навпаки, оскільки модель випадкового лісу будує багато окремих дерев рішень, а потім бере середнє значення прогнозів із цих дерев, на неї набагато менше шансів впливати викиди.
5. Розрахунок
Дерева рішень можна швидко адаптувати до наборів даних.
Навпаки, випадкові ліси потребують набагато більше обчислень, і їх створення може зайняти багато часу залежно від розміру набору даних.
Коли використовувати дерева рішень чи випадкові ліси
Загалом:
Вам слід використовувати дерево рішень , якщо ви хочете швидко створити нелінійну модель і мати можливість легко інтерпретувати, як модель приймає рішення.
Однак вам слід використовувати випадковий ліс, якщо ви маєте велику обчислювальну потужність і хочете створити модель, яка, імовірно, буде дуже точною, не турбуючись про те, як інтерпретувати модель.
У реальному світі інженери з машинного навчання та дослідники даних часто використовують випадкові ліси, оскільки вони дуже точні, а сучасні комп’ютери та системи часто можуть обробляти великі набори даних, які раніше не можна було обробляти.
Додаткові ресурси
Наступні навчальні посібники містять вступ до дерев рішень і моделей випадкового лісу:
У наступних посібниках пояснюється, як підігнати дерева рішень і випадкові ліси в R:
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше