Як використовувати proc cluster у sas (з прикладом)
Кластеризація – це техніка машинного навчання, яка намагається знайти групи спостережень у наборі даних.
Мета полягає в тому, щоб знайти такі кластери, щоб спостереження всередині кожного кластера були досить подібними одне до одного, тоді як спостереження в різних кластерах сильно відрізнялися одне від одного.
Найпростіший спосіб зробити кластеризацію в SAS — це використовувати PROC CLUSTER .
У наступному прикладі показано, як використовувати PROC CLUSTER на практиці.
Приклад: як використовувати PROC CLUSTER у SAS
Скажімо, у нас є такий набір даних, що містить інформацію про очки, передачі та підбирання для 20 різних баскетболістів:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
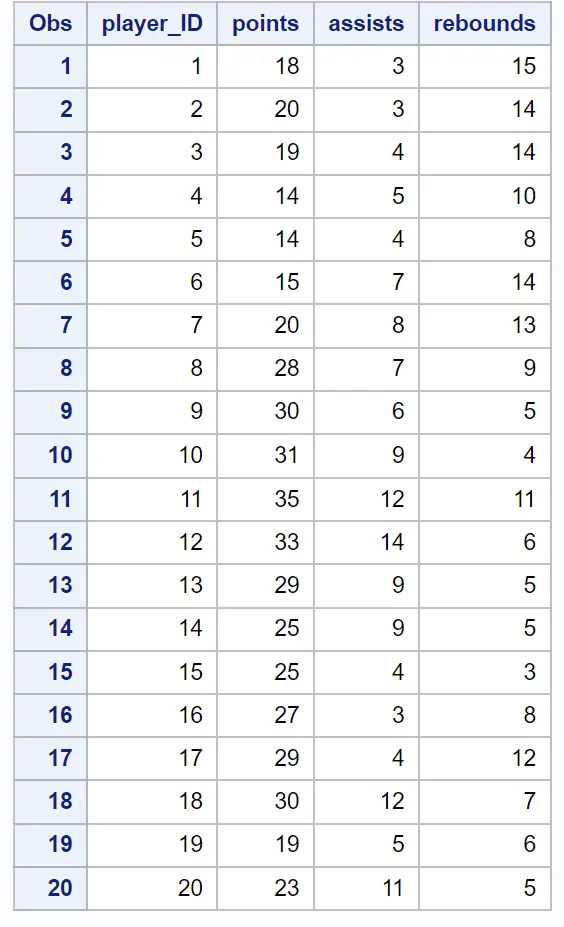
Скажімо, ми хочемо згрупувати, щоб спробувати ідентифікувати «кластери» гравців зі схожими характеристиками один одного.
Наступний код показує, як використовувати PROC CLUSTER у SAS для виконання кластеризації:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
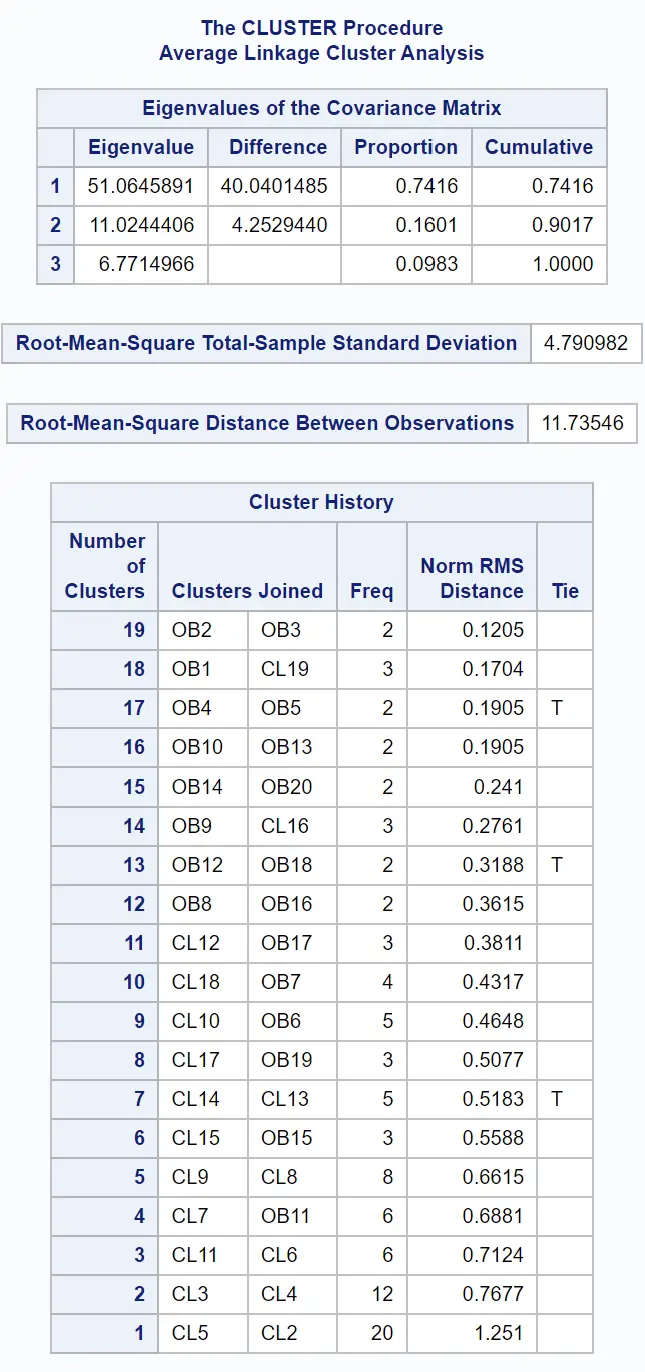
Перші таблиці результату містять інформацію про те, як було здійснено кластеризацію:
Також створюється дендрограма, щоб ми могли візуально перевірити подібність між спостереженнями в наборі даних:
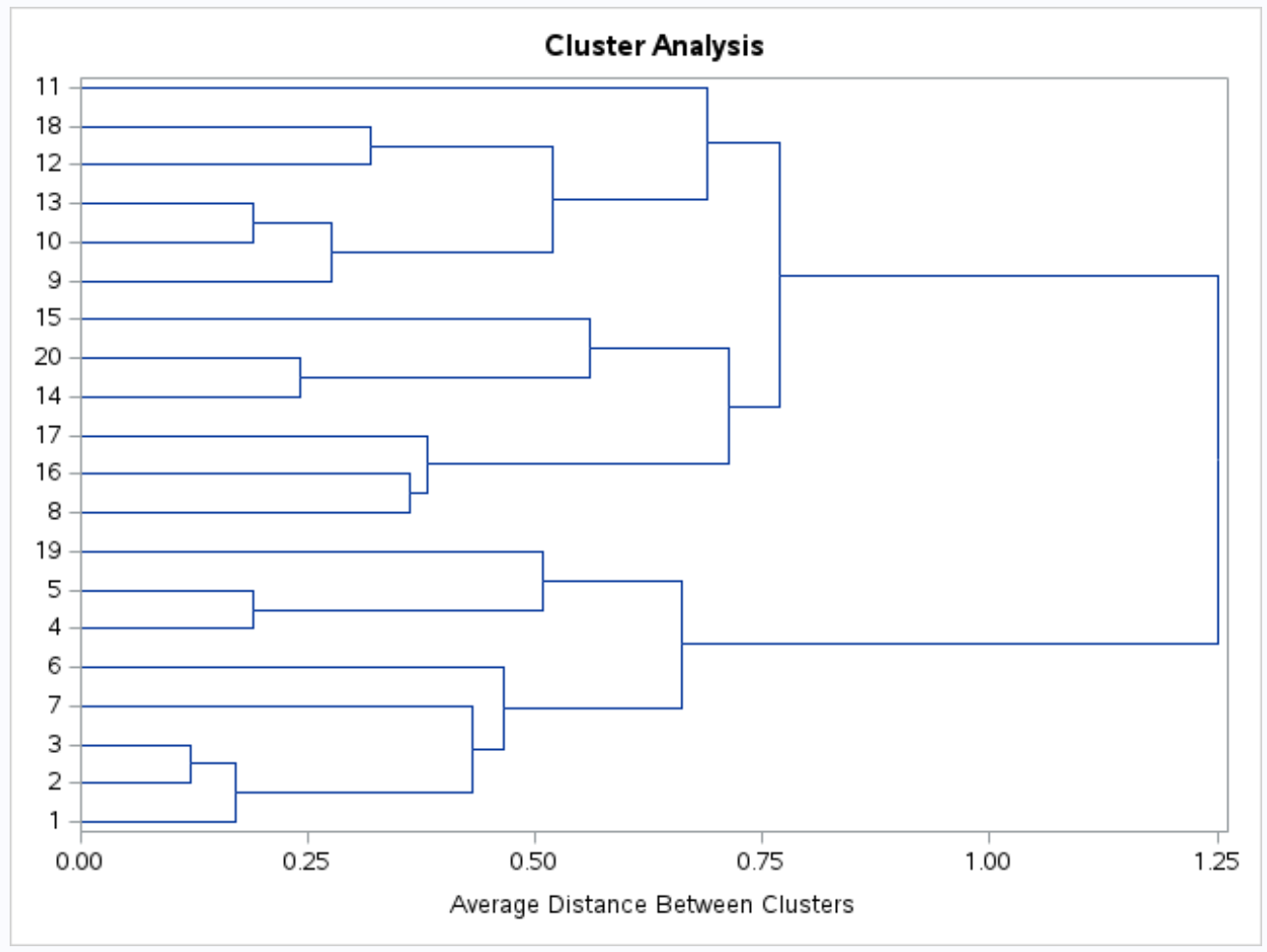
На осі ординат відображаються окремі спостереження, а на осі абсцис – середня відстань між кластерами.
Дивлячись на цю дендрограму, здається, що спостереження природно поділяються на три групи:
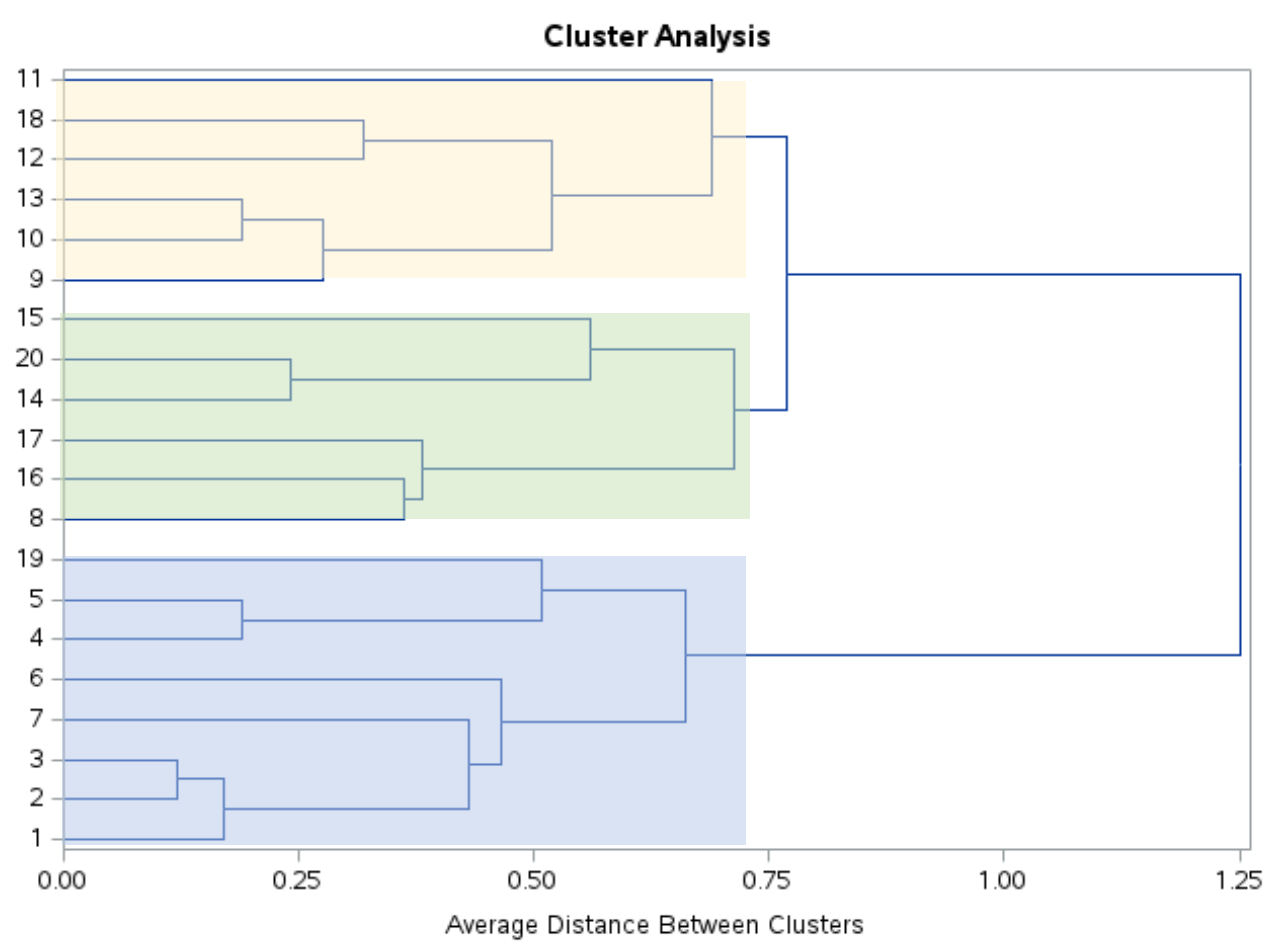
Потім ми можемо використати оператор PROC TREE з ncl=3 , щоб сказати SAS призначити кожне спостереження у вихідному наборі даних одному з трьох кластерів:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
Отриманий набір даних показує кожне з вихідних спостережень разом із кластером, до якого вони належать:
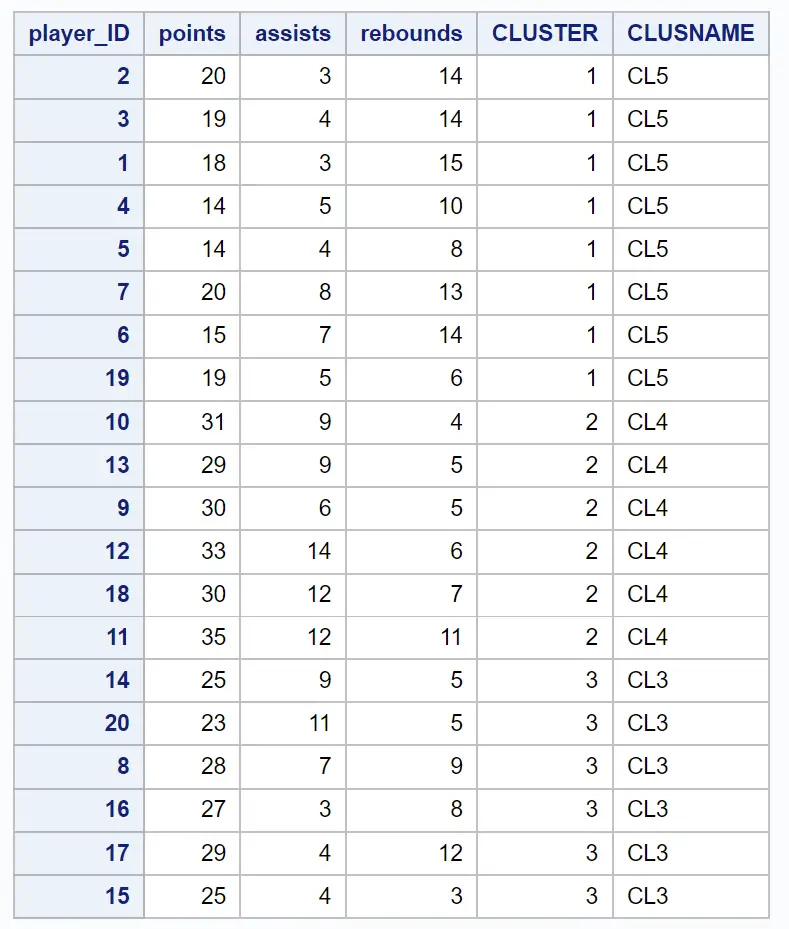
Наприклад, ми бачимо, що всі гравці з ідентифікаторами 2, 3, 1, 4, 5, 7, 6 і 19 належать до кластеру 1 .
Це говорить нам про те, що ці вісім гравців «схожі» за кількістю очок, передач і підбирань.
Примітка . Для цього прикладу ми вирішили використовувати усереднення як метод зв’язування для кластеризації. Зверніться до документації SAS , щоб отримати повний список інших методів зв’язування, які можна використовувати.
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в SAS:
Як виконати аналіз основних компонентів у SAS
Як виконати множинну лінійну регресію в SAS
Як виконати логістичну регресію в SAS
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше