Як розрахувати довірчі інтервали в sas
Довірчий інтервал – це діапазон значень, який, ймовірно, містить параметр сукупності з певним рівнем довіри.
У цьому посібнику пояснюється, як обчислити такі довірчі інтервали в R:
1. Довірчий інтервал для середнього сукупності
2. Довірчий інтервал для різниці середніх сукупностей
Ходімо!
Приклад 1: Довірчий інтервал для середнього значення сукупності в SAS
Припустимо, що ми маємо наступний набір даних, що містить висоту (в дюймах) випадкової вибірки з 12 рослин, які належать до одного виду:
/*create dataset*/ data my_data; inputHeight ; datalines ; 14 14 16 13 12 17 15 14 15 13 15 14 ; run ; /*view dataset*/ proc print data =my_data;
Припустімо, ми хочемо обчислити 95% рівень достовірності для справжнього середнього розміру популяції цього виду.
Для цього ми можемо використати такий код у SAS:
/*generate 95% confidence interval for population mean*/ proc ttest data =my_data alpha = 0.05 ; varHeight ; run ;
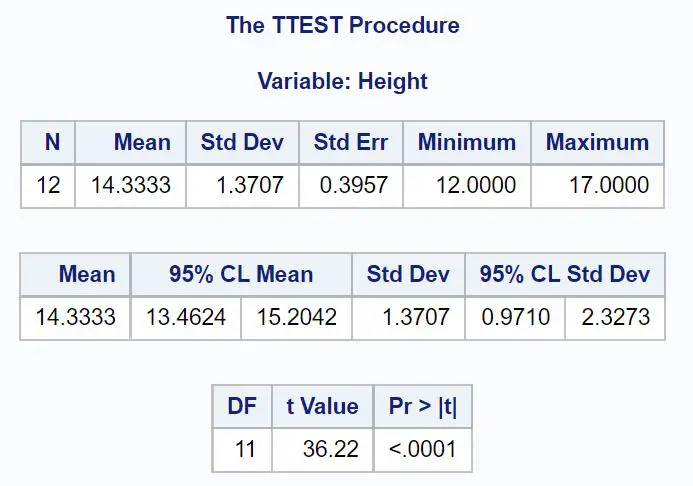
Значення Mean вказує на середнє значення вибірки, а значення менше 95% CL Mean показують 95% довірчий інтервал для середнього популяції.
З результатів ми бачимо, що 95% довірчий інтервал для середньої ваги рослини цієї популяції становить [13,4624 дюйма, 15,2042 дюйма] .
Приклад 2: Довірчий інтервал для різниці середніх показників сукупності в SAS
Припустимо, що ми маємо наступний набір даних, що містить висоту (в дюймах) випадкової вибірки рослин, що належать до двох різних видів:
/*create dataset*/
data my_data2;
input Species $Height;
datalines ;
At 14
At 14
At 16
At 13
AT 12
At 17
At 15
At 14
At 15
At 13
B15
B14
B 19
B 19
B17
B 18
B20
B 19
B17
B15
;
run ;
/*view dataset*/
proc print data =my_data2;
Припустімо, ми хочемо обчислити 95% рівень довіри для різниці в середньому розмірі популяції між видами A і B.
Для цього ми можемо використати такий код у SAS:
/*sort data by Species to ensure confidence interval is calculated correctly*/
proc sort data =my_data2;
by Species;
run ;
/*generate 95% confidence interval for difference in population means*/
proc ttest data =my_data2 alpha = 0.05 ;
class Species;
varHeight ;
run ;
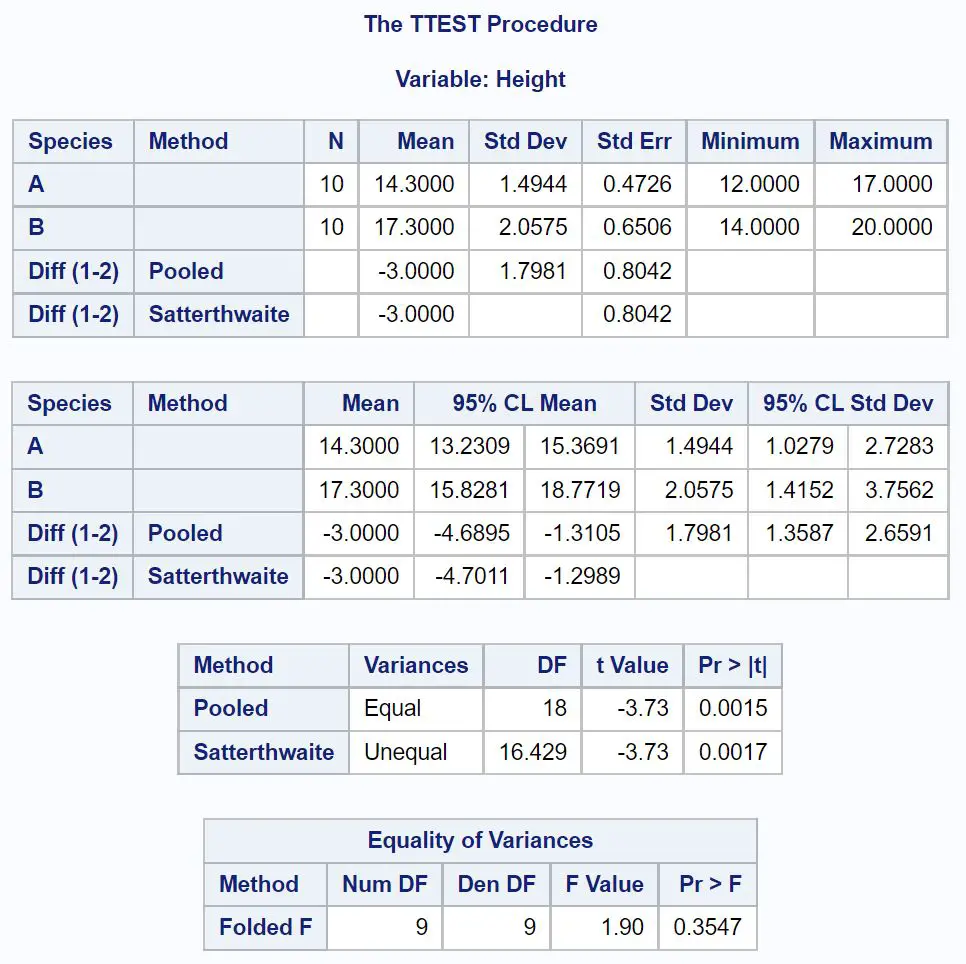
Перша таблиця, яку ми маємо розглянути в результаті, це рівність дисперсій , яка перевіряє, чи є дисперсія між кожною вибіркою рівною чи ні.
Оскільки р-значення не менше 0,05 у цій таблиці, ми можемо припустити, що відмінності між двома групами рівні.
Таким чином, ми можемо подивитися на лінію, яка використовує об’єднану дисперсію, щоб знайти 95% довірчий інтервал для різниці середніх сукупностей.
З результату ми бачимо, що 95% довірчий інтервал для різниці між середніми сукупностями становить [-4,6895 дюйма, -1,1305 дюйма] .
Це говорить нам про те, що ми можемо бути на 95% впевнені, що справжня різниця між середньою висотою рослин виду A та виду B становить від -4,6895 дюйма до -1,1305 дюйма.
Оскільки 0 не входить до цього довірчого інтервалу , це вказує на те, що існує статистично значуща різниця між середніми значеннями двох сукупностей.
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в SAS:
Як виконати одновибірковий t-тест у SAS
Як виконати двовибірковий t-тест у SAS
Як виконати t-тест парних зразків у SAS
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше