Як обчислити ковзне середнє в pandas
Ковзне середнє – це просто середнє значення кількох попередніх періодів у часовому ряду.
Щоб обчислити змінне середнє значення одного або кількох стовпців у pandas DataFrame, ми можемо використати такий синтаксис:
df[' column_name ']. rolling ( rolling_window ). mean ()
Цей підручник містить кілька прикладів практичного використання цієї функції.
Приклад: обчислення ковзного середнього в пандах
Припустімо, що у нас є наступні pandas DataFrame:
import numpy as np import pandas as pd #make this example reproducible n.p. random . seeds (0) #create dataset period = np. arange (1, 101, 1) leads = np. random . uniform (1, 20, 100) sales = 60 + 2*period + np. random . normal (loc=0, scale=.5*period, size=100) df = pd. DataFrame ({' period ': period, ' leads ': leads, ' sales ': sales}) #view first 10 rows df. head (10) period leads sales 0 1 11.427457 61.417425 1 2 14.588598 64.900826 2 3 12.452504 66.698494 3 4 11.352780 64.927513 4 5 9.049441 73.720630 5 6 13.271988 77.687668 6 7 9.314157 78.125728 7 8 17.943687 75.280301 8 9 19.309592 73.181613 9 10 8.285389 85.272259
Ми можемо використати такий синтаксис, щоб створити новий стовпець, що містить ковзне середнє «продажів» за попередні 5 періодів:
#find rolling mean of previous 5 sales periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 0 1 11.427457 61.417425 NaN 1 2 14.588598 64.900826 NaN 2 3 12.452504 66.698494 NaN 3 4 11.352780 64.927513 NaN 4 5 9.049441 73.720630 66.332978 5 6 13.271988 77.687668 69.587026 6 7 9.314157 78.125728 72.232007 7 8 17.943687 75.280301 73.948368 8 9 19.309592 73.181613 75.599188 9 10 8.285389 85.272259 77.909514
Ми можемо вручну перевірити, що ковзне середнє значення продажів, яке відображається за період 5, є середнім за попередні 5 періодів:
Ковзне середнє за період 5: (61,417+64,900+66,698+64,927+73,720)/5 = 66,33
Ми можемо використовувати аналогічний синтаксис для обчислення ковзного середнього кількох стовпців:
#find rolling mean of previous 5 leads periods df[' rolling_leads_5 '] = df[' leads ']. rolling (5). mean () #find rolling mean of previous 5 leads periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 rolling_leads_5 0 1 11.427457 61.417425 NaN NaN 1 2 14.588598 64.900826 NaN NaN 2 3 12.452504 66.698494 NaN NaN 3 4 11.352780 64.927513 NaN NaN 4 5 9.049441 73.720630 66.332978 11.774156 5 6 13.271988 77.687668 69.587026 12.143062 6 7 9.314157 78.125728 72.232007 11.088174 7 8 17.943687 75.280301 73.948368 12.186411 8 9 19.309592 73.181613 75.599188 13.777773 9 10 8.285389 85.272259 77.909514 13.624963
Ми також можемо створити швидкий лінійний графік за допомогою Matplotlib для візуалізації валових продажів у порівнянні зі ковзним середнім показником продажів:
import matplotlib. pyplot as plt
plt. plot (df[' rolling_sales_5 '], label=' Rolling Mean ')
plt. plot (df[' sales '], label=' Raw Data ')
plt. legend ()
plt. ylabel (' Sales ')
plt. xlabel (' Period ')
plt. show ()
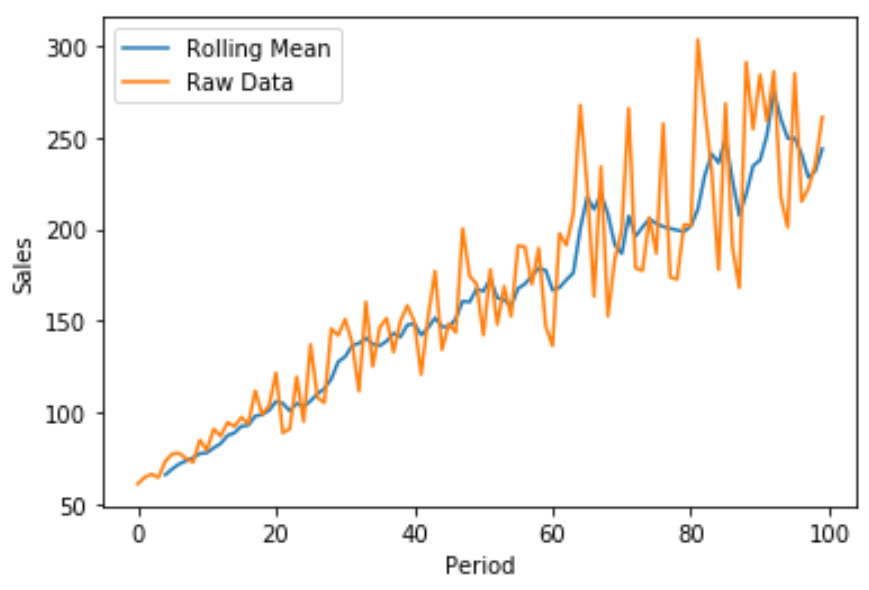
Синя лінія показує 5-періодне ковзне середнє значення продажів, а оранжева лінія показує необроблені дані продажів.
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в pandas:
Як розрахувати ковзну кореляцію в пандах
Як обчислити середнє значення стовпців у Pandas
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше